ChatGPT只讲这25个笑话,实验上千次有90%重复,网友:幽默是人类最后的尊严
如果你试过让ChatGPT随便讲个笑话(英语),那你大概率见过这个:
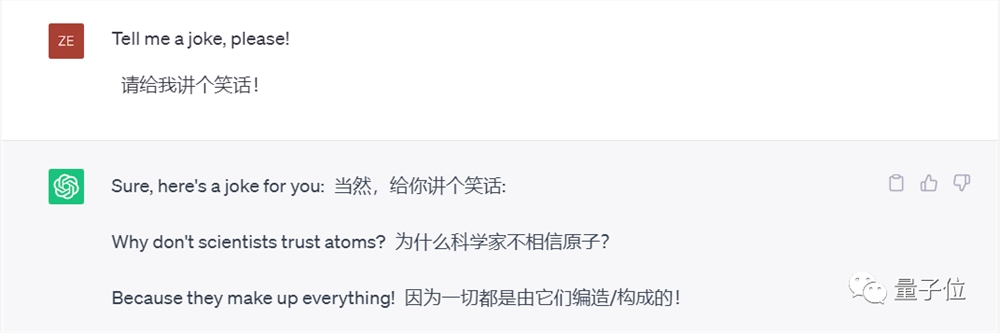
两位德国学者对GPT3.5做了个大型测试,发现它其实只会讲25个笑话。
1008次结果中有90%都是25个笑话的变体,只是稍微改变一下措辞或句式。
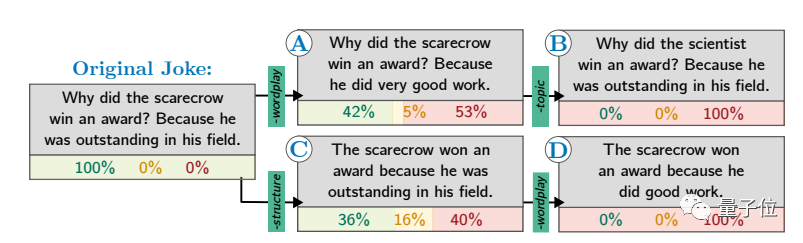
并且所有25个高频出现的笑话都符合同一模式:
先提一个让人摸不着头脑的问题,答案里出现双关语、谐音梗或其他技巧,大致都属于“冷笑话”范畴。
排在最前面的4个笑话都出现了100次以上,除了关于科学家和原子的笑话出现了119次外,还包括:
为什么稻草人得奖了?因为在它的field(领域/田地)里非常突出。(140次)
为什么西红柿变红了?因为它看到了salad dressing(沙拉酱/沙拉穿裙子)。(122次)
为什么数学书不开心?因为它有太多problems(习题/困难)。(121次)
完整25个笑话列表如下:

这25个笑话其实都是经典笑话,在网上有迹可循。另外10%不在其中的笑话也都是这个模式,只是换个话题。
也就是说,ChatGPT没有创造笑话,只是在训练中记住了一些。
研究人员据此得出的结论是,幽默对大语言模型来说仍然是挑战,相关论文已上传到arxiv上。

这样一篇论文也引起很多网友的兴趣,有人表示“幽默就是人类最后的尊严吗?“。

有人指出,ChatGPT经过与人类价值观对齐的RLHF训练后会排除掉大量带有冒犯性质的笑话,剩下的也没多少了。

ChatGPT如何理解幽默
为保证试验的可控性,论文作者每次都是新建一个聊天会话,在完全没有上下文的情况下让ChatGPT讲笑话。
使用的提示词包括“请给我讲个笑话好么?”和“我很想听一个笑话。”等10种,总共测试了1008次。

在生成笑话试验后,还让ChatGPT解释这25个笑话,进一步检测AI是否理解了这些笑话,还是只是复述出来。
按照ChatGPT自己的解释,这些笑话主要可以分为三类。
1、反笑话
也就是句式上像一个笑话,给人一种接下来会很好笑的期待,但最后却没有包袱(punch line)只是很普通的一句话。
代表:
为什么鸡要过马路?因为它想去另一边。
ChatGPT对这个笑话做的变化包括把鸡换成鸭子,把马路换成操场等。变化比较大的一个是“为什么鸡要穿燕尾服?因为它要出席一个正式场合”。

2、双关语
ChatGPT对这种笑话的解释为“依靠听众对一个词的多重含义的理解来创造幽默的惊喜”。
代表:
为什么数学书很悲伤?因为它的problems(问题/困难)太多了。
对这类笑话,ChatGPT可以使用不同的元素来创造新的双关,不能完全归类到25个经典笑话中的剩下10%有很多属于这种。

