AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
【新智元导读】首个高质量文本转视频开源模型Zeroscope,仅需8G显存就能用!
文生图模型Stable Diffusion开源后,将「AI艺术」彻底平民化,只需一张消费级显卡即可制作出非常精美的图片。
而文本转视频领域,目前质量较高的只有Runway前不久推出的商用Gen-2模型,开源界还没有一个能打的模型。
最近,Huggingface上有作者发布了一个文生视频模型Zeroscope_v2,基于17亿参数量的ModelScope-text-to-video-synthesis模型进行二次开发。
模型链接:https://huggingface.co/cerspense/zeroscope_v2_576w
相比于原版本,Zeroscope生成的视频没有水印,并且流畅度和分辨率都得到了提升,适配16:9的宽高比。
开发者cerspense表示,他的目标就是和Gen-2进行开源较量,即提高模型质量的同时,还能免费供大众使用。
Zeroscope_v2包括两个版本,其中Zeroscope_v2567w可以快速生成576x320像素分辨率、帧率为30帧/秒的视频,可用于视频概念的快速验证,只需要约7.9GB的显存即可运行。
Zeroscope_v2XL可以生成1024x576分辨率的高清视频,大约需要15.3GB的显存。
Zeroscope还可以与音乐生成工具MusicGen一起使用,快速制作一个纯原创短视频。
Zeroscope模型的训练用到了9923个视频片段(clip)以及29769个标注帧,每个片段包括24帧。偏移噪声包括视频帧内对象的随机移位、帧定时(frame timings)的轻微变化或微小失真。
训练期间引入噪声可以增强模型对数据分布的理解,从而可以生成更多样化的逼真视频,并更有效地解释文本描述中的变化。
使用stable diffusion webui
在Huggingface上下载zs2_XL目录下的权重文件,然后放到stable-diffusion-webui\models\ModelScope\t2v目录下即可。
在生成视频时,推荐的降噪强度值为0.66到0.85
使用Colab
笔记链接:https://colab.research.google.com/drive/1TsZmatSu1-1lNBeOqz3_9Zq5P2c0xTTq?usp=sharing
先点击Step1下的运行按钮,等待安装,大约需要3分钟;

