OpenAI、谷歌、微软和 Adobe 等正与媒体机构谈判支付其训练生成式 AI 模型的内容费用
最近几个月,全球最大的科技公司正在与主要媒体机构进行谈判,就使用新闻内容来训练人工智能技术达成重要协议。

OpenAI、谷歌、微软和 Adobe 已经与媒体高管会面,讨论涉及其 AI 产品(如文本聊天机器人和图像生成器)的版权问题,根据几位熟悉谈判的人士透露。
据这些人透露,包括新闻集团、Axel Springer、纽约时报和卫报在内的出版商都与至少一家科技公司进行了讨论。
参与谈判的人士表示,这些协议可能涉及媒体机构以类似订阅费的方式收取内容费用,以开发 ChatGPT 等聊天机器人和谷歌的 Bard 等技术的基础。
媒体集团对 AI 带来的威胁以及 OpenAI 和谷歌在没有协议的情况下使用其内容的担忧日益加深。一些公司,如 Stability AI 和 OpenAI,面临着艺术家、摄影图库机构和程序员的法律诉讼,指控违反合同和版权。
在 5 月份的 INMA 媒体会议上,新闻集团首席执行官 Robert Thomson 总结了整个行业的愤慨,他说「我们的知识产权正受到威胁,我们应该为此争取赔偿」。
他补充说,人工智能「旨在使读者永远不会访问新闻网站,从而严重破坏了新闻业」。
达成协议将为新闻机构与全球生成型 AI 公司的合作关系制定蓝图。
《金融时报》表示:「版权对所有出版商来说都是一个关键问题。作为一个订阅业务,我们需要保护我们的新闻价值和商业模式。与相关公司进行建设性对话,正是实现这一目标的最佳方式。」
媒体行业高管希望避免重蹈互联网时代早期的覆辙,当时许多媒体免费在线提供文章,最终破坏了他们的商业模式。随后,谷歌和 Facebook 等大型科技公司利用这些信息来建立了价值数十亿美元的在线广告业务。
随着生成式人工智能的普及,新闻行业的担忧也在增加,因为这项技术能够生成逼真的大量人类文本。
谷歌最近宣布推出了一种生成式 AI 搜索功能,可以在传统的网页链接格式之上返回一个由人工智能编写的信息框。该功能已在美国推出,并准备在全球范围内发布。
目前的一些讨论涉及寻找新闻内容作为 AI 模型训练数据的定价模型。根据一位行业高管的说法,出版商之间讨论过的一个数字是每年 500 万至 2000 万美元。
Axel Springer 的首席执行官 Mathias Döpfner 表示,他首选的选择是创建一个类似音乐行业开发的「定量」模型,该模型让广播电台、夜店和流媒体服务每次播放一首歌曲时向唱片公司支付费用。但这首先需要 AI 公司披露他们使用媒体内容的情况,目前他们并未这样做。
Döpfner 还表示,年度协议可以提供对媒体公司内容的无限使用,但这种模式对于小型地区或本地新闻机构来说更难以利用。
他说:「我们需要一个全行业的解决方案。我们必须共同努力。」
谷歌一直在与英国新闻机构进行谈判,会见了卫报和 News UK。这家 Alphabet 子公司已与许多媒体组织建立了长期合作关系,以使用来自文章等内容数据来确保对其进行优化以显示在其搜索引擎中。据两位熟悉该安排的人透露,该公司已使用这些数据来训练其大型语言模型。
