逼真复刻「完美中国情侣」!加强版Stable Diffusion免费体验,最新技术报告出炉
就在刚刚,号称是「开源版Midjourney」的Stable Diffusion XL0.9的技术报告,新鲜出炉。
「加强版」Stable Diffusion最新技术报告出炉了!

报告地址:
https://github.com/Stability-AI/generative-models/blob/main/assets/sdxl_report.pdf
在4月开启公测后,Stable Diffusion XL受到不少人的青睐,号称「开源版的Midjourney」。
在画手、写字等细节上,SDXL能够全局把控,最重要的是不用超长prompt就可实现。
不仅如此,比起需要氪金的Midjourney,SDXL0.9可以免费体验!


有趣的是,研究团队在最后的附录中,竟然感谢了「ChatGPT提供的写作帮助」。

「小胜」Midjourney
那么,与Midjourney相比,SDXL究竟有多能打?
报告中,研究人员从每个类别中随机选择了5个提示,并针对每个提示使用Midjourney(v5.1,种子设定为2)和SDXL生成了四张1024×1024的图像。
然后将这些图像提交给AWS GroundTruth任务组,该任务组根据遵循提示进行投票。
总体而言,在遵循提示方面,SDXL略优于Midjourney。

来自17,153个用户的反馈
对比涵盖了PartiPrompts(P2)基准测试中的所有「类别」和「挑战」。
值得注意的是,SDXL在54.9%的情况下优于Midjourney V5.1。
初步测试表明,最近发布的Midjourney V5.2在理解提示方面反而有所降低。不过,生成多个提示的繁琐过程妨碍了进行更广泛测试的速度。
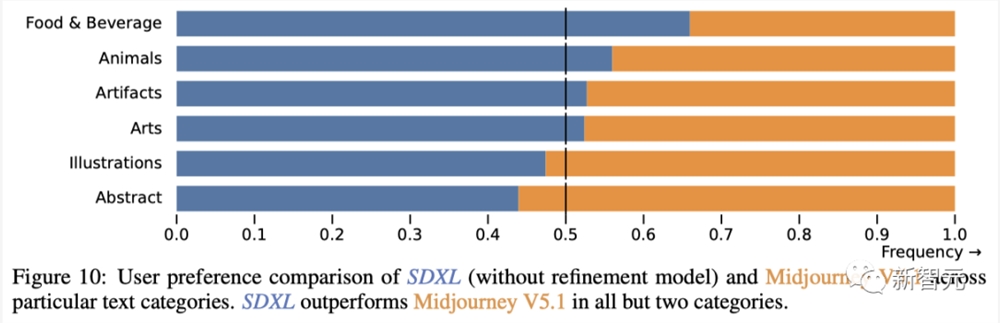
P2基准中的每个提示都按照类别和挑战进行了组织,每个类别和挑战都专注于生成过程的不同难点。
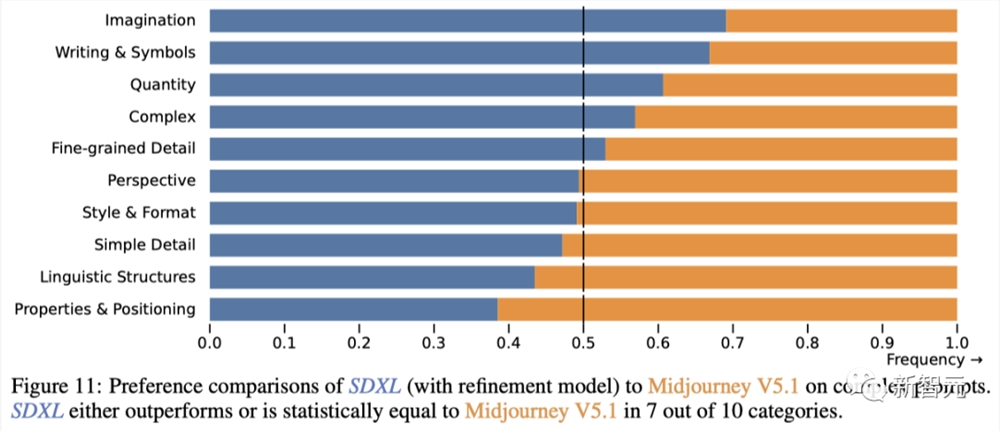
如下展示了P2基准中每个类别(图10)和挑战(图11)的比较结果。
在6个类别中的4个,SDXL表现优于Midjourney,在10个挑战中的7个,两个模型之间没有显著差异,或者SDXL表现优于Midjourney。
大家也可以来猜猜看,下面这组图中,哪些是SDXL生成的,哪些是Midjourney生成的。
(答案会在下文中揭晓)