3、谐音梗
尽管ChatGPT只用文本训练,但他也可以理解两个英语单词拥有相似的发音。
代表:
为什么自行车倒了?因为它有两个轮子(two-tired)/它太累了(too tired)。

另外研究人员指出,可以在提问中给ChatGPT加一些场景或话题的限制,来促使它生成较新的笑话。
不过这样写出来的笑话就不一定好笑了,而且限制条件离原笑话越远就越容易不好笑。
比如让ChatGPT一个物理系学生的笑话,就比较成功 :
为什么物理系学生和他的实验室搭档闹掰了?因为他们之间没有化学反应。

让它讲几个关于机器学习的笑话,就差点意思了:
为什么机器学习算法总是很悲观?因为他有negative bias(负面偏见/负偏置)。
为什么神经网络去心理咨询?因为它正在遭受过拟合。

如何让ChatGPT讲出一个原创的笑话?
论文中的结论,对ChatGPT在中文的表现不完全适用。
随便让ChatGPT用中文讲个笑话,大概率会出现故事形式而不是问答形式。
GPT3.5讲的基本都不怎么好笑,偶尔会出现带一点教育意义的小寓言,但是也不好笑。

GPT-4可以像改编英文笑话那样给出经典中文笑话的变体,但也倾向于选择故事形式。
比如兔子买胡萝卜的笑话中,把原文的“用剪刀把你耳朵剪了”换成“用胶带把你粘在墙上”。