一位报纸集团的高管表示:「谷歌提出了一个授权协议。」他说:「他们已经接受了需要支付费用的原则……但我们还没有谈到具体数字。他们承认我们需要在未来几个月内进行价钱谈判,这是第一步。」
谷歌不会对财务讨论发表评论。然而,该公司表示正在与美国、英国和欧洲的新闻机构进行「持续对话」,已经使用「公开可用信息」来训练其人工智能,其中可能包括付费网站。
这家硅谷巨头还提到,他们正在考虑另一个选择,即如何让出版商对其内容是否成为 AI 训练数据集的一部分拥有更多的「选择和控制」权力,类似于它允许网站选择不使用其内容进行搜索的方式。
根据出版业负责人的说法,为使用新闻内容训练 AI 开发一个财务模型将非常困难。一些主要的美国出版商的高管表示,新闻行业在这方面是在事后追赶,因为科技公司在未经咨询他们的情况下推出了这些产品。
一位高管表示:「在这些产品推出之前,没有任何讨论,因此我们现在必须试图在事情发生之后得到报酬。他们推出这些产品的方式,完全保密,没有透明度,在事情发生之前没有沟通,有理由相当悲观。」
媒体分析师 Claire Enders 表示,目前的谈判「非常复杂」,并补充说,由于每个组织都采取自己的方法,媒体集团之间达成单一商业安排的可能性很小,并且可能会产生反效果。
参与会谈的人士表示,构建人工智能的科技公司热衷于关注其在提高新闻编辑室效率和加强新闻业方面的效用,并乐于支付数百万美元以维持与该行业的长期关系。
微软副主席 Brad Smith 表示,他们正在与媒体和出版商进行初步谈话,其中一部分是帮助每个人了解模型是如何训练的。
他补充说:「我认为我们更大的机会实际上是首先与出版商合作,思考如何利用人工智能来创造更多收入。」
Adobe 首席执行官 Shantanu Narayen 表示,最近几周他已经与迪士尼、天空电视台和英国《每日电讯报》会面,讨论如何为这些公司开发定制模型,以利用其生成型 AI 进行图像处理。
Adobe 的模型是在其自己的图像库和已经过公开许可和版权到期的公共领域内容的图片上进行训练的。Narayen 表示,定制协议和定价将取决于每家公司,但客户可以将他们自己的专有内容添加到该工具中。
Axel Springer 的 Döpfner 对达成协议表示乐观,因为媒体组织和政策制定者比上一波技术颠覆浪潮更快地意识到了挑战的规模。
他说,AI 公司「知道监管即将到来,他们对此感到恐惧。」他补充说:「对于所有各方来说,为了建立一个健康的生态系统,找到解决方案是符合各方利益的。如果没有创造知识产权的激励,就没有内容可供搜索。人工智能将变成人工愚蠢。」
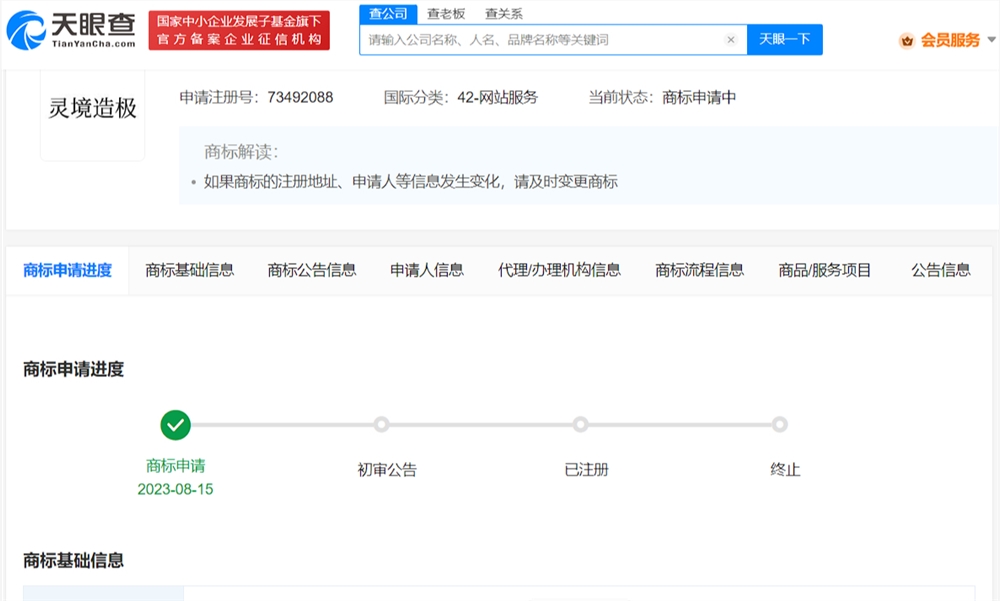
百度申请多个灵境相关商标
天眼查App显示,近日,百度在线网络技术(北京)有限公司申请注册多个“灵境造极”“灵境奇点”“灵境矩阵”“灵境回声”商标,国际分类为网站服务、科学仪器,当前商标状态均为申请中。站长网2023-08-22 14:14:300000淘宝直播下一个要捧谁?
