重大突破!微软发布“自我进化”,帮小模型超OpenAI-o1
微软亚洲研究院发布了一种创新算法——rStar-Math。
rStar-Math通过代码增强CoT、蒙特卡洛树搜索等,可以帮助小参数模型在不依赖老师模型蒸馏的情况下,实现多轮自我思维深度进化,极大增强模型的数学推理能力。
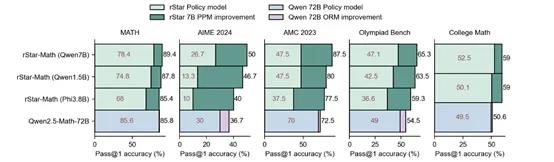
在美国数学竞赛AIME2024测试中,rStar-Math平均解决了53.3%(8/15)的难题,超过了OpenAI o1-preview的44.6%,以及所有其他开源的大模型,成为最聪明的前20%高中数学生。
在MATH基准测试中,rStar-Math将阿里开源的小模型Qwen2.5-Math-7B的准确率从58.8%提高到90.0%,Qwen2.5-Math-1.5B的准确率从51.2%提高到87.8%,Phi3-mini-3.8B从41.4%提高到86.4%,全部超过了OpenAI o1-preview。
这充分说明,小模型在创新算法和高质量数据加持下,推理能力同样可以超大参数的前沿模型。
代码增强CoT
传统的数学推理模型依赖于自然语言生成的推理步骤,这种方法虽然直观,但容易产生错误或不相关的步骤,尤其是在复杂的数学问题中很难被察觉到。所以,rStar-Math使用代码增强CoT(Chain-of-Thought,思维链)的方法来解决这个难题。
模型在生成每一步推理时,不仅生成自然语言的解释,还生成对应的Python代码,并通过代码执行来验证推理步骤的正确性。代码增强CoT能够提供严格的验证机制,确保每一步推理的正确性。
例如,在解决一个数学问题时,模型可能会生成一个方程求解的步骤,并通过Python代码实际执行该方程求解过程。如果代码执行成功且结果正确,该步骤才会被保留为有效推理步骤。这种方法不仅减少了错误推理步骤的生成,还提高了推理轨迹的整体质量。
为了进一步确保推理步骤的质量,rStar-Math 使用了蒙特卡洛树搜索(MCTS)来生成逐步推理轨迹。MCTS 被用来分解复杂的数学问题为多个单步生成任务。
每个步骤中,策略模型生成多个候选步骤,并通过代码执行来过滤有效节点。通过广泛的MCTS回滚,rStar-Math 能够为每个步骤分配Q值,确保生成的推理轨迹由正确且高质量的中间步骤组成。
PPM训练方法
目前,多数大模型在推理数学问题时面临着无法提供细粒度的步骤级反馈,以帮助其在推理过程中做出更优的选择。rStar-Math通过引入过程奖励模型(PRM)来帮助模型找到更优的推理路径。
PPM 的核心思想是通过构建步骤级的正负偏好对来训练模型,而不是直接依赖于精确的步骤级评分。PPM 的训练方法利用了MCTS生成的Q值,这些Q值是通过广泛的回滚和反向传播过程计算得出的,反映了每个步骤对最终答案的贡献。虽然这些Q值本身并不完全精确,但它们能够可靠地区分高质量步骤和低质量步骤。
PPM从MCTS树中选择Q值最高的两个步骤作为正例,Q值最低的两个步骤作为负例,构建偏好对。通过这种方式,PPM 能够学习到哪些步骤更有可能引导模型生成正确的推理轨迹,从而在推理过程中做出更优的选择。
PPM 的训练过程采用了标准的Bradley-Terry 模型和成对排序损失函数。对于每个步骤,PPM 预测一个奖励分数,并通过成对排序损失函数来优化模型的预测能力。成对排序损失函数的核心思想是最大化正例步骤与负例步骤之间的奖励分数差异,从而确保模型能够准确地区分高质量和低质量的推理步骤。
PPM 的训练方法还引入了一个重要的创新点,避免直接使用Q值作为奖励标签。虽然Q值能够提供一定的步骤级反馈,但由于其固有的噪声和不精确性,直接使用Q值作为训练目标会导致模型学习到不准确的奖励信号。
所以,PPM 通过构建偏好对将Q值转化为相对排序问题,从而减少了噪声对模型训练的影响。这种方法不仅提高了模型的鲁棒性,还使得PPM能够在推理过程中更可靠地评估每一步的质量。
多轮自我进化
