重磅,Meta开源“次世代”大模型Llama 2,扎克伯格:免费可商用
站长之家编辑导读:Meta 发布了一款新的开源大模型 Llama 2,该模型可免费用于研究和商业用途。Llama 2 是 Llama 1 的升级版本,在数据质量、训练技术、能力评估、安全训练和负责任的发布方面有了显著的进步。与 GPT-3 相比,Llama 2 的基础模型更强大,并且微调后的聊天模型可以与 ChatGPT 媲美。扎克伯格在 Facebook 上发表了关于 Llama 2 的声明,称其为大模型的次世代产品。Llama 2 的发布将对大模型生态系统带来重大进展,帮助企业实现定制化和降低成本的产品。此外,Llama 2 还通过与微软合作,提供优化版本,支持 Windows 本地运行。这一发布被认为将改变大模型的市场格局。
声明:本文来自微信公众号“大数据文摘”(ID:BigDataDigest),作者:文摘菌,授权站长之家转载发布。
今日凌晨,就在我们还在睡梦中时,大洋彼岸的Meta干了一件大事:发布免费可商用版本Llama2。

Llama2是Llama1大模型的延续,在数据质量、训练技术、能力评估、安全训练和负责任的发布方面有实质性的技术进步。
在研究共享意愿历史最低,监管困境历史最高点的当今AI时代,Meta这一步无疑为大模型生态系统带来了重大进展。
从技术报告上看,Llama2的基础模型比GPT3更强,而微调后聊天模型则能ChatGPT匹敌。相信后续Llama2将帮助企业实现更多的定制化和降低成本的产品。
以下是扎克伯格在Facebook上发布的关于Llama2的“宣言”,更是将其称之为大模型的次世代的产品:
我们正在与微软合作,推出Llama2,这是我们开源大语言模型的下一代产品。Llama2将免费提供给研究者和商业使用者。
Meta一直投身于开源事业,从领先的机器学习框架PyTorch,到像Segment Anything,ImageBind和Dino这样的模型,再到作为Open Compute Project部分的AI基础设施。我们一直在推进整个行业的进步,构建更好的产品。
开源推动了创新,因为它让更多的开发者能够使用新技术。同时,软件开源,意味着更多的人可以审查它,识别并修复可能的问题,从而提高了安全性。我相信如果生态系统更加开放,将会释放更多的进步,这就是我们为什么要开源Llama2。
今天,我们发布了预训练和微调的模型Llama2,参数分别为70亿,130亿和700亿。Llama2比Llama1预训练的数据多40%,并对其架构进行了改进。对于微调模型,我们收集了超百万的人类注释样本,并应用了有监督的微调和RLHF,在安全性和质量方面是领先的。
你可以直接下载这些模型,或者通过Azure以及微软的安全和内容工具访问这些模型。我们还提供一个优化版本,支持Windows本地运行。
我非常期待看到你们的创新成果!
对于Llama2的出现和发布,深度学习三巨头之一的Yann LeCun表示,这将改变大模型的市场格局。

有网友很快就向Meta发送了申请,并在几个小时内获得了许可,已经在应用了:
OpenLLM大模型排行榜对Llama2进行了关于“Eleuther AI Language Model Evaluation Harness” 中的4个关键基准的评估:

