Google AI 推出 MediaPipe Diffusion 插件:可在设备上实现可控的文本到图像生成
Diffusion 模型近年来在文本到图像生成方面得到广泛应用,并取得了显著的成功,从而在图像质量、推理性能和创造性范围方面实现了重大改进。然而,在难以用文字明确定义的条件下,有效的生成管理仍然是一个挑战。

由谷歌研究人员开发的 MediaPipe Diffusion 插件使得用户可以在设备上执行文本到图像的生成,并进行用户控制。在这项研究中,谷歌延伸了之前关于设备上大型生成模型的 GPU 推理的工作,提出了低成本的可编程文本到图像创建解决方案,可以集成到现有的 Diffusion 模型及其 LoRA 变体中。
Diffusion 模型中模拟了迭代去噪的图像生成过程。Diffusion 模型的每一次迭代都以受噪声污染的图像开始,并以目标概念的图像结束。通过文本提示的语言理解极大地增强了图像生成过程。文本嵌入通过交叉注意力层与文本到图像生成模型关联起来。然而,物体的位置和姿态等细节可能更难以通过文本提示传达。研究人员通过额外的模型将条件图像中的控制信息引入到 Diffusion 中。
Plug-and-Play、ControlNet 和 T2I Adapter 方法经常用于生成受控的文本到图像输出。Plug-and-Play 使用 Diffusion 模型的副本(Stable Diffusion1.5 版本的 860M 参数)和广泛使用的去噪 Diffusion 隐式模型(DDIM)反演方法来从输入图像中推导出初始噪声输入。
通过自注意力从复制的 Diffusion 中提取空间特征,并使用 Plug-and-Play 将其注入到文本到图像 Diffusion 中。ControlNet 构建了 Diffusion 模型编码器的可训练副本,并通过一个带有零初始化参数的卷积层连接到编码条件信息,然后传递给解码器层。