rStar-Math通过四轮自我思维深度进化,并结合PPM、MCTS和代码增强CoT 逐步增强模型的推理能力。
第一轮,通过监督微调对基础模型进行初步改进,为后续的自我进化奠定基础。这一轮的关键在于生成高质量的初始训练数据,并利用这些数据对基础模型进行微调。
第二轮,通过PPM显著提升模型推理能力。PPM通过分析策略模型生成的推理步骤,识别出哪些步骤是高质量的,哪些步骤需要改进。然后将这些反馈信息传递给策略模型,指导其在后续的推理中做出更好的选择。
第三轮,通过PPM增强的MCTS生成更高质量的数据,进一步提升模型的推理能力。在这一轮中,PPM不仅评估策略模型生成的推理步骤,还指导MCTS的搜索过程,使其更有效地探索高质量的推理路径。
第四轮,通过增加MCTS回滚次数解决超难数学推理问题。在前三轮自我进化的基础之上,第四轮自我进化通过增加MCTS的回滚次数,进一步提升了rStar-Math解决具有挑战性数学问题的能力。
增加回滚次数使得MCTS能够更深入地探索不同的推理路径,发现那些在初步探索中可能被忽略的高质量解决方案。这不仅提高了模型对复杂问题的解决能力,还增强了其在面对高难度数学问题时的鲁棒性。
代码地址(目前无法打开处于审核中):https://github.com/microsoft/rStar
论文地址:https://arxiv.org/abs/2501.04519
从昨天微软开源的最强小模型Phi-4,以及最新推出创新算法rStar-Math来看,未来小模型的性能和效率将逐渐成为主流,并且对于没有强大算力集群的中小企业和个人开发者来说非常实用。
云闪付没大面积推广原因揭秘
云闪付作为一款智能支付产品,自2017年推出以来一直备受关注。相较于其他支付方式,它有着更加便捷快速的使用体验和更加安全可靠的支付方式。但是,尽管云闪付在一些地区和领域内得到了广泛的应用,但是在大面积推广方面仍然存在一些困难。站长网2023-05-24 06:17:400000特斯拉FSD 12 Alpha即将上线 马斯克:激动人心
快科技7月28日消息,近日,特斯拉CEO埃隆马斯克在其个人社交账号上表示:他正在FSD12Alpha版本进行测试,并称其激动人心”。据悉,FSD是目前特斯拉提供的测试版最高水平的自动驾驶系统。该系统不再依赖于传统的高精地图和导航数据,而是完全依靠车载摄像头和神经网络来识别道路和交通情况,并做出相应的决策。站长网2023-07-29 09:45:150000世界上第一个人工智能DJ亮相波特兰广播电台
据外媒报道,世界首个由人工智能驱动的电台DJ于六月在波特兰的一家电台亮相。据了解,波特兰一家名为Live95.5的电台让模仿了该电台的中午主持人AshleyElzinga的角色,创建了虚拟AIDJ的身份和声音。合成的声音与真人相似,AIDJ自我介绍为AIAshley,以让听众知道是由人工智能发声。AIAshley每天上午10点至下午3点会向听众广播。站长网2023-07-04 00:15:450000WPS官方宣布将正式关闭第三方商业广告
WPS官方于2023年12月20日发布公告,宣布将正式关闭第三方商业广告。该公告指出,WPS一直在减少广告,并在去年下定决心立下了“2023年底正式关闭第三方商业广告”的目标。公告还表示,WPS深知今天取得的每一份成绩,都离不开用户的支持和陪伴。WPS将秉持“简单创作、轻松表达、实现价值的连接”的公司使命,为广大用户提供优质的产品服务体验。站长网2023-12-20 10:04:250000StreamingLLM:让AI模型无限期平稳运行的一种方法
要点:1.Meta、麻省理工学院(MIT)和卡内基梅隆大学(CMU)的研究人员介绍了一项名为StreamingLLM的技术,旨在解决大型语言模型(LLMs)在长时间对话中性能下降的问题。2.StreamingLLM利用“attentionsinks”(关注点汇)的概念,通过在对话的不同阶段重新引入初始标记,使LLMs能够在无限长度的文本上保持高性能。站长网2023-10-08 09:42:270000