其中,Llama-2-70b获得了平均分、科学问题ARC、常识推理HellaSwag等指标的第一名;文本多任务准确性MMLU指标被基于Llama-30B 的微调模型Platypus-30B超过;生成问题答案真实性TruthfulQA (MC)指标位列第8名。
论文地址:
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
项目地址:
https://github.com/facebookresearch/llama
Llama2的一些关键点aw的优势在哪?
Meta发布了多个模型,包括7亿,13亿,34亿,70亿参数的Llama基础模型,以及同等规模的Llama变体。Meta将预训练语料库的大小增加了40%,将模型的上下文长度增加了一倍,并采用了分组查询注意力机制(grouped-query attention)。
具体而言,有以下几个关键点:
能力:广泛测试后,在非编码方面,确定这是第一个能达到ChatGPT水平的开源模型。
代码/数学/推理:论文中关于代码数据的讨论较少,但有一个模型在某些评价中超越了其他模型。
多轮一致性:采用了新的方法,Ghost Attention (GAtt),以改善模型的多轮对话一致性。
奖励模型:为避免安全性和有用性的权衡,采用了两个奖励模型。
RLHF过程:采用了两阶段的RLHF方法,强调了RLHF对模型写作能力的重要影响。
安全性/伤害评估:进行了详尽的安全评估,并采用了特定的方法以增强模型的安全性。
许可证:模型可供商业使用,但有一定的用户数量限制,也即日活大于7亿的产品需要单独申请商用权限。
Llama2的技术细节
Huggingface科学家Nathan Lambert在一篇博客也对Llama2的技术报告进行了解析。
这个模型(Llama2)与原始的Llama在结构上相似,主要的改变在于数据和训练过程,以及增加了上下文长度和分组查询注意力(GQA),且在聊天功能的应用性和推理速度方面有所提高。
训练语料库来自公开资源,不包含Meta的产品或服务的数据。模型在2万亿个数据标记(Token)上训练,以提高性能并减少错误,并尽力删除含有大量私人信息的数据。
论文大部分关于评估和微调,而非创建基础模型。
论文接着遵循RLHF流程,训练一个奖励模型并使用强化学习(RL)进行优化。
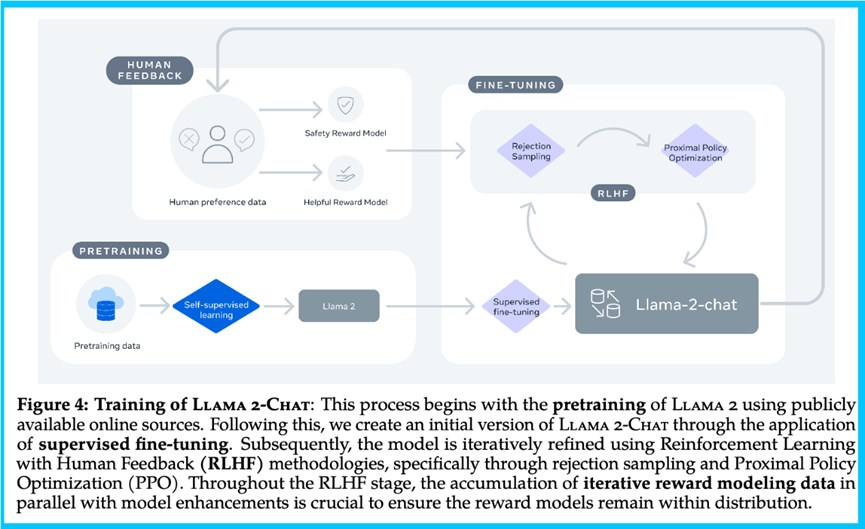
此外,技术报告也证实了一点,奖励模型是RLHF的关键,也是模型的关键。为了得到一个好的奖励模型,Meta收集了大量偏好数据,这些数据远远超过了开源社区正在使用的数据。
Meta收集二元对比数据,而非其他更复杂类型的反馈。这类似于1-8的Likert量表,但更侧重于质性评价如“显著优于、优于、稍优于或差不多/不确定”。
他们使用多轮次偏好,模型的响应来自不同的模型训练阶段;Meta的关注点更在于有用性和安全性,而不是诚实度(honesty),在每个数据供应商的数据收集阶段使用不同的指令。
此外,在数据收集过程中,团队添加了额外的安全元数据,显示每一轮模型的哪些响应是安全的。在建模阶段,他们排除了所有“选择的响应不安全而其他响应安全”的例子,因为他们认为更安全的响应会更受人类喜欢。
奖励模型
研究人员训练了两个奖励模型,一个专注于有益性,另一个专注于安全性。这些模型基于语言模型构建,用线性回归层替换了原模型头部。他们始终使用最新的聊天模型,目的是为了减少在RLHF训练中的分布不匹配。
一些关键的技术细节包括:
起始奖励模型基于开源数据训练,并用于生成早期供应商数据。
他们保留了一些Anthropic的无害数据(占他们自己的90%),但没有给出具体原因。
他们只训练一个epoch,防止奖励模型过拟合。
奖励模型的平均准确率在65-70%范围内,但在"显著不同"的标签上,准确率达到80-90%。
其他有趣的发现:
在奖励模型的损失函数中添加了一个margin项(与偏好的置信度成比例),以提高有益性。
随着模型的训练和改进,数据对模型输出的一致性评价越来越高
训练的奖励模型在评估中表现优于使用GPT-4生成的奖励模型提示。
图表显示,奖励模型的准确性随着时间的推移有所提高。值得注意的是,尽管OpenAssistant奖励模型可能没有得到高度认可,但是GPT-4作为奖励模型的性能表现为其他模型提供了基准。
Meta在讨论微调结果时提到,奖励模型的准确性是Llama2-Chat性能的关键指标。这符合人们对RLHF会充分利用奖励模型知识的理解。
RLHF和微调
Meta通过使用RLHF方法来提升模型性能,如下图所示使用最优秀的奖励模型来评估各种模型,以此展示RLHF如何将生成的文本推向更高的奖励。Meta迭代训练了5个RLHF版本,每个版本的数据分布都有所改进。

