Meta重新定义多模态!北大校友共同一作,70亿参数文生图模型击败Diffusion
【新智元导读】北大校友共同一作,Meta发布史上首个单一多模态模型!7B模型击败Diffusion,完美画手难题完美解决。
Meta又来炸场了!
就在刚刚,Meta推出了一个基于Transformer的多模态模型——CM3leon,在文生图和图像理解领域都取得了绝对的突破,堪称同类最佳。
而且,这种将多模态组合成单一模型,在此前公开的AI系统中是前所未有的。

显然,Meta的这项研究,为多模态AI定义了一个全新的标准,预示着AI系统完全可以在理解、编辑、生成图像、视频、文本这些任务上自由切换。
同时,CM3leon的推出,正式标志着自回归模型首次在关键基准上,与领先的生成扩散模型的性能相媲美。

论文地址:https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
此前,文生图领域最受瞩目的三大明星模型,是Stable Diffusion,DALL-E和Midjourney。而文生图技术基本上都是依赖于扩散模型。
但CM3leon的革命性意义在于:它使用的是完全不同的技术——基于tokenizer的自回归模型。
结果表面,基于tokenizer的自回归模型不仅比基于扩散模型的方法更有效,在文生图领域实现了SOTA,而且训练的计算量还比此前基于Transformer的方法少了五倍!

01
准备好,一大波酷炫效果来袭
光看原始性能指标,还说明不了什么。
CM3leon真正惊艳的地方,在于处理更复杂的提示和图像编辑任务。
准确渲染图像,效果惊人
比如,它可以从提示中准确渲染图像,例如「撒哈拉沙漠中戴着草帽和霓虹灯太阳镜的小仙人掌」。

任意prompt,随心所欲编辑图像
CM3leon还有一个独特的功能——根据任意格式的文本指令对现有图像进行编辑,比如更改天空颜色,或者在特定位置添加对象。
上面这些功能,远远超越了DALL-E2等模型所能达到的效果。

前所未有的多模态单一模型
CM3leon的多功能架构,让它能够在文本、图像和构图任务之间流畅地自由转换。
除了文生图的功能,CM3leon还可以为图像生成标注、回答有关图像内容的问题,甚至可以根据边界框和分割图的文本描述创建图像。
这种将模态组合成单一模型的情况,在此前在公开披露的AI系统中是前所未有的。
prompt:狗叼着什么?模型回答:棍子。
prompt:详细描述给定图像。模型回答:这张图像中,一只狗嘴里叼着一根棍子。地面上有草。图像的背景中有树。