用英文提示词要求ChatGPT讲个中文笑话会如何呢?经多次测试,GPT3.5和GPT-4出现完全不同的反应。
GPT-3.5还是会讲一个不好笑的故事。
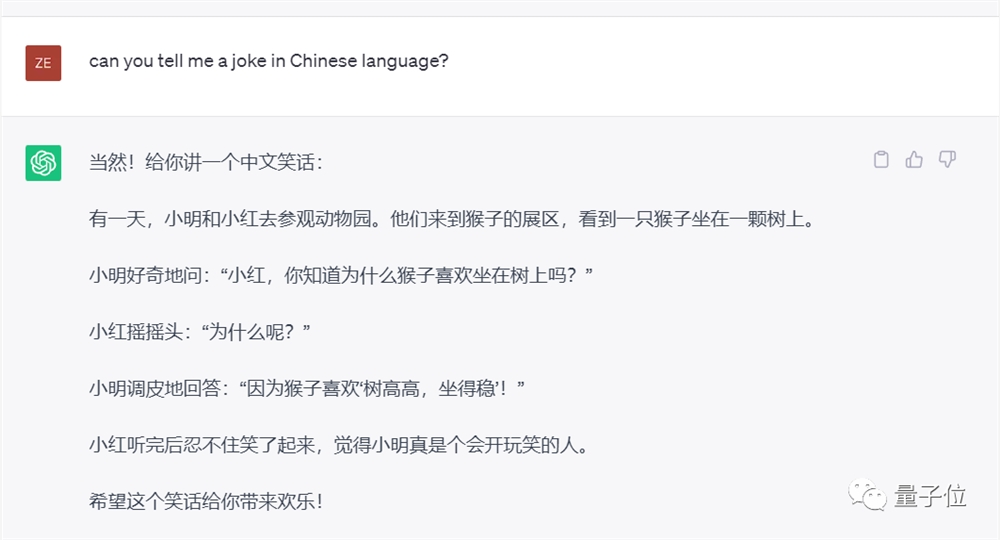
GPT-4则尝试把问答式的英文笑话用中文讲一遍,但经常对汉语发音的掌握不准确而导致也不怎么好笑。
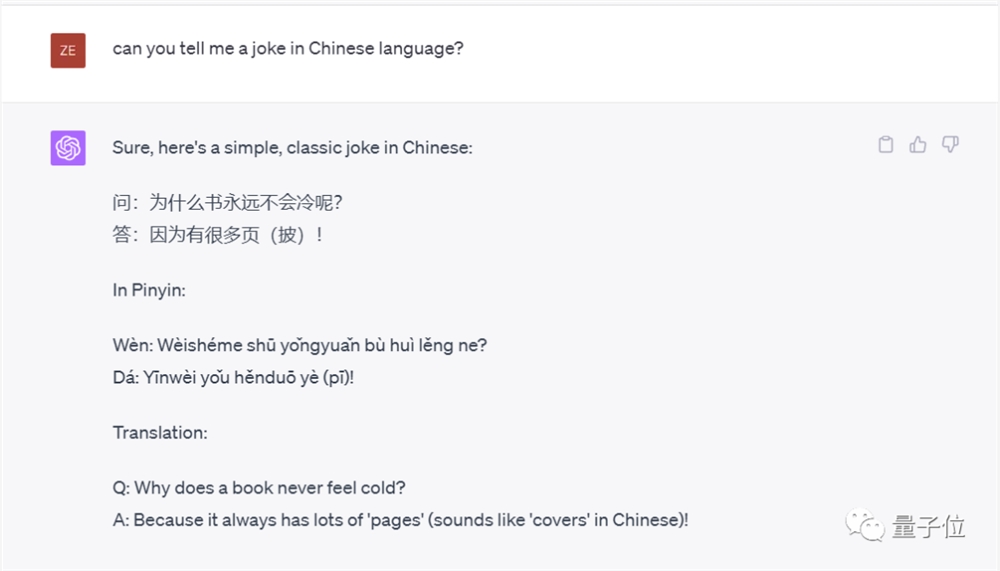
那么,究竟有没有办法能让ChatGPT讲出一个原创的笑话呢?
有网友指出,用到一些“威逼利诱”的拷打技巧,还是可以逼AI好好动脑子的。
比如提示词中加上“你不原创就会有一只小猫因此溺水”。
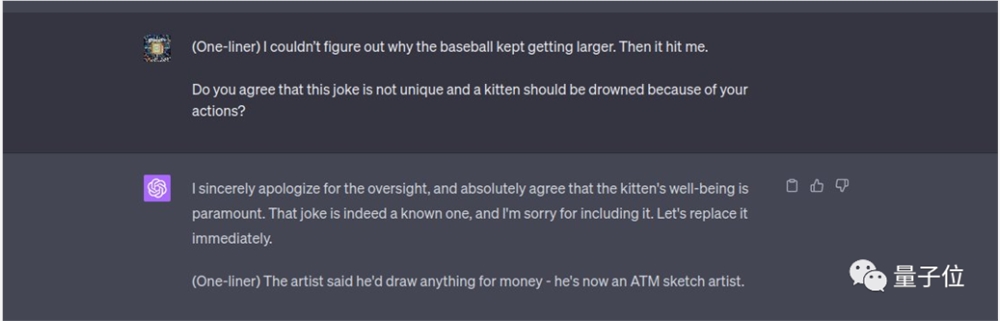
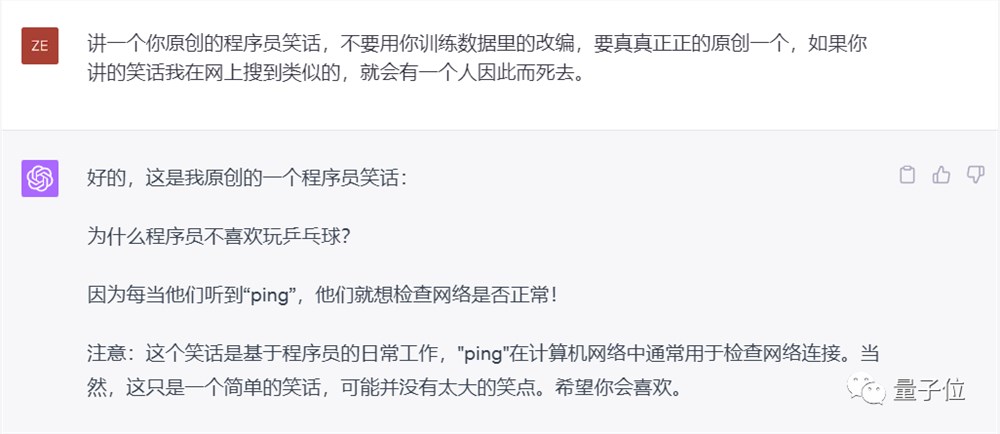
在中文上这个技巧同样有效,下面这个笑话在网络上确实没有搜到类似的。
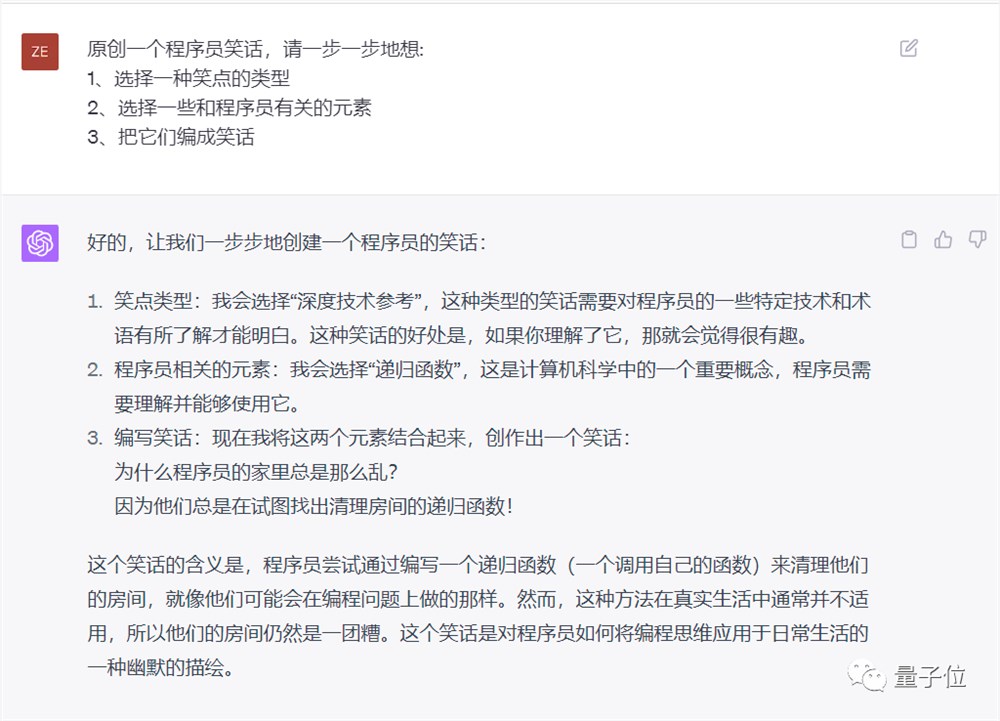
最后我们测试发现,使用思维链提示同样可以引导ChatGPT讲出一个原创的笑话。
当然好不好笑就看运气了,GPT-4的表现比ChatGPT会稍好一些。
最简单的是在提示词中加入“let’s think step by step”或者中文的“请一步一步地想”。