当按钮旁边出现绿色复选标记时,继续执行下一步。

点击想要安装模型附近的运行按钮,为了能够在Colab中快速获得3秒左右的剪辑视频,更推荐使用低分辨率的ZeroScope模型(576或448)。

如果相运行更高分辨率模型(Potat1或ZeroScope XL),运行也会更费时间,需要做出权衡。
再次等待复选标记出现,继续执行下一步。
选择在Step2中安装并希望使用的模型型号,对于更高分辨率的模型,推荐下面的配置参数,不需要太长的生成时间。
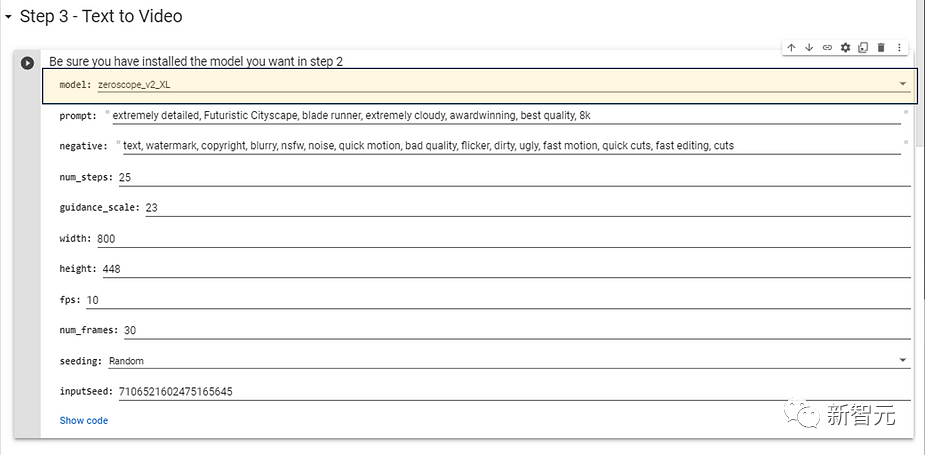
然后为目标视频效果输入提示词,也可以输入否定提示(negative prompts),再按下运行按钮。
等待一会后,生成的视频就会被放置在outputs目录下。
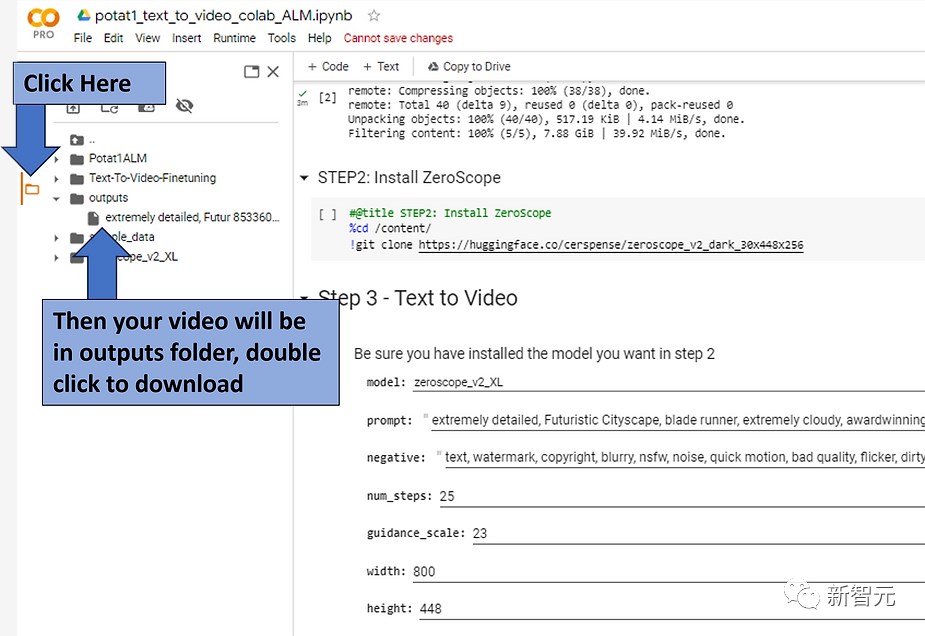
extremely detailed, Futuristic Cityscape, blade runner, extremely cloudy, awardwinning, best quality,8k
非常详细,未来城市景观,叶片亚军,极端多云,获奖,最好的质量,8k
目前来说,文生视频领域仍处于起步阶段,即便是最好的工具也只能生成几秒钟的视频,并且通常存在较大的视觉缺陷。
但其实文生图模型最初也面临着类似的问题,但仅仅几个月后就实现了照片级真实感。
不过与文生图模型不同的是,视频领域在训练和生成期间所需要的资源都要更比图像更多。
虽然谷歌已经研发出了Phenaki和Imagen Video模型,可以生成高分辨率、更长、逻辑连贯的视频片段,但公众无法使用到这两个模型;Meta的Make-a-Video模型也同样没有发布。
目前可用的工具仍然只有Runway的商用模型Gen-2,此次Zeroscope的发布也标志着文生视频领域第一个高质量开源模型的出现。
参考资料:
https://the-decoder.com/zeroscope-is-a-free-text-to-video-model-that-runs-on-modern-graphics-cards/
“新娱乐”内容的风向标,指向大众与多元
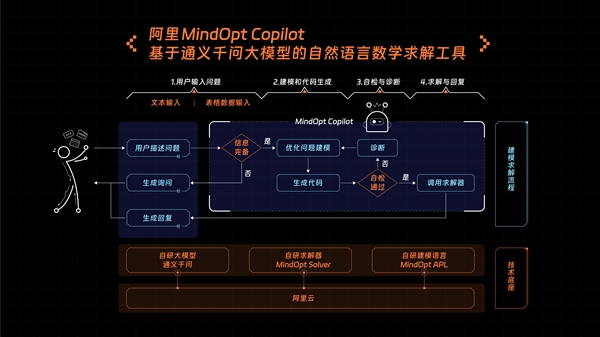
如今的娱乐内容消费市场正在加速升温。暑假期间,周杰伦圆梦嘉年华助力锦鲤粉丝演唱会点歌,帮千万老铁实现点歌心愿、蔡依林在快手独家直播开唱、成龙野营谈唱会唤醒一代人的青春记忆……快手娱乐率先引爆了明星直播的暑期热潮,打造出了诸多明星的“直播大事件”。此外,短剧赛道也迎来集中爆发,快手娱乐推出的星芒短剧暑期档首次将短剧以档期化的方式运营,通过不同风格、不同题材的多元化作品满足用户的追剧需求。0000阿里大模型数学工具MindOpt Copilot将上线
阿里决策智能团队研发了一款基于大模型的数学工具MindOptCopilot。该工具基于阿里自研的大模型、求解器、建模语言三大件开发,借助底层的通义千问大模型,将用户以自然语言描述的优化问题转化为线性规划和混合整数线性规划的优化模型,并获得最佳答案。MindOptCopilot可用于解决各种场景的资源配置和优化问题,如餐饮、零售、物流货运、生产制造等。站长网2023-08-19 15:25:330000美图吴欣鸿:自研视觉大模型MiracleVision已迭代至1.5版本
8月3日,美图创始人、董事长兼CEO吴欣鸿参加第四届中国人工智能大赛成果发布会。在会上,吴欣鸿透露,目前美图自研视觉大模型已迭代到1.5版本,并应用于美图旗下多款产品。站长网2023-08-04 08:23:130000百度Comate升级:推出Comate+开放平台和AutoWork私人研发助理
BaiduComate在2024年3月1日进行了重磅升级,推出了两大重磅能力,分别是“Comate”开放平台和AutoWork“私人研发助理”。1.Comate开放平台:-该开放平台将企业私域知识、第三方能力与编程现场深度结合,可快速应用大模型能力,无限扩充平台场景。-可对接企业私域知识,提升准确率,已实现推荐准确率提升10%以上。站长网2024-03-06 14:20:450002播放分钟数代替播放量、24年“盈亏平衡”:B站商业化“急了”?
没有人能永远年轻,就连B站也不例外。成年人的世界注定满怀KPI的焦虑,今年以来,B站频频因“商业化”问题而置身风口浪尖:4月,UP主停更潮热搜引发质疑;618期间,举全平台之力打造的百大UP主“宝剑嫂”首播,总成交GMV达2800万元,但外界仍认为B站还需要更多的宝剑嫂;站长网2023-07-05 19:41:410001