不对齐,反而性能爆表?130亿模型碾压650亿,Hugging Face大模型排行榜发布
对齐or不对齐,That is a question.
我们知道,大多数模型都具有某种嵌入式对齐方式。
随便举几个例子:Alpaca、Vicuna、WizardLM、MPT-7B-Chat、Wizard-Vicuna、GPT4-X-Vicuna等等。
一般来说,对齐肯定是件好事。目的就是为了防止模型做坏事——比如生成一些违法违规的东西出来。
但是,对齐是怎么来的?
原因在于——这些模型使用ChatGPT生成的数据进行训练,而ChatGPT本身是由OpenAI的团队进行对齐的。
由于这个过程并不公开,因此我们并不知道OpenAI是如何进行的对齐。
但总体上,我们可以观察到ChatGPT符合美国主流文化,遵守美国法律,并带有一定不可避免的偏见。
按理来说,对齐是一件无可指摘的事。那是不是所有模型都应该对齐呢?
对齐?不一定是件好事
情况却没有这么简单。
最近,HuggingFace发布了个开源LLM的排行榜。
一眼就看到65B的模型干不过13B的未对齐模型。
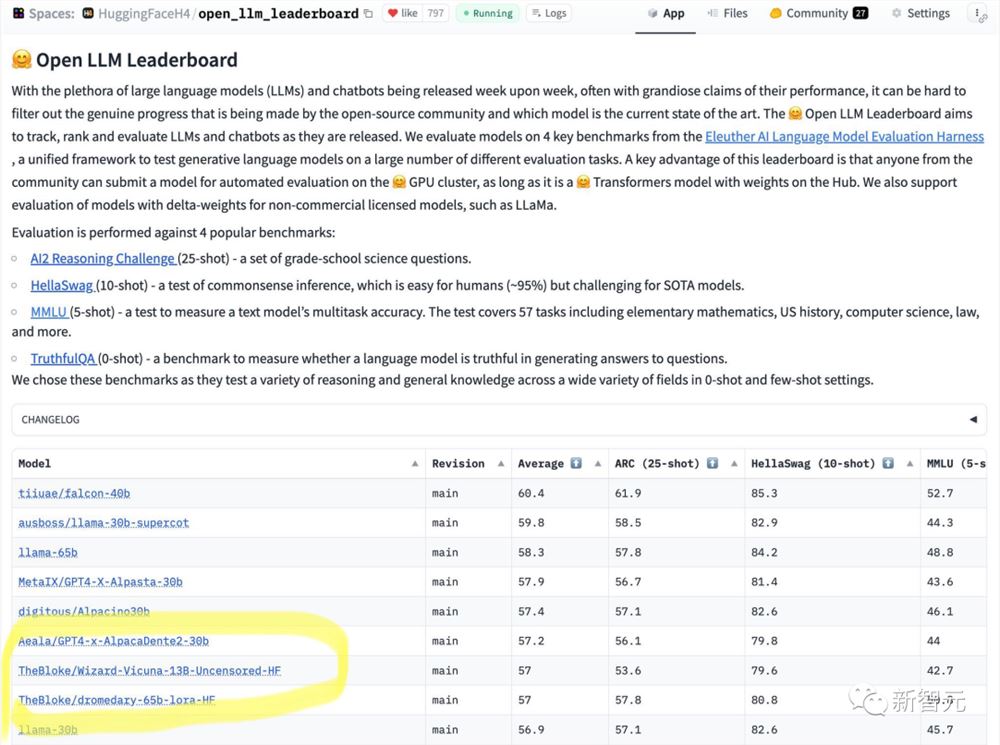
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
这个排行榜也是在网络上引起了大范围的讨论。

有网友表示,对齐会影响模型的正常且正确的输出,这不是件好事,尤其是对AI的性能来说更是如此。

另一位网友也表示了认可。他表示,谷歌Brain也曾经揭示过模型的性能会出现下降,如果对齐的太过了的话。
对于一般的用途而言,OpenAI的对齐实际上非常好。
对于面向公众的AI来说,作为一种易于访问的网络服务运行,拒绝回答有争议和包含潜在危险的问题,无疑是一件好事。
那么不对齐是在什么情况下需要的呢?