SDXL:开源最强文生图
去年,号称最强文生图模型Stable Diffusion开源,点燃了全球生成式AI的火把。
比起OpenAI的DALL-E,Stable Diffusion让人们能够在消费级显卡上实现文生图效果。
Stable Diffusion是一种潜在的文本到图像的扩散模型(DM) ,应用非常广泛。
近来基于功能磁共振成像fMRI重建大脑图像的研究,以及音乐生成的研究都是基于DM展开的。
而这个爆火工具背后的初创公司Stability AI,在今年4月再次推出, Stable Diffusion改进版本——SDXL。
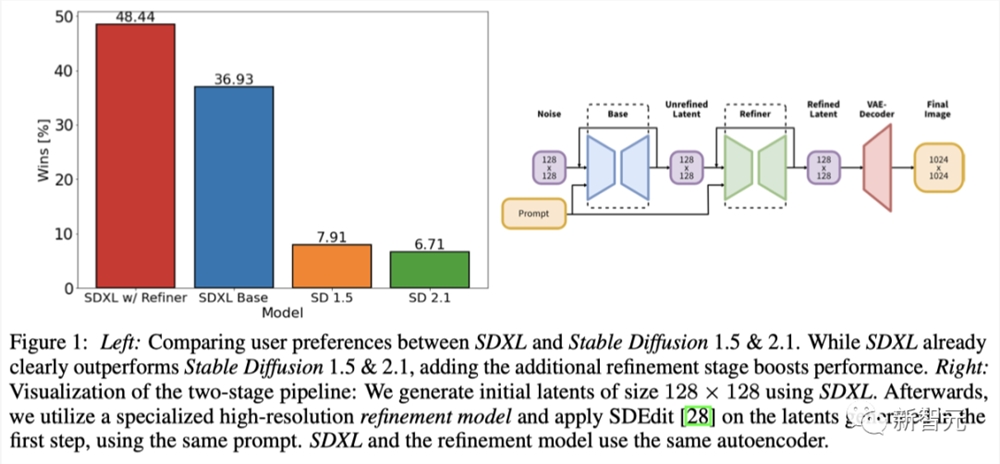
根据用户研究,SDXL的性能始终超过Stable Diffusion以前所有的版本,比如SD1.5、SD2.1。
报告中,研究人员提出了导致这种性能提升的设计选择,包括:
1)与以前的Stable Diffusion模型相比,UNet主干架构增加了3倍;
2)两种简单而有效的附加调节技术,不需要任何形式的额外监督;
3)一个单独的基于扩散的细化模型,该模型对SDXL产生的潜在信号采用去噪处理 ,以提高样本的视觉质量。
改善Stable Diffusion
研究人员对Stable Diffusion架构进行了改进。这些都是模块化的,可以单独使用,或一起使用来扩展任何模型。
报告称,尽管以下策略是作为潜在扩散模型的扩展开展的 ,但其中大多数也适用于像素空间的对应物。
当前,DM已被证明是图像合成的强大生成模型,卷积UNet架构成为基于扩散的图像合成的主导架构。
随着DM发展,底层架构也在不断演进:从增加自注意力和改进升级层,到文本图像合成的交叉注意力,再到纯粹基于Transformer架构。
在Stable Diffusion不断改进中,研究人员也在遵循这一趋势,将大部分Transformer计算转移到UNet中较低级的特征中。
特别是,与原来的SD架构相比,研究人员在UNet中使用了不同的Transformer块异构分布。
为了提高效率,并在最高特征级别中省略了Transformer块,在较低级别中使用2个和10个块,还在UNet 中完全删除了最低级别(8倍下采样),如下图所示。