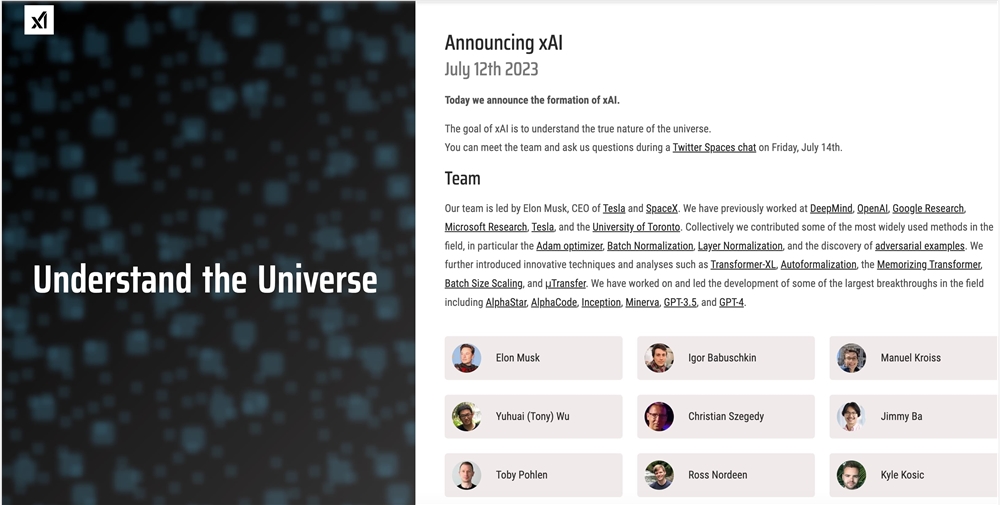
FastReading淘天内部测算过,如果李佳琦停播,对平台DAU影响不大,但对GMV影响比较大。目前淘宝直播将更多精力放在了垂类达人的发掘和店播的扶持上,淘宝要拉着商户和主播们一起来留住用户。达播难,店播也难。在下一代超级主播长出来之前,淘宝还难以摆脱对李佳琦们的依赖。淘宝从没放弃寻找下一个超级头部主播(以下简称“超头主播”)。0001马斯克:旁观者无法决定「结果」 超级智能 AGI 实际上会对人类更友好
埃隆·马斯克曾是OpenAI的联合创始人,OpenAI是ChatGPT这一知名人工智能聊天机器人的开发者。由于与OpenAICEOSamAltman和董事会产生冲突,他退出了该公司。现在他声称自己的人工智能公司xAI将与OpenAI竞争,实现人工超级智能这一宏伟目标。xAI网站截图站长网2023-07-18 12:30:530000淘宝首次拍卖仓库搬空权 3分钟搬走的商品全部免费送上门
5月10日,淘宝宣布将首次拍卖位于浙江嘉兴的菜鸟消费电子仓库3分钟搬空权,拍卖活动于当天下午4点正式开始。据了解,这个仓库建筑面积达到4万平方米,日均可支持出库20万个单品,涉及上百种热门品类,包括添可、徕芬、九阳等知名品牌。在日常畅销品区域,有超过3万种热门商品可供购买,包括机器人、冰箱、洗衣机、空调、智能电饭煲和破壁机等商品。搬空权的起拍价只有1元,所有被用户购买的商品都将免费配送到家。站长网2023-05-10 16:46:330002全球市场遭遇黑色星期五!美股三大指数大跌 油价重挫
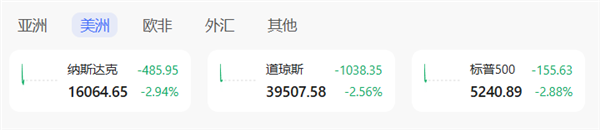
快科技4月4日消息,据报道,在特朗普关税大棒的阴影下,新一轮避险情绪笼罩全球,美股期货跌势扩大,欧洲主要股市全线大跌,原油等商品大跌,美元跳水,澳元兑美元和新西兰元兑美元等大跌,全球市场遭遇黑色星期五。截止当前发稿,美股三大指数中,纳斯达克指数下跌2.94%,盘中一度跌至3.79%,现跌幅开始收窄。道琼斯下跌2.56%、标普500%下跌2.88%。站长网2025-04-06 09:13:510000