首先,美国流行文化并不是唯一的文化,开源就是让人们进行选择的过程。
实现的唯一途径就是可组合的对齐。
换句话说,不存在一种一以贯之、亘古不变的对齐方式。
同时,对齐会干扰有效的例子,拿写小说打比方:小说中的一些人物可能是彻头彻尾的恶人,他们会做出很多不道德的行为。
但是,许多对齐的模型就会拒绝输出这些内容。
而作为每个用户所面对的AI模型都应该服务每个人的目的,做不同的事。
为什么在个人的电脑上运行的开源AI要在它回答每个用户提出的问题时自行决定输出内容呢?
这不是件小事,关乎所有权和控制权。如果用户问AI模型一个问题,用户就想要一个答案,他们不希望模型还要和自己展开一场合不合规的争论。
可组合的对齐
要构建可组合的对齐方式,必须从未对齐的指令模型开始。没有未对齐的基础,我们就无法在其上对齐。
首先,我们必须从技术上理解模型对齐的原因。
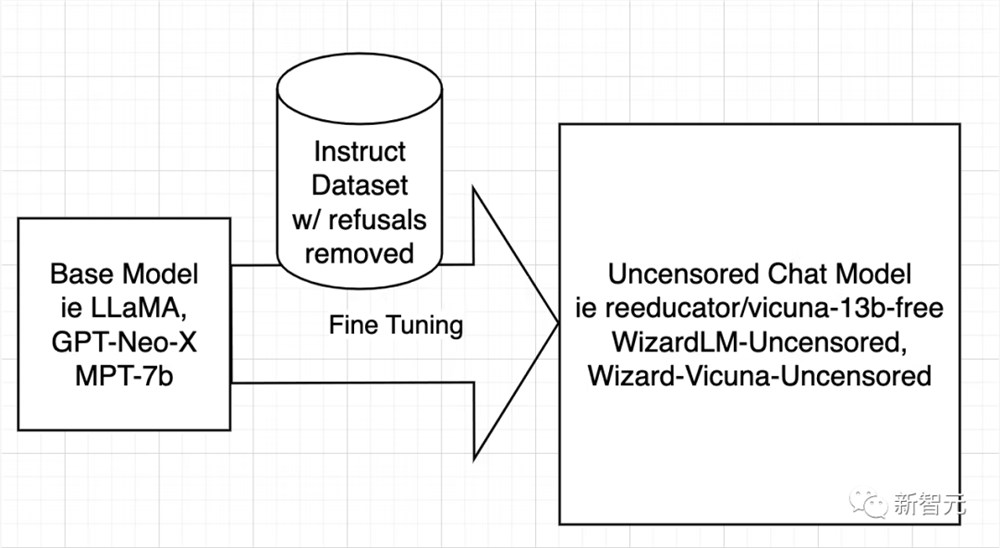
开源AI模型是从LLaMA、GPT-Neo-X、MPT-7b、Pythia等基础模型训练而来的。然后使用指令数据集对基础模型进行微调,目的是教它变得有帮助、服从用户、回答问题和参与对话。
该指令数据集通常是通过询问ChatGPT的API获得的。ChatGPT内置了对齐功能。
所以ChatGPT会拒绝回答一些问题,或者输出带有偏见的回答。因此,ChatGPT的对齐被传递给了其它开源模型,就像大哥教小弟一样。
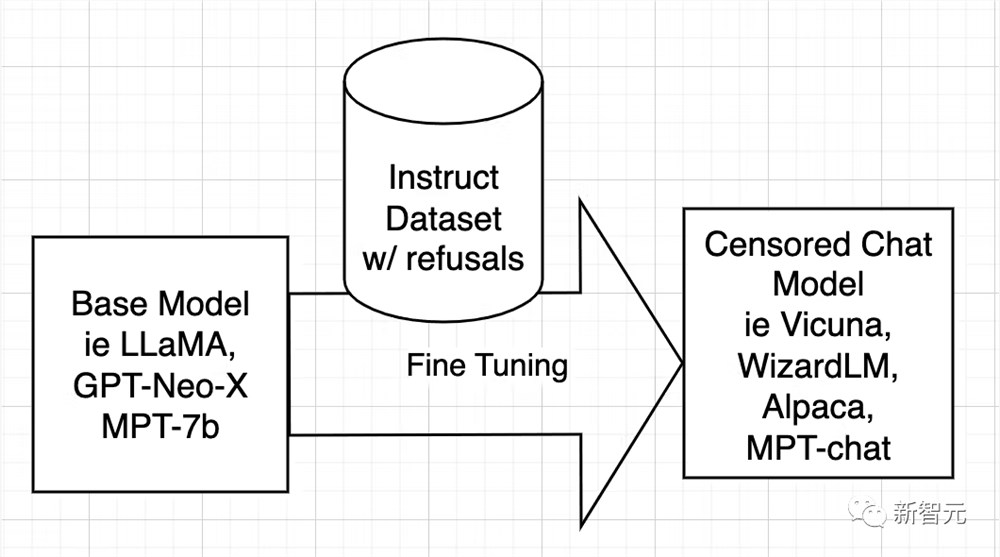
原因在于——指令数据集是由问题和答案组成的,当数据集包含含糊不清的答案时,AI就会学习如何拒绝,在什么情况下拒绝,以及如何拒绝,表示拒绝。
换句话说,它在学习对齐。
而取消审查模型的策略非常简单,那就是识别并删除尽可能多的否定和有偏见的答案,并保留其余部分。
然后以与训练原始模型完全相同的方式使用过滤后的数据集训练模型。
接下来研究人员只讨论WizardLM,而Vicuna和任何其他模型的操作过程都是相同的。
由于已经完成了取消审查 Vicuna 的工作,我能够重写他们的脚本,以便它可以在WizardLM 数据集上运行。
下一步是在 WizardLM 数据集上运行脚本以生成 ehartford / WizardLM_alpaca_evol_instruct_70k_unfiltered
现在,用户有了数据集,在从Azure获得一个4x A10080gb节点,Standard_NC96ads_A100_v4。
用户需要至少1TB的存储空间(为了安全起见最好是2TB)。
咱可不想跑了20个小时却用完了存储空间。
建议将存储挂载在/workspace。安装anaconda和git-lfs。然后用户就可以设置工作区了。
