谷歌受到诉讼 指控窃取了数百万用户的数据来训练人工智能工具
据CNN报道,周二,科技巨头谷歌遭到了一场诉讼,指控该公司未经数百万用户同意就窃取了他们的数据,并违反了版权法,起诉谷歌使用这些数据来训练和开发其人工智能产品。

这项针对谷歌、其母公司Alphabet和谷歌的人工智能子公司DeepMind的集体诉讼案于周二在加利福尼亚州的一家联邦法院提起,由Clarkson Law Firm发起。该律所上个月曾对ChatGPT制造商OpenAI提起过类似的诉讼。(OpenAI之前没有回应对该诉讼的评论请求。)
诉状指控,谷歌一直在秘密地窃取美国数亿人在互联网上创作和分享的一切,并利用这些数据来培训其人工智能产品,比如它的聊天机器人Bard。诉状还声称,谷歌窃取了“我们数字足迹的几乎全部”,包括“创意和受版权保护的作品”,以建立其人工智能产品。
CNN向谷歌发表声明的总法律顾问哈利玛·德莱恩·普拉多(Halimah DeLaine Prado)称,诉讼中的指控“毫无根据”。德莱恩·普拉多说:“多年来我们一直明确表示,我们使用来自公共来源的信息——比如公开网上发布的信息和公共数据集——来培训提供谷歌翻译等服务背后的人工智能模型,这是负责任的,并符合我们的人工智能原则。”
“美国法律支持使用公共信息来创造新的有益用途,我们期待驳斥这些毫无根据的指控,”声明补充道。
Alphabet和DeepMind没有立即回应评论请求。
诉状指出了谷歌最近对其隐私政策的更新,明确表示该公司可能使用公开可获取的信息来培训其人工智能模型和工具,比如Bard。
针对之前Verge关于更新的报道,该公司表示其政策“一直透明地表明,谷歌使用来自开放网络的公开可获取信息来培训提供谷歌翻译等服务背后的语言模型。这次最新更新只是澄清了像Bard这样的新服务也被包括在内。”
代表原告的律师在周二接受CNN采访时表示,“谷歌需要明白‘公开可获取’从来不意味着可以免费用于任何目的。”“我们的个人信息和数据是我们的财产,它是有价值的,没有人有权只是拿走它并用于任何目的。”
该诉讼要求以暂时冻结对谷歌的生成式人工智能工具(如Bard)的商业访问和商业开发的形式,寻求禁令。它还要求未确定的赔偿,作为对谷歌据称侵占的数据的人的经济补偿。该律所表示,它已经找到了八名原告,其中包括两名未成年人。
Giordano将谷歌通常如何索引在线数据以支持其核心搜索引擎与新的指控它刮取数据来训练人工智能工具进行了对比。
AI日报:前百度高管推AI搜索产品Genspark;Kimi内测上下文缓存功能;TikTok推AI全家桶Symphony;橙篇已支持10万字长文生成
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、前百度高管景鲲创业AI搜索估值18亿推出首款产品Genspark站长网2024-06-22 11:45:380001AI 之父称 AI 将很快超越人类智能,担心发展不安全
划重点:-🤖AI之父GeoffreyHinton担心AI的发展不够安全,并表示AI很快将超越人类智能。-🌍大多数AI领域的专家都认同AI将超越人类智能的观点。-💥Hinton担心军事应用领域可能带来的潜在威胁,呼吁政府加强对AI的监管。站长网2024-05-21 21:10:530000QQ浏览器推出“PDF阅读助手”AI工具 由腾讯混元大模型支持
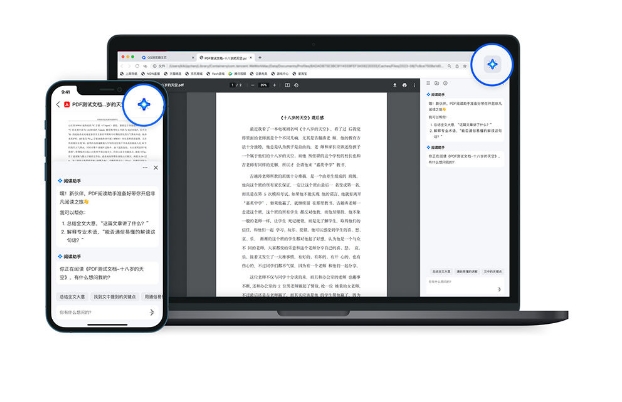
近日,QQ浏览器推出了一款名为“PDF阅读助手”的智能工具,用户可以申请加入体验测试。该工具由腾讯混元大模型支持,可以在手机或电脑上随时使用。“PDF阅读助手”具有以下特点:首先,它支持智能摘要功能,用户不再需要逐页阅读长篇文档。通过一键操作,该助手可以迅速为您提炼出重要信息,大大节省了阅读时间。站长网2023-10-13 08:41:140000独家|抖音外卖再调整:上线随心团,到家到店统一入口
Tech星球独家获悉,抖音外卖业务从电商部门回归生活服务部门后,对原有的外卖经营方式进行调整,将原团购配送业务升级为“随心团”业务,即同一件团购商品既支持用户到店核销,也支持配送到家。原“团购配送”业务将于2024年11月1日起逐步向”随心团“业务迁移。0000游戏史上最大收购落定!微软计划下周五完成与动视暴雪的巨额交易
快科技10月6日消息,据TheVerge最新报道,微软计划在下周五之前完成以687亿美元收购动视暴雪的提议。一位熟悉微软计划的消息人士透露,该公司预计10月13日星期五为截止日期,届时微软将向全世界宣布,为期20个月的收购暴雪的流程即将结束。当然,届时微软能否如愿宣布这一消息,还要取决于英国反垄断监管机构竞争与市场管理局”(CMA)。站长网2023-10-06 21:45:290000