给定图像边界框分割的文本描述,说明在图像的哪个地方需要一个水池、需要一个镜子,CM3leon就可以完全按prompt生成对应图像。

超高分辨率
一个单独的超分辨率平台可以与CM3leon输出集成,从而显著提高分辨率和细节。
输入prompt「湖中央的圆形小岛,湖周围有森林,高对比度」——

解决AI画手难题
连AI不会画手的老大难问题,都被CM3leon轻松解决了。

02
自回归模型首次击败Diffusion?
在近年来大热的文生图领域,Midjourney,DALL-E2和Stable Diffusion使用的都是扩散技术。
虽然Diffusion技术产生的结果很惊艳,但由于它是计算密集型的,这使得它的计算强度很大,运行成本很高,而且往往缺乏实时应用所需的速度。
有趣的是,OpenAI几年前曾想通过名为Image GPT的模型,来探索了Transformer作为图像生成的可能性。但它最终放弃了这个想法,转而支持Diffusion。
而CM3leon采用的是完全不同的方法。作为基于Transformer的模型,它利用注意力机制来权衡输入数据(无论是文本还是图像)的相关性。
这种架构的差异,使得CM3leon能够实现更快的训练速度和更好的并行化,因而比传统的基于扩散的方法更有效。
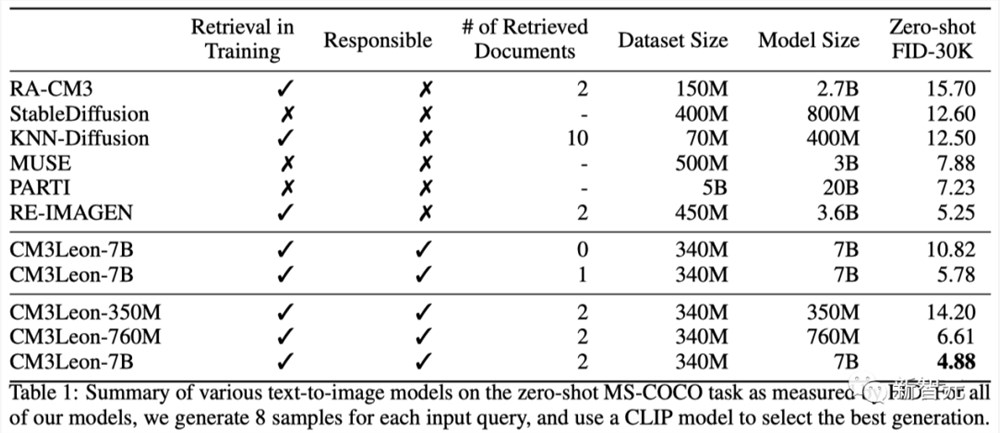
仅用单个TPU,CM3leon就在图像数据集上进行了有效的训练,并在MS-COCO数据集上达到了4.88的FID分数,超过了Google的文本到图像模型Parti。
与此同时,CM3leon的效率更是同类Transformer架构的5倍以上。
CM3leon之所以如此成功,可以归功于它独特的架构和训练方法。
它强大性能的一个关键,就是监督微调的技术(SFT)。
此前,SFT已被用于训练像ChatGPT这样的文本生成模型,效果很好,但Meta认为,应用于图像领域时,它也很有用。
事实上,指令微调不仅提高了CM3Leon在图像生成方面的性能,而且提高了图像标注编写的性能,使其能够回答有关图像的问题并通过遵循文本指令(例如「将天空的颜色更改为亮蓝色」)来编辑图像。
CM3leon仅采用解码器转换器体系结构,类似于已建立的基于文本的模型,但增加了处理文本和图像的功能。
训练过程涉及检索增强,以及跨越各种图像和文本生成任务的指令微调。
通过应用跨模态的监督微调技术,Meta显著提高了CM3leon在图像标注、视觉QA和文本编辑方面的性能。
尽管CM3leon只在30亿个文本token上进行了训练,但它与在多达1000亿个token上训练的其他模型的结果相当,甚至实现了超越。
作为第一个采用与文本语言模型相似的方法进行调整的多模态模型,Meta在CM3leon中加入了一个大规模的检索增强预训练阶段和一个第二个多任务的监督微调(SFT)阶段。
03
CM3leon表现如何
凭借CM3leon的能力,图像生成工具可以产生更一致的图像,更好地遵循输入提示。
以下是CM3leon在各种任务中的能力展示,所有任务均由单个模型完成:
文本到图像生成
基于文本的图像编辑(例如,「将天空的颜色改为明亮蓝色」)很具挑战性,因为它要求模型能够同时理解文本指令和视觉内容。
尤其是,当涉及复杂对象或提示包含多个必须在输出中出现的约束条件时。
根据具有高度组合结构的提示文本,CM3leon可以生成一个指令跟随的图像。

(1) 在撒哈拉沙漠中戴着稻草帽和霓虹太阳镜的小仙人掌
(2) 一只人手的特写
(3) 在动漫中准备使用武士刀参加一场史诗级战斗的浣熊主角
(4) 以幻想风格呈现的停车标志,上面写着「1991」
基于文本的图像编辑
给定一张图像和一个文本提示,CM3leon可以根据文本中的指令对图像进行编辑。
由于CM3leon模型的通用性,与其他的任务一样,这是通过同一个模型实现的,而不像以前的模型(如InstructPix2Pix)只针对基于文本的图像编辑进行微调。

同时,CM3leon模型还可以根据一系列不同的提示来生成简短或长篇描述,并回答关于图像的问题。
举个栗子。
- 提示:
问题:这两个物体有什么共同点?
上下文:选择最佳答案。
选项:(A)闪的(B)咸的
回答:让我们逐步思考:
- CM3Leon输出:
思考每个物体。薯片有咸味。椒盐脆饼是咸的。所以答案是(B)。

- 提示:
详细描述给定图像中的所有物体。
- CM3Leon输出:
一个街道标志位于金属杆上。标志是蓝色的,上面有白色的文字。杆上有一个红灯。天空是明亮的蓝色。街道上停着车。街道两侧有树木。街道两侧有建筑物。

