英伟达馋哭建模师!投喂随意视频,直出3D模型,华人一作登CVPR 2023
英伟达一出手,3D建模师都馋哭了。
现在,制作一个纹理超细致的大卫3D模型,需要几步?

刚刚靠着AI,市值一度飚破万亿美元的英伟达给出最新答案:
给AI投喂一段普通视频,它就能自动搞定。

不仅雕塑的每一个褶皱都能拿捏住,更为复杂的建筑场景3D重建,同样靠一个视频就能解决:

连深度都能直接估算出来。
这个新AI名叫Neuralangelo,来自英伟达研究院和约翰霍普金斯大学。
论文刚一发表就吸引了全场网友的目光,让人直呼:这是直接创造新世界的节奏。
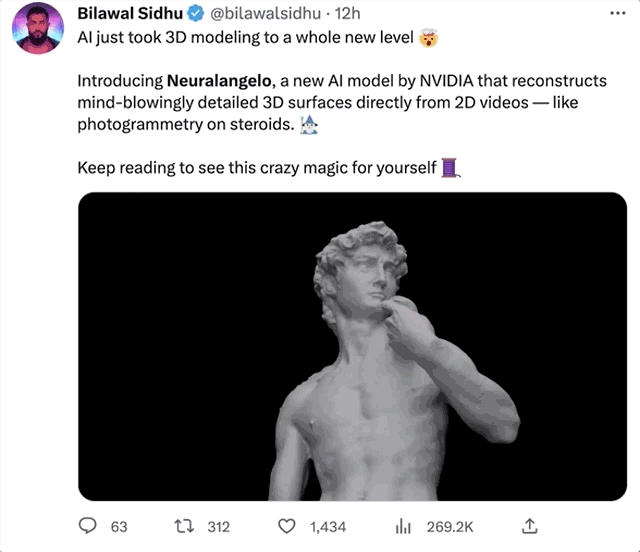

甚至再一次拉动了显卡销量【狗头】:

目前,相关论文已经入选CVPR2023。更多技术细节,我们一起接着往下看~
无需深度数据,直出3D结构
这篇论文采用的架构名叫Neuralangelo,一个听起来有点像著名雕塑家米开朗基罗(Michelangelo)的名字。

具体来说,Neuralangelo核心采用了两个技术。
一个是基于SDF的神经渲染重建。
其中,SDF即符号距离函数(Signed Distance Function),它的本质就是将3D模型划出一个表面,然后用数值表示每个点距离模型的实际距离,负数指点在表面内侧,正数指点在表面外侧:

△图源chriscummingshrg
基于SDF的神经渲染技术,则是采用神经网络(如MLP)对SDF进行编码,来对物体表面进行一个近似还原。
另一个则是多分辨率哈希编码,用于降低计算量。
多分辨率哈希编码是一种特殊的编码方式,能用很小的网络降低计算量,同时确保生成的质量不降低。
其中,多分辨率哈希表的value,对应由随机梯度下降优化得到特征向量。
操作流程上,则分为两步。
首先,基于神经渲染重建方法,计算出视频中3D结构的“粗糙表面”。
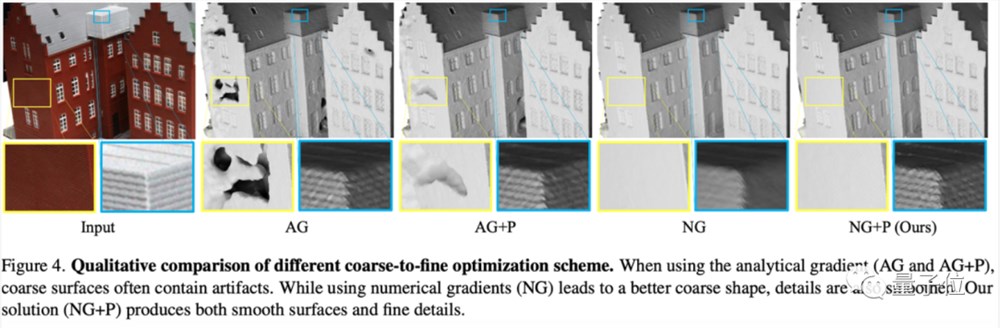
值得注意的是,这里采用了数值梯度而不是解析梯度,这样基于SDF生成算法做出来的3D模型表面更加平滑,不会出现凹凸不平的状态:

论文还额外对比了一下解析梯度和数值梯度的状态,从图中来看,数值梯度整体上能取得更平滑的建筑效果:
随后,就是逐渐减小数值梯度的步长(step size)、采用分辨率更高的哈希表,一步一步提升模型的精细度,还原建筑的细节:

最后再对生成的效果进行优化,就得到了还原出来的图像。
包含MLP和哈希编码在内,整个网络采用端到端的方式进行训练。
测试效果如何?
研究人员采用了DTU和Tanks and Temples两个数据集对Neuralangelo进行测试。
DTU数据集包含128个场景,这篇论文具体采用了其中的15个场景,每个场景包含49~64张由机器人拍摄的RGB图像。

随后,还采用了Tanks and Temples中6个场景的263~1107张RGB相机拍摄图像,真实数据则由LiDAR传感器获得。
Tanks and Temples包含中级和高级两类数据集。
其中,中级数据集包含雕塑、大型车辆和住宅规模的建筑;高级数据集则包含从内部成像的大型室内场景、以及具有复杂几何布局和相机轨迹的大型室外场景:

具体到生成细节上,Neuralangelo相比NeuS和NeuralWarp等“前SOTA”模型,在DTU数据集上展现出了非常准确的3D细节生成:
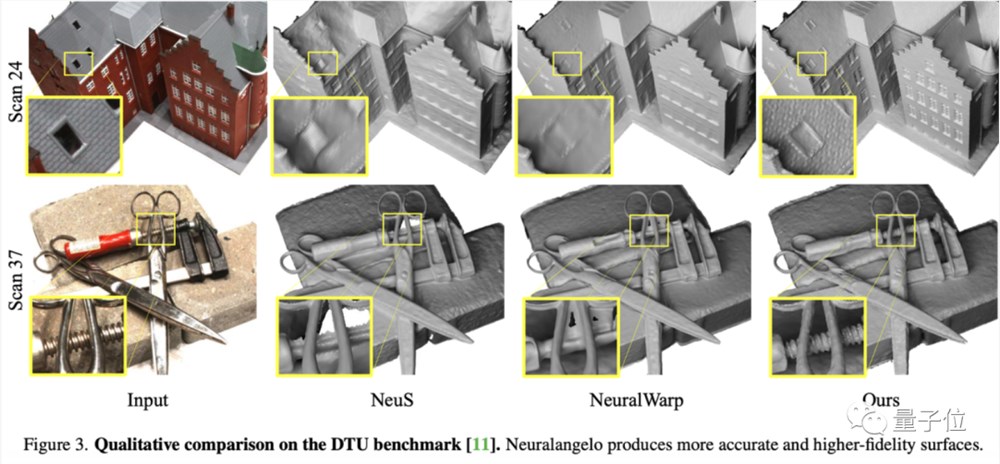
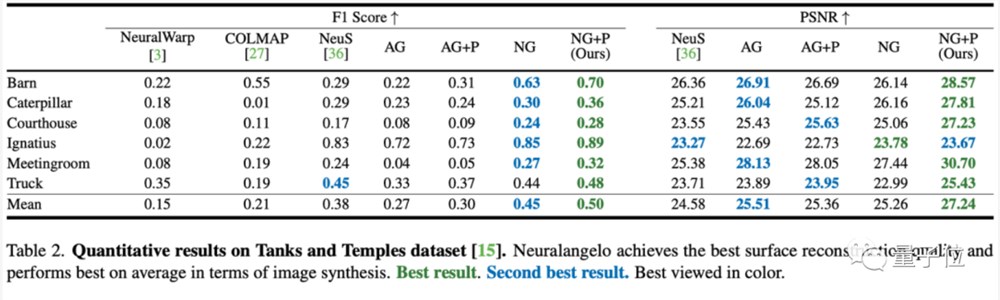
而在Tanks and Temples数据集上,Neuralangelo也同样展现出了不错的还原效果:

在F1-Score评估和图像质量PSNR评估中,Neuralangelo基本上全部取得了最好的效果:
华人一作
这篇研究的作者来自英伟达和约翰霍普金斯大学(Johns Hopkins University)。

论文一作李赵硕(Zhaoshuo Li),本科毕业于不列颠哥伦比亚大学,目前是约翰霍普金斯大学的博士生,师从Mathias Unberath和Russell Taylor。
Russell Taylor是医疗机器人领域泰斗,曾主持研发全球首台骨科手术机器人ROBDOC。
而李赵硕本人,本科专业也是机器人工程,如今算是小小跨界,研究重点在图像重建3D结构上。
Neuralangelo是李赵硕在英伟达实习期间的工作。此前,他还曾在Meta的Reality Labs实习(就是小扎All in 元宇宙的核心部门)。
论文地址:
https://research.nvidia.com/publication/2023-06_neuralangelo-high-fidelity-neural-surface-reconstruction
iPhone或终结Plus机型 iPhone16Plus将是最后一代Plus机型
分析师JeffPu透露,备受瞩目的iPhone16Plus或将成为Plus系列的最后一款机型,而明年,全新的iPhone17系列将带来一款全新的成员——iPhone17Slim。这一消息若属实,意味着Plus机型在经历了三代产品的辉煌之后,终将走向和mini系列相同的结局。这种变革背后,隐藏的是苹果对市场趋势的敏锐洞察和策略调整。站长网2024-05-20 22:10:570000问界新M5增程MAX版CLTC工况综合续航达到1440km
在今日的盛大发布会上,华为余承东隆重揭幕了全新的问界新M5车型,引起了广泛关注。这款车型不仅在设计上有所创新,更在性能上展现了卓越的都市SUV实力。站长网2024-04-23 15:52:360000特斯拉中国推出 8000 元保险补贴活动 以及现车车漆福利
特斯拉官网近日推出了“春日礼遇-限时现车福利”活动,为消费者带来三项限时优惠,包括现车保险补贴、现车车漆福利和现车金融低息方案。首先,消费者在活动期间下单订购指定版本的Model3或ModelY后轮驱动版现车,并在规定时间内完成交付,即可享受高达8,000元的保险补贴。需要注意的是,该活动仅适用于现款车型,其他版本不享受此保险补贴。0000新加坡华人团队开源全能「大一统」多模态大模型NExT-GPT
要点:1、NExT-GPT支持任意模态的输入和输出,实现了从任一模态到任一模态的转换。2、NExT-GPT通过组合开源的编码器、语言模型和解码器实现了全能的多模态能力。3、NExT-GPT实现了端到端的训练和指令微调,具有较好的多模态表示对齐能力。站长网2023-09-18 14:37:210000新研究:AI测谎能力比人类更强 但需谨慎使用
快科技7月15日消息,据媒体报道,德国维尔茨堡大学当地时间12日公布的最新研究显示,在假新闻、政治家的可疑言论和被操纵的视频日益泛滥的时代,人工智能在测谎方面的表现比人类更佳。这项发表在《iScience》期刊上的研究,精心设计了一场实验:参与者被要求撰写周末计划,并巧妙设置半数人需撒谎以换取小额金钱奖励,共收集到来自768名参与者的1536份陈述。0000