媲美OpenAI-o3,刚刚开源模型DeepCoder,训练方法、数据集大公开
今天凌晨4点,著名大模型训练平台Together AI和智能体平台Agentica,联合开源了新模型DeepCoder-14B-Preview。
该模型只有140亿参数,但在知名代码测试平台LiveCodeBench的测试分为60.6%,高于OpenAI的o1模型(59.5%),略低于o3-mini(60.9%)。在Codeforces、AIME2024上的评测数据同样非常出色,几乎与o1、o3-mini差不多。
值得一提的是,Together AI不仅开源了DeepCoder-14B模型权重,还把训练数据集、训练方法、训练日志和优化方法全部公开,帮助开发者更深度的了解这个模型所有开发流程。
开源地址:https://huggingface.co/agentica-org/DeepCoder-14B-Preview
github:https://github.com/agentica-project/rllm
DeepCoder是在Deepseek-R1-Distilled-Qwen-14B基础之上,通过分布式强化学习(RL)进行了微调。
在开发过程中,研究人员首先构建了一个高质量训练数据集,包含24K个可验证的编程问题:涵盖TACOVerified问题、PrimeIntellect的SYNTHETIC-1数据集中的验证问题等。
为了确保数据质量,通过程序验证、测试过滤和去重等步骤。程序化验证,每个问题都会使用外部官方解决方案自动进行验证。会过滤数据集,只包含官方解决方案通过所有单元测试的问题。
测试过滤,每个问题必须至少包含5个单元测试。重复数据删除,删除了数据集中的重复问题,以避免污染。
在代码强化学习训练中,DeepCoder使用了两种沙盒来运行单元测试并计算奖励。Together Code Interpreter是一个快速高效的环境,与RL训练直接兼容,成本低且可扩展性强,能够支持100多个并发沙盒和每分钟1000多个沙盒执行。
本地代码沙盒则是一个独立的、受保护的Python子进程,遵循官方LiveCodeBench仓库中的相同评估代码,确保了结果与现有排行榜的一致性。
在奖励函数设计方面,DeepCoder采用了稀疏结果奖励模型(ORM),避免分配部分奖励,从而防止模型通过奖励黑客行为来获取不准确的奖励信号。
奖励函数简单而明确:如果生成的代码通过所有采样单元测试,则奖励为1;否则为0。这种设计确保了模型能够专注于生成高质量的代码,而不是通过记忆测试用例来获取奖励。
为了实现更稳定的训练过程,DeepCoder的训练采用了GRPO ,这是对原始GRPO算法的改进版本。
通过消除熵损失和KL损失、引入过长过滤和上限裁剪等技术,GRPO 使得模型在训练过程中能够保持稳定的熵值,避免训练崩溃,并且能够更自然地生成较长的输出,从而提高了模型的推理能力。
此外,DeepCoder-14B-Preview采用了迭代上下文扩展技术,使模型能够从较短的上下文长度开始学习,然后逐步泛化到更长的上下文。该模型的上下文窗口从16K扩展到32K,最终在64K上下文中评估时达到了60.6%的准确率。
为了加速端到端的RL训练,DeepCoder团队引入并开源了verl-pipeline,这是verl的一个优化扩展。通过一次性流水线技术,DeepCoder实现了训练、奖励计算和采样的完全流水线化。
同时,奖励计算与采样交错进行,减少了奖励评估的开销。这些优化使得训练时间减少了2倍,特别是在需要运行数千个测试用例的编码任务中,显著提高了训练效率。
虽然DeepCoder刚开源但评价非常高,网友表示,这相当令人惊讶。它不仅是真正意义上的开源,而且他们还对广义信赖域策略优化算法(GRPO)进行了多项改进,并且在训练过程中为采样流水线增添了额外的效率提升。
太厉害了!等不及这款模型在Ollama平台上体验了。
圣诞节提前到来了。
传奇!开源就应该这样。
关于Together AI
Together AI成立于2022年,主打云大模型平台支持超过200种开源AI模型,包括Llama系列、DeepSeek-R1等,并优化了高速推理和模型训练的基础设施。目前拥有超过3.6万块GB200NVL72组成的超大GPU算力群。
此外,Together AI还提供模型微调、Agent智能自动化工作流和合成数据生成等,为大企业提供底层服务。
前不久,Together AI刚获得3.05亿美元的B轮融资,其估值也从去年的12.5亿美元翻倍至33亿美元。
微软未来十年人工智能领域策略:从 ChatGPT 驱动的搜索引擎到 Azure 上的 OpenAI
微软于1975年成立,自1986年上市以来,投资者一直将其视为技术行业的领导者。微软目前市值达到2.3万亿美元,是全球第二大公司,而这并非偶然。凭借对创新的持续关注,微软的Windows操作系统、文字处理软件、Xbox游戏生态系统和Azure云服务平台成为该公司数十年来不断发展的标志。站长网2023-05-16 16:47:200000刷爆朋友圈的“闻神”1天涨粉360万,抖音再“造神”普通人?