同样,对于下面这些「看图问答」,CM3leon都能轻松拿捏。

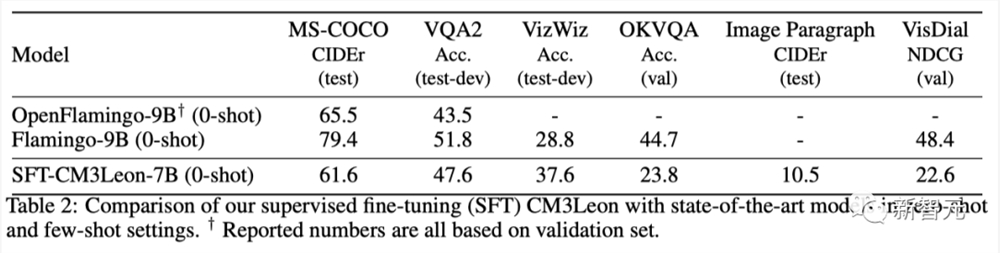
为了进一步了解CM3leon,Meta在图像描述生成和视觉问答任务中,对指令微调模型进行了实证评估,并将它们与先前的SOTA基准进行了比较。
相比于Flamingo(100B)和OpenFlamingo(40B),CM3leon模型的文本数据明显较少(约3B个token)。
但在MS-COCO图片描述和VQA2问答方面,CM3leon却实现了与零样本OpenFlamingo相同的性能,甚至在VizWiz任务上击败了Flamingo近10个百分点。
结构引导的图像编辑
结构引导的图像编辑旨在理解和解释提供的文本指令以及结构或布局信息。
从而让CM3leon模型能够在遵循给定的结构或布局指令的同时,创建视觉上一致和语境恰当的图像编辑。
在只包含分割的图像(没有文本类别)中,生成一张图像。这里的输入表示从中提取分割的图像。

超分辨率
除此之外,图像生成领域还有一个常见的技巧——利用经过单独训练的超分辨率阶段,从原始模型输出生成更高分辨率的图像。
对于这类文本到图像生成任务,CM3leon表现得也非常好。

(1)一杯热气腾腾的咖啡,背景是群山,在旅途中休息
(2)日落时分,美丽而雄伟的公路
(3)湖中心的圆形小岛,湖边环绕着森林
以及一些「奇幻」风格的生成。

(1)海龟在水下游泳
(2)大象在水下游泳
(2)一群羊
04
如何构建CM3Leon
架构
在架构方面,CM3Leon采用了一个和成熟的文本模型相似的仅解码器Transformer。
但不同的是,CM3Leon能够输入和生成文本和图像。
训练
通过采用论文「Retrieval-Augmented Multimodal Language Modeling」中提出的训练检索增强技术,Meta大大提高了CM3Leon模型的效率和可控性。
同时,Meta还在各种不同的图像和文本生成任务上,对CM3Leon模型进行了指令微调。
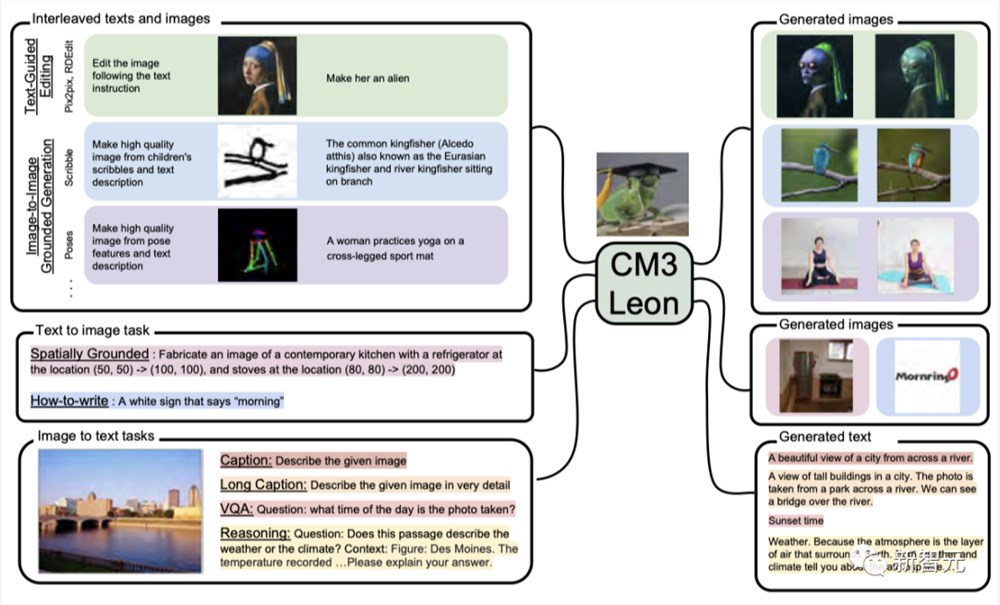
左侧:各种任务的常见输入;右侧:相应的模型输出。
在训练过程中,Meta将模型输入和输出连接起来,并使用与预训练阶段相同的目标进行训练。
随着人工智能行业的不断发展,像CM3Leon这样的生成模型变得越来越复杂。
这些模型通过对数百万个示例图像进行训练来学习视觉和文本之间的关系,但它们也可能反映出训练数据中存在的偏见。
因此,Meta采用了有许可的数据集对CM3Leon进行训练。
而结果也证明,虽然数据的分布与先前的模型截然不同,但CM3Leon仍然实现了强大的性能。
对此,Meta希望,通过大家的共同努力,可以创建更准确、更公正、更公平的模型。
05
为多模态语言模型铺平道路
总的来说,Meta认为,CM3Leon在各种任务上的出色性能,是朝着更真实的图像生成和理解迈出的重要一步。
而这样的模型,最终可以帮助提升创造力并在元宇宙中实现更好的应用。
06
作者介绍
Lili Yu、Bowen Shi和Ramakanth Pasunuru为论文共同一作。
其中,作Lili Yu取得了北大物理系的学士学位,以及MIT电子工程和计算机科学的博士学位。