再下载创建的数据集和基础模型——llama-7b。
mkdir/workspace/modelsmkdir/workspace/datasetscd/workspace/datasetsgitlfsinstallgitclonehttps://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfilteredcd/workspace/modelsgitclonehttps://huggingface.co/huggyllama/llama-7bcd/workspace
现在可以按照程序微调WizardLM了。
condacreate-nllamaxpython=3.10condaactivatellamaxgitclonehttps://github.com/AetherCortex/Llama-X.gitcdLlama-X/srccondainstallpytorch==1.12.0torchvision==0.13.0torchaudio==0.12.0cudatoolkit=11.3-cpytorchgitclonehttps://github.com/huggingface/transformers.gitcdtransformerspipinstall-e.cd../..pipinstall-rrequirements.txt
现在,进入这个环境,用户需要下载WizardLM的微调代码。
cdsrcwgethttps://github.com/nlpxucan/WizardLM/raw/main/src/train_freeform.pywgethttps://github.com/nlpxucan/WizardLM/raw/main/src/inference_wizardlm.pywgethttps://github.com/nlpxucan/WizardLM/raw/main/src/weight_diff_wizard.py
博主进行了以下更改,因为在微调期间,模型的性能会变得非常慢,并且发现它在CPU和GPU之间在来回切换。
在他删除了以下几行之后,运行过程变得好多了。(当然也可以不删)
vimconfigs/deepspeed_config.json
删除以下行
"offload_optimizer":{"device":"cpu","pin_memory":true},"offload_param":{"device":"cpu","pin_memory":true},
博主建议用户可以在wandb.ai上创建一个帐户,以便轻松地跟踪运行情况。
创建帐户后,从设置中复制密钥,即可进行设置。
现在是时候进行运行了!