不幸的是,这导致了模型的显著增大,Stable Diffusion1.5 版本的参数约为 4.5 亿个,相当于 Diffusion 模型本身的一半。T2I Adapter 在较小的网络(77M 参数)下实现了可比较的受控生成结果。条件图像是 T2I Adapter 的唯一输入,其结果被用于所有后续的 Diffusion 周期。然而,这种适配器样式不适用于移动设备。
MediaPipe Diffusion 插件是谷歌开发的一个独立网络,旨在使条件生成变得高效、灵活和可扩展。
作为一种便携式的设备上文本到图像创建范式,MediaPipe Diffusion 插件可以免费下载使用。它接收一个条件图像,并通过多尺度特征提取将特征添加到 Diffusion 模型的编码器中的适当尺度上。
当与文本到图像 Diffusion 模型结合使用时,插件模型将一个条件信号添加到图像生成过程中。谷歌希望插件网络只有 600 万个参数,使其成为一个相对简单的模型。
MediaPipe:https://developers.google.com/mediapipe
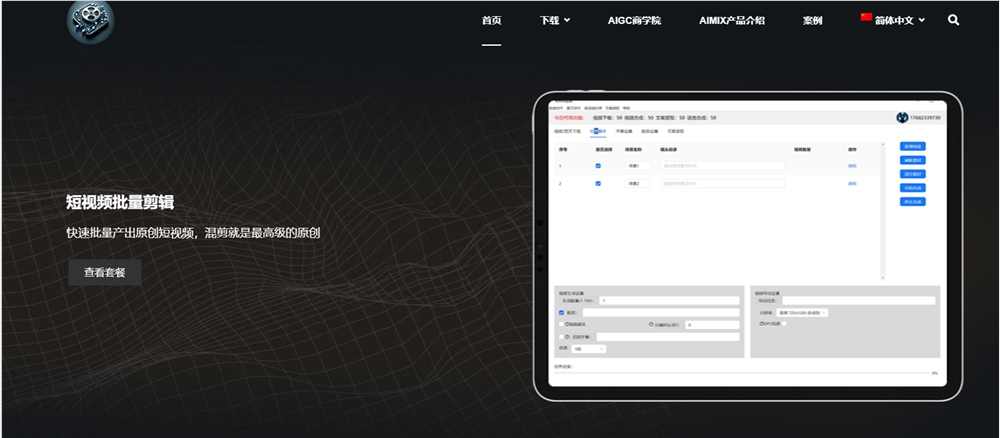
AI智能剪辑软件AIMIX 支持短视频批量混剪、文案、字幕生成、语音合成等
AIMIX是一款集视频批量混剪、文案、字幕生成、语音合成等功能于一体的AIGC智能剪辑软件。用户可以通过这款软件快速批量产出原创短视频,利用自己积累的素材库进行混剪,从而生产源源不断的短视频。官网地址:https://top.aibase.com/tool/aimixzhijian站长网2024-02-01 11:57:170002国家邮政局:二季度顺丰、邮政、中通快递72小时准时率较高