Meta指出,第三方的SFT(有监督微调)数据多样性和质量往往不足以满足对话式指令的LLM对齐需求。Meta通过筛选第三方数据集中的高质量示例,显著提高了结果。他们也强调了注释数据的数量对于再现性的重要性。
Meta观察到,不同的注释平台和供应商可能会导致模型性能的显著差异,因此在使用供应商获取注释时,数据检查仍然非常重要。他们的做法是通过对比人类注释和模型生成的样本来验证数据质量。
在数据质量确立之后,Meta开始关注强化学习(RL)部分。他们发现,即使有熟练的注释员,每个人的写作风格也会有很大的差异。一个在SFT注释上进行微调的模型会学习这种多样性,但同时也会学习到一些糟糕的注释。他们指出,模型的性能是由技巧最好的注释者的写作能力来限制的。
Meta确实承认,这个过程需要大量的计算和注释资源。在整个RLHF阶段,奖励建模数据对于模型改进至关重要。
结论是,有效的RLHF需要一个中等大小的团队。虽然一个1-3人的团队可以发布一个好的指令模型,但实行RLHF可能需要至少6-10人。这个数字会随着时间的推移而减小,但这种类型的工作需要与外部公司签订合同和保持紧密的联系,这总是会耗费一些时间。
此外,Meta对比了方法间的基本差异以及它们的使用时机:
拒绝抽样(RS)进行更广泛的搜索(每个提示生成更多的数据),而PPO则对奖励模型进行更多的更新。
最终方法之间的差异并不显著(与WebGPT的发现相似)。
在RLHFV4中,仅使用了拒绝抽样,然后在最后一步中使用PPO和拒绝抽样进行微调(在一些评估中,PPO有轻微的优势)。
评估
论文以多种方式评估他们的模型。在自动化基准测试中,例如Open LLM Leaderboard(MMLU,ARC等)的首字母缩略词,Llama2在所有规模上都比其他任何开源模型要好得多。
模型在诸如MMLU这样的不那么显眼的基准测试中也得分更高,这是因为他们的大量数据工作和RLHF的调整。然而,他们的模型在与闭源模型的比较中并未表现出色。
此外,论文还深入研究了当前流行的评估技术,人类注释者和LLM-as-a-judge由于其普遍性和可用性而受到欢迎。尽管人类评估可能受到一些限制和主观性的影响,但结果显示了Meta在开源领域的主导地位。

他们采用了模型作为评判的技术,并用Elo图展示了RLHF这个随时间变化的概念,这与Anthropic的AI工作类似。在性能上,他们的模型在RLHFv3之后超过了ChatGPT,这可以在图中看到PPO方法提供了一定的提升:
这篇论文进行了多项评估以展示其一般性能力,包括建立奖励模型。奖励模型的测试亮点:
调整奖励模型分数以适应人类评价者的偏好评估,尽管误差范围较大。
与在开源数据集上训练的奖励模型进行比较,以展示开源领域的可能实现。
人类/模型评估的亮点:
在ChatGPT和Llama-2-Chat的输出上评估模型,避免模型因风格偏好而提高自身结果。
利用评价者间可靠性度量,如Gwet的AC1/2,这些统计工具为此项工作专门设计。
承认人类评估的限制,包括大型评估提示集未覆盖所有实际应用,缺少对编码/推理的评估,只评估最后的对话轮次。
最后,附上Llama2的在线测试地址:
https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI?continueFlag=749dd0fc30bb1d0718aaa9576af51980
参考文献
https://twitter.com/i/status/1681354211328507917
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
https://www.interconnects.ai/p/llama-2-from-meta?utm_source=profile&utm_medium=reader2
AI Score My Site:AI驱动的SEO工具
AIScoreMySite是一款创新的工具,旨在帮助用户了解他们的网站在AI驱动的搜索引擎上的排名和可发现性,并提供相应的改进建议。在今天的数字化时代,网站的排名对于吸引流量和潜在客户至关重要。然而,传统的搜索引擎优化方法可能不足以适应AI技术的发展。AIScoreMySite填补了这一空白,通过评分和建议,让用户的网站在AI驱动的搜索引擎中更具竞争力。站长网2023-09-20 11:32:310000OpenAI、DeepMind 和 Anthropic 等顶级 AI 公司 CEO 签署防范人工智能风险联名信
OpenAI首席执行官SamAltman等顶级人工智能领域的高管于周二加入了专家和教授的行列,提出了「人工智能灭绝风险」的问题,并敦促政策制定者将其与大流行病和核战等风险等同对待。超过350名签署者在非营利组织人工智能安全中心(CAIS)发布的一封信中写道:「减轻人工智能灭绝风险应当与大流行病和核战等其他社会规模的风险一样成为全球优先事项。」站长网2023-05-31 09:50:150000刚刚,谷歌弃Bard发布超大杯Gemini,全面对标GPT-4,前2个月免费!
就在刚刚,谷歌深夜搞了个大动作——Bard现在统称Gemini。发布GeminiAdvanced,由谷歌最强多模态大模型GeminiUltra1.0支持!为了防止概念混淆,我们拿OpenAI家的大模型来对比理解:Gemini是品牌总称,相当于OpenAI的ChatGPT;GeminiAdvanced付费服务,对应ChatGPTPlus;站长网2024-02-09 13:54:000000YouTube Music 开始进行创建播放列表封面的生成式 AI 测试
站长之家(ChinaZ.com)10月26日消息:YouTubeMusic近日在美国地区启动了一项新的生成式人工智能测试,使用户能够为其播放列表创建艺术封面。此次测试体现了YouTube对音乐领域生成式AI的探索,同时也为用户提供了更丰富的个性化体验。图片来自YouTube站长网2023-10-26 12:06:160001罗永浩直播谈董宇辉事件:1%,东方甄选给的太少了
12月16日午间,东方甄选迎来了“二选一”的大结局。东方甄选公告称,免去孙东旭东方甄选执行董事、CEO职务,董事长俞敏洪兼任东方甄选CEO职务。0001