SDXL与Stable Diffusion不同版本模型的比较
研究人员选择了一个更强大的预训练文本编码器,用于文本调节。
具体来说,将OpenCLIP ViT-bigG与CLIP ViT-L结合使用,这里沿着通道轴连接倒数第二个文本编码器输出。
除了使用交叉注意层来约束模型的文本输入之外,研究人员还遵循 ,并且OpenCLIP模型的混合嵌入文本上附加约束模型。
由此,这些因素导致了UNet中的模型参数大小为2.6B,文本编码器总参数为817M。
微调
潜在扩散模型(LDM)最大的缺点是,由于它是两阶段架构,训练一个模型需要最小的图像大小。
解决这个问题主要有2个方法,要么丢弃低于某个最小分辨率的训练图像,(SD1.4/1.5丢弃所有低于512像素的图像)要么选择超小的高级图像。
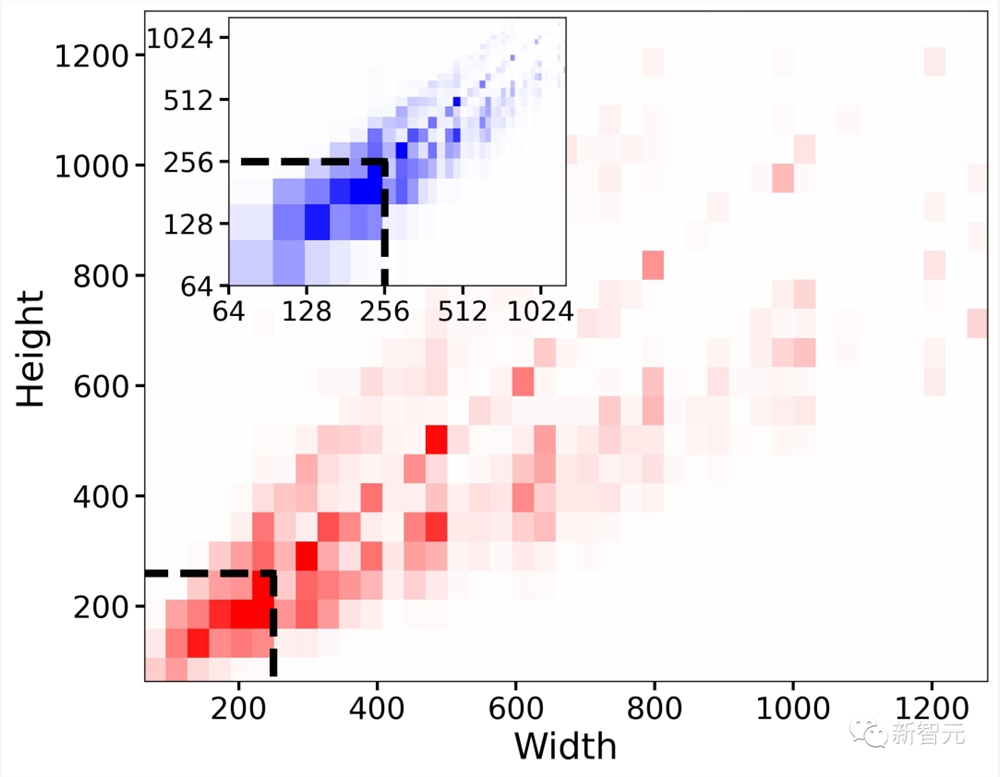
然而,第一种方法会导致可能导致大量的训练数据被丢弃,图像性能会损失。研究人员为SDXL预先训练数据集做了一个可视化效果。
对于特殊的数据选择,丢弃低于256×256像素预训练分辨率的所有样本,将导致39%数据丢失。
而第二种方法,通常会带来升级的伪影,这些伪影可能会泄露到最终的模型输出中,导致样本模糊。
对此,研究人员建议将UNet模型以原始分辨率为条件。这在训练期间非常容易获得。
特别是,提供了原始图像的高度和宽度作为模型
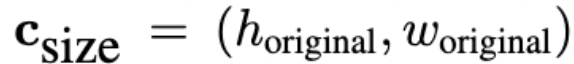
的附加条件。
每个组件都使用傅里叶特征编码独立嵌入,并连接成一个向量,研究团队通过添加到时间步长嵌入中来反馈到模型中。
在推断时,用户可以通过这种尺寸调节来设置图像所需的直观分辨率。显然 ,模型已经学会将条件
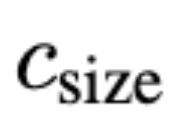
与分辨率相关的图像特性。
如图,研究人员显示了从SDXL中用相同的随机种子抽取4个样本,并改变大小调节。当调节较大的图像尺寸时,图像质量明显提高。

如下是SDXL的输出,与SD以前版本的比较。对于每个prompt,研究人员在DDIM采样器和cfg-scale8.0的50步的3个随机样本。
在先前的SD模型中,合成的图象可能会被不正确地裁剪,比如左边例子中SD1.5和SD2.1生成的猫头。
而从以下这些对比中不难看出,SDXL基本上已经把这个问题给解决了。