7月28日,国家邮政局发布关于2023年第二季度快递服务满意度调查和时限准时率测试结果的通告。2023年监测对象包括9家快递服务品牌,具体为:邮政速递、顺丰速运、中通快递、圆通速递、韵达速递、申通快递、京东快递、德邦快递和极兔速递。调查范围覆盖50个城市,包括各直辖市、省会城市和19个快递业务量较大的城市。站长网2023-07-28 15:12:160000一家人都在带货?单场成交超500万,全红婵热度撑起“全”家生意
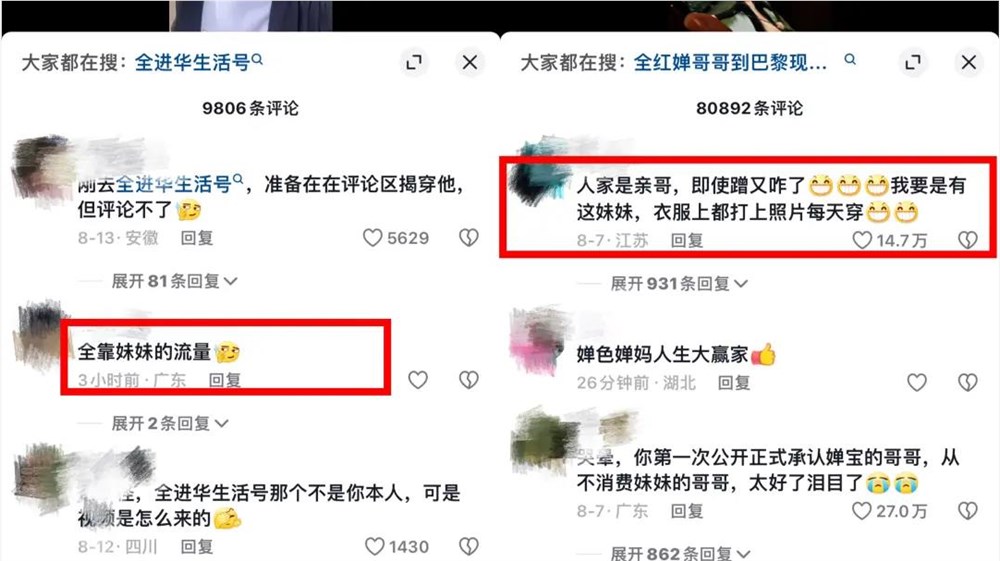
“全靠妹妹流量!”“人家是亲哥,即使蹭又咋了,我要是有这妹妹,衣服上都打上照片每天穿!”在奥运冠军全红婵哥哥全进华的社交平台账号下充斥着不少这样的评论,奥运冠军家人的身份,让他的带货事业收到了不少“蹭全红婵热度”的质疑声。站长网2024-08-20 12:13:550000Coze Bots用户使用情况数据分析:游戏和教育类占比最高
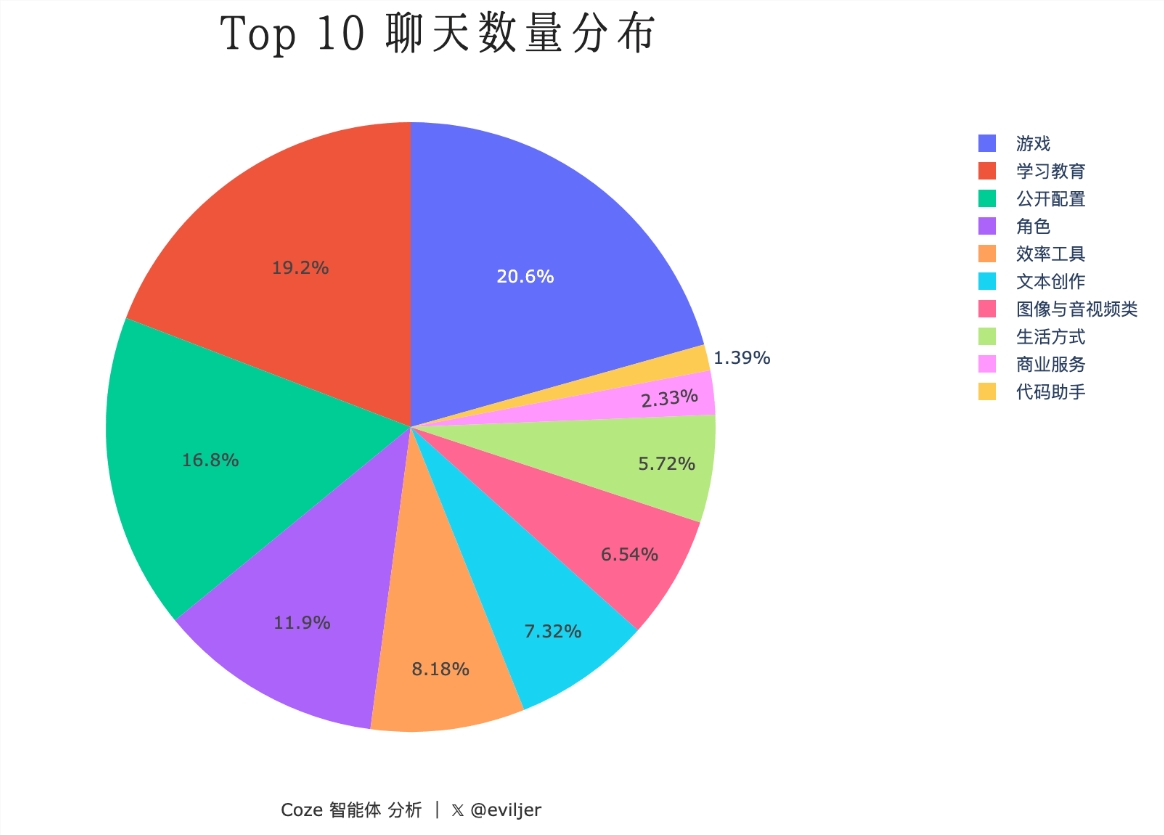
日前,X博主@eviljer分享了CozeBots数据分析与可视化图表,清晰的展示CozeBots具体使用情况。据了解,根据Leo兄提供的数据汇总统计,该分析报告对10个类目合计约10,000条数据进行了深入的数据分析与可视化展示。以下是通过可视化分析展示了各类目中“聊天数量”的Top10累和分布情况。站长网2024-06-05 16:37:500001华为工程师回应Pura 70 AI消除衣物争议:根据肉色人体背景补全
快科技4月26日消息,日前,华为Pura70的AI修图功能被能一键消除衣物”漏洞,引起网友广泛关注。针对该漏洞,华为迅速进行修复,目前再尝试对胸部使用该功能时,系统会提示此图无法使用消除功能。”据媒体报道,华为高级工程师对此回应并解释称:相关视频中该功能将原本穿着衣服照片的部分消除,是因为识别到用户只勾选衣领这一小部分,消除后AI大模型根据肉色的人体背景进行了补全,并没有故意放大或缩小。”站长网2024-04-26 22:26:060000