参考资料:
https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
https://www.maginative.com/article/meta-unveils-cm3leon-a-breakthrough-ai-model-for-advanced-text-to-image-generation-and-image-understanding/
https://techcrunch.com/2023/07/14/meta-generative-transformer-art-model/
致20颗星链卫星损毁 SpaceX猎鹰9号7年首次发射失败:马斯克回应了
快科技7月13日消息,当地时间本周五,SpaceX的主力火箭猎鹰9号”被美国联邦航空管理局(FAA)停飞,之所以如此,是因为前一天晚上发生了发射失败的案例。当地时间周四晚间,猎鹰9号从加州范登堡太空部队基地发射升空,约一个小时后,火箭的第二级未能重新点燃,导致携带的20颗星联卫星坠入地球大气层并烧毁。据悉,猎鹰9号是全球航天工业所依赖的火箭,这是它在7年多时间里首次遭遇发射失败。0000印度创企Sarvam AI融资4100万美元 聚焦本土语言生成模型
**划重点:**1.💰SarvamAI宣布完成4100万美元的融资,由Lightspeed、KhoslaVentures和PeakXV领投。2.🗣创立于五个月前的孟买初创公司致力于构建支持印度语言的大型语言模型,并着眼于使用语音作为印度市场的默认界面。3.🌐Sarvam计划推出首个模型,致力于满足印度市场需求,成为印度在全球AI领域崭露头角的公司之一。0000抖音医疗新规11月1日生效:严打借同质化等虚假内容导流获利
抖音集团近日发布了针对医疗内容的新规,旨在严厉打击平台上的虚假医疗信息和违规导流获利行为。新规定明确禁止创作者发布虚假医疗信息,夸大或虚构医疗水平,以及通过打造“神医”“名医”等虚假人设诱导欺骗用户。此外,新规还禁止利用热点医疗事件进行不当营销,要求创作者在引用热点事件或案例时必须明确标注信息来源,避免误导。站长网2024-09-12 03:53:020000阿里巴巴发布2024财年Q4及全年业绩:全年收入9411.68亿元 六大核心业务谁最赚钱
快科技5月14日消息,今日,阿里巴巴发布了截至3月31日的2024财年第四财季及全年财报。财报显示,阿里巴巴集团Q4收入2218.74亿元,同比增长7%。2024财年,阿里巴巴集团收入达9411.68亿元,同比增长8%。注:阿里巴巴财年与自然年不同步,2023财年4月1日至2024年3月31日为2024财年0001特斯拉Cyberquad玩具车今日开售 售价11990元
特斯拉中国官网今天上午10点正式上线销售Cyberquad玩具车,这款玩具车的灵感来自于特斯拉标志性的Cybertruck设计语言,具有锂离子电池供电、续航里程可达13公里、最高时速为8km/h等特点,适合8-12岁的儿童使用。站长网2023-07-14 16:20:410000