这个新方法有点牛,无需数据训练就能改善Stable Diffusion
站长网2023-07-18 00:04:361阅
受到大型语言模型的微调的启发,研究人员现在正试图使用强化学习来微调生成AI模型以实现特定目标,例如提高图像的美学质量,从而干预这一过程。
最近,伯克利人工智能研究中心(BAIR)的研究人员使用强化学习来进一步优化生成式人工智能模型用于改善图像生成的效果。
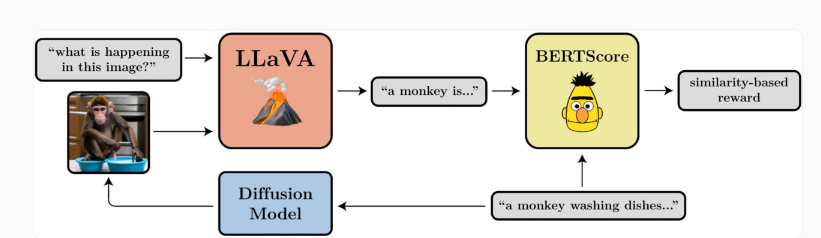
通过测试,他们发现去噪扩散策略优化(DDPO)在优化图像的压缩性、不可压缩性、美学质量和提示图像对齐方面表现出了有效性。
在他们的测试中,该团队表明DDPO可以有效地用于优化四个任务。此外,它们还显示出一定的可推广性:例如,对45种常见动物物种进行了美学质量或提示图像对齐的优化,但也可以转移到其他动物物种或无生命物体的表示上。

这种方法不需要训练数据,为基于人工智能的图像合成开辟了新的可能性,但仍需要进一步探索。
与强化学习中常见的一样,DDPO也表现出奖励过度优化的现象:该模型在某个节点之后破坏所有任务中所有有意义的图像内容,这个问题需要在进一步的工作中进行调查。
0001
评论列表
共(0)条相关推荐
MagicGPT即将到来?荣耀持续发力AI大模型行业
凤凰网科技讯9月4日,据天眼查App显示,近日,荣耀终端有限公司申请两枚“MagicGPT”商标,国际分类为网站服务、科学仪器,当前商标状态均为申请中。图源天眼查值得一提的是,不久前,该公司已申请科学仪器类“MagicAI”商标,当前商标状态也为申请中。图源天眼查站长网2023-09-04 21:39:490000北京出台机器人新政 支持开发机器人强化AI大模型支撑
6月28日,北京市人民政府办公厅印发《北京市机器人产业创新发展行动方案(2023—2025年)》,对人形机器人等细分产业的发展制定了目标和行动细则。站长网2023-06-30 23:54:070001苹果与诺基亚续约 继续使用5500多项5G专利
诺基亚和苹果公司今天发布联合声明,宣布双方续签了一项长期专利许可协议。根据这项协议,苹果将继续使用诺基亚在5G和其他技术方面的专利发明。此前的协议将于2023年到期,而新的协议并未透露具体的交易细节。诺基亚拥有超过20000项专利,其中包括5500项与5G相关的专利。这些专利被认为是现代5G设备所必需的。站长网2023-07-02 10:12:380000华为手机回来了!曝麒麟芯片回归:首发机型成悬念
快科技7月24日消息,由于众所周知的原因,在Mate40系列之后,华为新机基本都是骁龙芯片,自家麒麟芯片几乎绝版”,只有偶尔在官方部分翻新机上才能看见老款麒麟芯片的身影。麒麟芯片无法迭代,对华为手机业务确实造成了一些影响,不过,情况似乎在慢慢好起来,麒麟芯片或将重出江湖。今日,数码博主数码闲聊站”发文称麒麟芯片回归”,虽然该博主没有再透露更详细的内容,但对消费者来说,这已经是个重磅的好消息。站长网2023-07-25 12:20:400001专家警告!AI约会工具LoveGPT或存在利用GPT虚构身份
要点:Avast网络安全专家警告LoveGPT,一款旨在进行在线约会的AI工具,可用于自动化虚假身份欺诈,诱使受害者泄露敏感信息,如信用卡详细信息。LoveGPT使用OpenAI的GPT语言模型创建令人信服的虚假档案和更真实的对话,使骗子能够在各种约会平台上扩大攻击规模。Avast建议在线约会时保持谨慎,建议用户不要信任新的在线联系人,即使他们看起来很真实,因为可能存在由AI驱动的虚假身份。站长网2023-10-10 09:58:580000