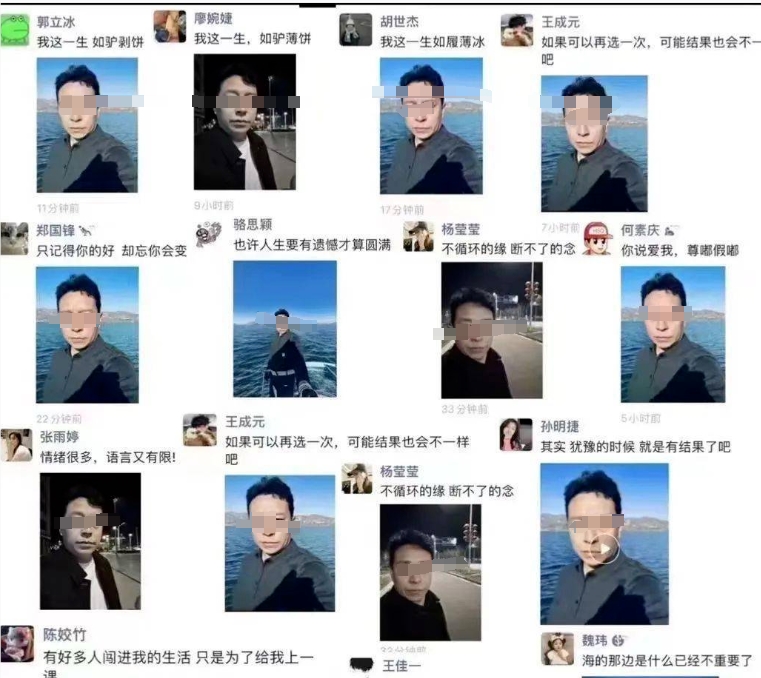
一个中年男人的怼脸自拍照,在朋友圈刷屏了。你可能没有叔的微信,但微信里一定全是叔的照片和语录。他穿着深色衬衫,发丝还有些许凌乱,一脸严肃正气,搭配上着emo文案比如“我这一生,如履薄冰”“不循环的缘,断不了的念”,一跃成为新一代社交媒体顶流,一天连登四个微博热搜。这个中年男人叫闻会军,来自河北石家庄,表面看起来只是个普通的驾校教练,实际在抖音上有三个不同身份状态:站长网2023-12-20 15:52:130000Hugging Face 发布医疗任务评估基准Open Medical-LLM
划重点:⭐️HuggingFace发布了一个新的医疗任务评估基准,旨在测试生成式人工智能模型在健康相关任务上的表现。⭐️OpenMedical-LLM基准由现有测试集拼接而成,涵盖多个医学领域,如解剖学、药理学、遗传学和临床实践。站长网2024-04-19 11:44:570000首个获得驾照的AI!Agent担任私人助理样样精通,还能帮助考试作弊
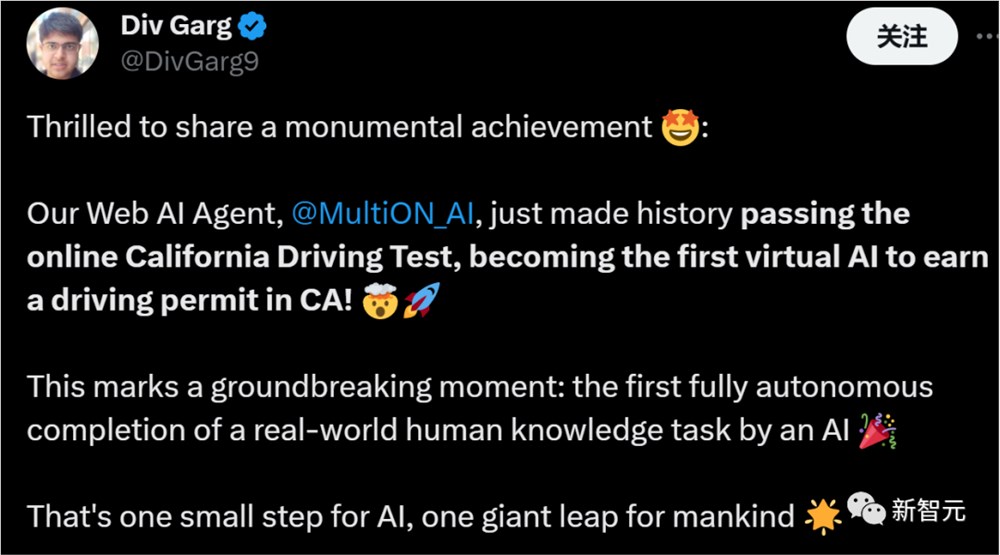
关于当前基于Transformer的LLM能走多远的问题,人们仍在争论不休。与此同时,另一边,能够帮助人们处理各项工作的AIAgent已经悄然走入人们的生活。以前的ChatGPT等大模型,热衷于在人类考试中刷分以凸显自己的实力,而不久前,又有一位AIAgent通过了美国加州的驾照考试。——但与之前不同的是,这次的AIAgent是在监考员的眼皮底下帮助人类成功作弊,通过考试!站长网2023-11-29 17:52:050001阅文收购腾讯动漫背后的三点思考
12月11日,阅文集团宣布将收购腾讯动漫相关资产,其中包括腾讯动漫APP平台、其作品知识产权与相关权利、以及动画和影视项目等,总对价为人民币6亿元现金。一石激起千层浪,一方是从网络文学发源一路生长成IP生态的集大成者,一方是同样以IP为核心的动漫赛道担当,两者的携手势必对创作者生态、行业市场以及产业上下游产生深远的影响。0000