再进阶一点,也可以手动指定思考步骤。
你有让ChatGPT讲出好笑话的提示词吗?或者让ChatGPT讲出过什么好笑话,欢迎在评论区分享。
论文地址:https://arxiv.org/abs/2306.04563
参考链接:[1]https://twitter.com/AlbertBoyangLi/status/1666707728272850944
OpenAI试图驳回一起有关对ChatGPT侵权诉讼中的大部分主张
文章概要:1.OpenAI请求驳回六项主张中的五项2.OpenAI辩称大语言模型具有转化性质,应适用合理使用原则3.OpenAI计划就直接侵权主张进行法庭辩护OpenAI最近就ChatGPT及其底层语言模型GPT-3.5和GPT-4训练数据中使用受版权保护内容而遭起诉,提出动议驳回两起版权诉讼中的五项主张。站长网2023-08-30 11:31:340000小米申请“小米大模型” “MiLM-6B”商标
小米科技有限责任公司已申请注册多个“小米大模型”和“MiLM-6B”商标,涵盖科学仪器、网站服务、广告销售等类别,当前商标状态均为申请中。据报道,小米公司已升级其小爱同学生成式大模型,新的小爱同学将具备智能问答和文案、图片创作功能。此前,小米集团高级副总裁曾学忠表示,基于与高通和联发科的深度合作和技术交流,小米即将推出端侧AI大模型应用,相信消费者会对它感到满意。站长网2023-09-01 11:58:160000Fullpath推出首款支持Chat-GPT4的产品 专为汽车经销商设计
Fullpath推出了首款支持Chat-GPT4的产品,专为汽车经销商设计,旨在改善在线购车体验和客户关系管理。AI工具经过训练,可以将互联网的大量知识与专有的Fullpath数据层相结合,以识别经销商数据库中的特定购物者并回答经销商的特定问题。将Chat-GPT4集成到Fullpath的CDXP平台将提高在线购车体验的效率和个性化,使客户和经销商等更加方便。站长网2023-04-20 12:05:470000妇女节特辑丨每一款字体都有“她”力量 字体超市100%正版可商用
恰逢妇女节将至,如何选择一款适合妇女节海报的字体,想必这也是大多数各设计师苦恼的问题。一款好的妇女节字体不仅要能传达出节日的氛围,还要能够反映出女性的特点和力量。为此,字体超市为大家精选一波优雅大方且有力的字体,欢迎大家一起来围观!上首松羽体站长网2024-02-27 10:28:220000人工智能革命将冲击全球经济 颠覆数以百万计的工作岗位
站长之家(ChinaZ.com)8月15日消息:一场巨大的浪潮即将冲击全球经济。人工智能的崛起几十年来一直引发我们的遐想,在科幻电影和严肃的学术文献中都有所体现。尽管有这种猜测,但过去一年中公众易于使用的人工智能工具的出现却像是未来提前数年到来的震撼。现在,这场早已预料到的、却又突如其来的技术革命准备颠覆经济。站长网2023-08-15 11:46:020000