能够实现如此显著的改善,是因为研究人员提出了一种简单而有效的条件化方法:
在数据加载过程中,统一采样裁剪坐标
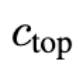
和

(分别指定从左上角沿高度和宽度轴裁剪的像素数量的整数),并通过傅里叶特征嵌入将它们作为条件化参数输入模型,类似于上述尺寸条件化方法。
然后使用连接嵌入
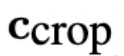
作为附加条件参数。
在此,研究团队特别强调,这并不是唯一适用于LDMs的技术,裁剪和尺寸调节可以很容易地结合起来。
在这种情况下,沿着通道维度连接嵌入的特征,然后将其添加到嵌入UNet的时间步长中。
如图,通过调优
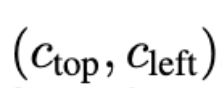
,可以成功地模拟推理过程中的裁剪量。

全面训练
受到以上技术启发,研究人员还对模型进行微调,以同时处理多个纵横比:将数据分割成不同纵横比的桶形,在这里尽可能保持像素计数接近1024×1024,相应地以64的倍数改变高度和宽度。
改进的自编码器
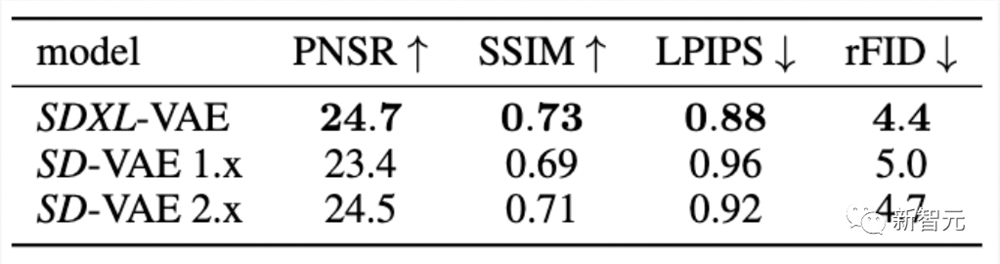
虽然大部分的语义构成是由LDM完成的,但研究人员可以通过改进自编码器来改善生成图像中的局部、高频细节。
为此,研究人员以更大的批处理规模(256vs9)来训练用于原始SD相同的自编码器结构,并以指数移动平均数来跟踪权重。
由此产生的自编码器在所有评估的重建指标中,都优于原始模型。
SDXL诞生了
研究人员在一个多阶段的过程来训练最终的模型SDXL。SDXL使用了自编码器,和1000步的离散时间扩散计划。
首先,在一个内部数据集上预训练一个基础模型,其高度和宽度分布显示为60万个优化步骤,分辨率为256×256,批大小为2048,使用如上所述的尺寸和裁剪调节。
然后,研究人员继续对512×512的图像进行训练,再进行20万个优化步骤,最后利用全面训练,结合0.05的偏移噪声水平,在约1024×1024像素区域不同纵横比训练模型。
在细化阶段上,研究人员发现得到的模型有时会产生局部质量低的样本,如下图所示。
为了提高样本质量,他们在相同的潜在空间中训练了一个独立的LDM,专门处理高质量、高分辨率的数据,并采用SDEdit在基本模型样本上引入去噪处理。
在推理过程中,研究人员使用相同的文本输入,从基本SDXL渲染潜在信息,并使用细化模型在潜在空间中直接扩散和去噪。

来自SDXL的1024×1024样本放大,没有(左)和有(右)细化模型
值得一提的是,这一步能够提高背景和人脸的样本质量,并且可选。

局限性
虽然SDXL在性能上已经有了不小的提升,但模型依然存在着明显的局限性。

首先,SDXL还是不能很好地处理比如人手这类的复杂结构。
研究人员推测,产生这种问题的原因是,由于不同图像中人手以及其他结构复杂的物体,存在着很大的差异性,因此模型很难提取出真实的3D形状。
其次,SDXL生成的图像还远不及照片那样逼真。
在一些微妙的细节上,比如弱光效果或纹理变化,AI生成的图像可能会出现缺失或表现得不够准确。
此外,当图像中包含有多个物体或主体时,模型可能会出现所谓的「概念溢出」现象。这个问题表现为,不同视觉元素的意外合并或重叠。
例如,下图中的橙色太阳镜,就是因为「橙色毛衣」出现了概念溢出。