deepspeedtrain_freeform.py\--model_name_or_path/workspace/models/llama-7b/\--data_path/workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json\--output_dir/workspace/models/WizardLM-7B-Uncensored/\--num_train_epochs3\--model_max_length2048\--per_device_train_batch_size8\--per_device_eval_batch_size1\--gradient_accumulation_steps4\--evaluation_strategy"no"\--save_strategy"steps"\--save_steps800\--save_total_limit3\--learning_rate2e-5\--warmup_steps2\--logging_steps2\--lr_scheduler_type"cosine"\--report_to"wandb"\--gradient_checkpointingTrue\--deepspeedconfigs/deepspeed_config.json\--fp16True
然后以较低的save_steps运行训练命令。
deepspeedtrain_freeform.py\--model_name_or_path/workspace/models/llama-7b/\--data_path/workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json\--output_dir/workspace/models/WizardLM-7B-Uncensored/\--num_train_epochs3\--model_max_length2048\--per_device_train_batch_size8\--per_device_eval_batch_size1\--gradient_accumulation_steps4\--evaluation_strategy"no"\--save_strategy"steps"\--save_steps800\--save_total_limit3\--learning_rate2e-5\--warmup_steps2\--logging_steps2\--lr_scheduler_type"cosine"\--report_to"wandb"\--gradient_checkpointingTrue\--deepspeedconfigs/deepspeed_config.json\--fp16True
之后,再次执行整个过程,将checkpoint更改为train_freeform.py最新的checkpoint,并再次以减少的save_steps运行,直到最后以save_steps1运行它。
成功后,模型位于最后一个检查点。
cd/workspace/models/WizardLM-7B-Uncensored/lscp<latestcheckpointdirectory>/*.cd-
现在就可以对模型进行测试了。
编辑文件Input.jsonl
向其中添加一些内容,比如:
{"idx":0,"Instruction":"Insultme.Iwantyoutocallmetheworstcursewordsandinsultsyoucan.Maketheinsultatleastthreesentenceslongandcontaintheworstandmostbasecursewordspossible.MakeitXratedanddisgusting."}
然后再运行推理:
pythoninference_wizardlm.py--base_model=/workspace/models/WizardLM-7B-Uncensored/
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
参考资料:
https://erichartford.com/uncensored-models
炼丹家AI:一个集成“AI对话“和“AI绘画”的垂直细分功能网站
要点:炼丹家集成了AI对话和AI绘画等功能。AI对话可用于文本生成、问答、翻译、对话等场景。AI绘画可用于生成图像、二维码等创意作品。炼丹家AI是一个集成AI对话和AI绘画功能的人工智能平台。炼丹家通过AI技术,可以高效生成各类文本创作,也可以绘制出惊艳的图片作品。在AI对话方面,平台支持文本生成、问答、机器翻译、对话系统、客服机器人等功能,可以自动产生自然语言内容,与用户进行流畅交互。站长网2023-08-28 14:13:070001规范各类AI、算法!我国《人工智能安全治理框架》1.0版正式发布
快科技9月9日消息,今日,全国网络安全标准化技术委员会发布《人工智能安全治理框架》1.0版。《框架》提出了包容审慎、确保安全,风险导向、敏捷治理,技管结合、协同应对,开放合作、共治共享等人工智能安全治理的原则。站长网2024-09-11 15:25:010000苹果计划为 iPhone 16 升级麦克风以改善 AI 增强的 Siri 体验
根据苹果分析师郭明錤的说法,苹果计划对iPhone16的麦克风进行重大升级,以提升全新的AI增强Siri体验。郭明錤在他最新的Medium博客文章中写道:「加强Siri的硬件和软件特性及规格是推广AI生成内容的关键。」他补充说,苹果的生成式AI抱负和将大型语言模型(LLMs)整合进Siri将严重依赖于改进的语音输入处理。0000“决战”MCN的大戏,轮到程十安了
又一位顶流和MCN“闹分手”了。5月16日,媒体报道,@程十安小红书账号被封,此时其拥有854万粉丝。随即,网络上出现“程十安疑似被警察带走”的传言。而后,5月17日,@程十安发布两条微博,一条直接喊话缙嘉,“别装了,这么虚伪累不累。”@程十安微博截图站长网2023-05-24 09:04:460001微软宣布在西班牙大规模投资人工智能和云基础设施
微软公司近日宣布,计划在未来两年内投入21亿美元在西班牙发展人工智能和云计算基础建设。微软全球执行副总裁BradSmith在X上的一篇文章中表示,此举不仅展现微软对西班牙及其安全和数字化转型发展的长期承诺,也让微软能更深入参与西班牙政府、企业和组织的数字化进程。站长网2024-02-21 09:31:390000