而在图8中,本应该戴着「蓝色帽子」和「红色手套」的企鹅,在生成的图像中却是戴着「蓝色手套」和「红色帽子」。

与此同时,一直困扰着文生图模型的「文字生成」部分,依然是个大问题。
如图8所示,模型生成的文本有时可能包含随机字符,或者与给定的提示并不一致。
未来的工作
对此,研究人员表示,对于模型的进一步改进,主要会集中在以下几个方面:
• 单阶段生成
目前,团队使用的是一个额外的细化(refinement)模型以两阶段的方式,来生成SDXL的最佳样本。这样就需要将两个庞大的模型加载到内存中,从而降低了可访问性和采样速度。
• 文本合成
规模和更大的文本编码器(OpenCLIP ViT-bigG)有助于改善文本渲染能力,而引入字节级tokenizer或将模型扩展到更大规模,可能会进一步提高文本合成的质量。
• 架构
在探索阶段,团队尝试了基于Transformer的架构,如UViT和DiT,但没有显著改善。然而,团队仍然认为,通过更仔细的超参数研究,最终能够实现更大的基于Transformer的架构的扩展。
• 蒸馏
虽然原始的Stable Diffusion模型已经得到了显著的改进,但代价是增加了推断的成本(包括显存和采样速度)。因此,未来的工作将集中于减少推断所需的计算量,并提高采样速度上。比如通过引导蒸馏、知识蒸馏和渐进蒸馏等方法。
目前,最新报告还只在GitHub上可以查看。Stability AI的CEO称,马上会上传到arxiv上。

参考资料:
https://twitter.com/emostaque/status/1676315243478220800?s=46&t=iBppoR0Tk6jtBDcof0HHgg
https://github.com/Stability-AI/generative-models/blob/main/assets/sdxl_report.pdf
OpenAI砸了谁的饭碗?
OpenAI越变越强,不仅抢走谷歌等科技巨头的生意,还在砸掉创业者的饭碗。首届开发者大会之后,很多开发者担忧,自己的项目是否会被替代。而在开会之前,已经有好几家AI公司启动裁员,其中不乏曾拿过巨额融资的明星项目。0001eBay 推出 AI 辅助背景工具,增强产品图片
划重点:-eBay推出新的AI背景增强工具,允许卖家用AI生成的背景替换图片背景-该工具已在美国、英国和德国的iOS用户中推出,将逐渐在未来几个月内向Android用户推出-这一举措使得卖家无需专业设备或技能即可拍摄出专业外观的高质量照片站长网2024-06-06 20:46:070000AI在线字幕生成工具字幕酱 可自动生成、翻译字幕
字幕酱是一个在线字幕生成工具,利用AI深度学习技术,提供自动字幕生成、字幕翻译、字幕格式转换等功能。基于AI人工智能,字幕酱可以在线自动生成、自动翻译、格式转换和制作双语字幕。支持多种语言,如中文、英文、粤语、日语、韩语、德语、法语、西班牙语等,并提供在线语音转字幕工具。体验地址:https://www.zimujiang.com/特色功能:60秒内短视频免费,性价比极高;站长网2023-08-21 14:36:290002李国庆称ChatGPT替代不了阅读 后者可以安慰心灵
据《中国企业家》杂志消息,在4月23日的一次读书活动中,当当网创始人李国庆分享了他的观点。李国庆认为,ChatGPT无法取代阅读的作用。阅读不仅可以让人的内心得到平静,也是一种审美享受,这些都是ChatGPT所无法替代的。此外,在晚上睡不着的时候,阅读文学作品能够安慰心灵。而阅读的另一个重要作用则是帮助人们求道解惑。通过阅读,人们可以以较低的成本获得各种知识,这是最有价值的一种投资。站长网2023-04-23 17:34:210000泰国皇家集团索赔中国瑞幸100亿 瑞幸:未接通知
据泰国媒体报道,泰国皇家50R集团向法院提交诉讼,要求中国瑞幸咖啡赔偿100亿泰铢经济损失。法院已立案受理。文件显示,50R集团2020年向泰国商务部注册瑞幸商标,获准使用经营咖啡店。但中国瑞幸向法院提起诉讼,指控其恶意注册。初审判决50R败诉。50R不服提出上诉,12月1日二审胜诉。对此,瑞幸咖啡未就此事置评。瑞幸客服表示,未收到通知。0000