不做Sora背后:百度的多模态路线是什么?
当ChatGPT掀起国内“百模大战”,百度率先交卷文心一言。
Sora再掀视频生成风潮,却传出李彦宏内部讲话“Sora无论多么火,百度都不去做”。
一时间,困惑、不解、争议,纷至沓来。
面对这些声音,在刚刚结束的百度世界大会会后采访中,李彦宏公开回应。
他不仅重申了不做Sora的决定,并且说明了百度是如何运用和发展多模态的。
在大会发布中,李彦宏发布了百度从年初开始重点攻克的iRAG技术,这项技术旨在解决AI领域最棘手的”幻觉”问题。有趣的是,这个开始正好是在Sora风正热之时。
百度的选择背后原因,到底是什么?
图源备注:图片由AI生成,图片授权服务商Midjourney
加速解决幻觉问题
先从iRAG技术看。它所解决的是图片生成的幻觉问题。
在年初,不做Sora,转头将资源放在幻觉解决上。为什么?
结合这届百度世界大会主题“应用来了”来理解:
幻觉已经成为制约大模型应用大规模落地的一大绊脚石。
现代社会对计算器已有绝对的信任,只要保证输入是对的,就可以百分百放心地把计算结果用到下一步工作流程中。
但对于已知可能存在幻觉的大模型来说,还敢给予同等的信任吗?
有幻觉,即意味着模型行为不完全可控,不能完全放心的自动化工作流程,依然需要人工介入。
AI应用正面临这样的困境。
事实上,ChatGPT问世之后,大模型的几个主要改进方向都是通过不同方式来解决大模型幻觉问题。
长上下文窗口,让模型获取更完整的输入,减少因信息不全产生的错误推理。
RAG(检索增强生成),检索外部知识库补充信息,弥补模型参数存储知识的不足。
联网搜索,获取实时、动态的在线信息,扩展模型的知识边界。
慢思考,通过分步推理减少直觉性错误,提高推理过程的可解释性。
甚至从某种意义上说,多模态技术也是让模型多一种信息输入途径,不用在“看不见”视觉信息的情况下为了完成任务凭空编造。
……
所以再次总结一下,为什么解决幻觉问题是目前AI行业的当务之急?
从技术层面,不解决幻觉问题就难以预测和控制模型的行为边界。
从应用的角度来看,幻觉问题阻碍了用户对AI产品的信任。
从产业角度,解决了幻觉问题才能扩大AI可应用的场景范围,提高AI系统的商业价值。
再将目光转向百度,解决AI幻觉问题,恰恰也是百度的“主战场”。
iRAG,全称Image-based Retrieval-Augmented Generation,是一种全新的检索增强文生图范式,结合了百度多年的搜索积累,帮助大幅提升图片的生成可控性和准确性。
其核心是将百度搜索的亿级图片资源与文心大模型的生成能力相结合,通过联合优化,让生成图片更加真实可信。
具体而言,iRAG先利用检索模块在海量图库中找出与文本描述最相关的若干图片,然后提取其视觉特征,与文本特征一并输入到生成模块。生成模块在此基础上,对图像进行理解、重组、创新,最终输出高质量、符合需求的全新图片。
可以说,iRAG巧妙地将认知智能(检索)与生成智能(创作)结合在一起,取长补短,相得益彰。
一方面,海量图像的参考让生成更”接地气”,大幅减少了幻觉、违禁内容等问题。
另一方面,强大的生成能力让输出图片更多样、更具创意,远非单纯的拼贴、修改那么简单。
更重要的是,iRAG在诸多行业领域都具有广阔应用前景,尤其能显著降低AI生图的创作成本。比如在影视制作、动漫设计中,iRAG可实现从文本脚本直接生成高质量的分镜、概念图,大幅减少中间环节的人工干预。
多模态,不止Sora一条路
明确了幻觉问题是AI行业的优先级,百度还需要回答另一种质疑:多模态已经是公认迈向AGI的重要一步。
多模态有助于增强AI系统的感知和理解能力。通过处理视觉、语音、文本等不同模态的信息,AI可以更全面地感知环境,增强其认知和交互能力,与人类通过多种感官认知世界保持一致。
但这里要明确的是,Sora路线并不能代表多模态技术的全部。
首先,投入做Sora代表的通用视频生成模型投入的成本非常高昂。市场研究机构Factorial Funds报告估算,Sora模型至少需要在4200~10500块英伟达H100GPU上训练1个月。而如果Sora得到大范围应用,为了满足需求,需要约72万张Nvidia H100GPU,如果按照每片英伟达H100AI加速卡3万美元成本计算,72万片需要216亿美元。
而目前通用视频生成模型在技术成熟度上距离iPhone时刻也还有较远的距离。此前与艺术家合作短片《Air Head》后来就被指出实际有大量人工参与,估算只有约1/300的AI素材用到了最终成片里。
△图源fxguide.com
目前市场视频生成应用从短剧内容生产到影视特效制作,很多努力都在摸索视频生成技术的想象空间,但尚未形成成熟的商业化方案和稳定的营收模式。
其实,对于做多模态来说,也存在Sora之外的多种路径。
Meta首席科学家、图灵奖得主Yann LeCun就一直坚持“世界模型”路线。他认为生成视频的过程与基于世界模型的因果预测完全不同,通过生成像素来对世界进行建模是一种浪费,注定会失败。
斯坦福教授李飞飞则看重具身智能,她认为AI仅仅看是不够的,“看,是为了行动和学习”。比如通过大语言模型,让一个机器人手臂执行任务,打开一扇门、做一个三明治以及对人类的口头指令做出反应等。
百度对多模态技术的理解,最近也在数字人场景得到集中体现。
百度从2019年起就开始布局数字人领域,涉及语音克隆、唇形同步、表情动作捕捉等一系列关键技术。到如今百度“曦灵”数字人、“慧播星”数字人已广泛应用于新闻播报、直播电商等场景。
正如李彦宏强调的,百度不做Sora,并不意味着在多模态赛道上缺席了。
数字人语音与口型、动作的同步问题,或许最终可以靠通用场景下的视频生成实现,但需要很长时间,成本很高。
但既然可以用更简单、成本更低的方法做到,为什么不先把业务跑起来呢?
首先,通用方案追求”大而全”,试图用单一模型覆盖所有场景,但这在技术上尚不成熟,往往带来效果的参差不齐;而数字人聚焦特定垂直领域,可以更精准地优化模型,追求极致的人机交互体验。
其次,视频生成好就是固定的素材了,缺乏实时交互能力;而AI驱动的数字人却可以实现动态多轮对话,甚至还可以根据用户反馈实时调整状态,更加契合真实应用的需求。
最后,视频生成对算力和数据的要求极高,当前能够真正驾驭的企业凤毛麟角,商业化进程困难重重;相比之下,数字人技术门槛相对较低,且应用场景清晰,更容易形成可复制的商业模式,开启数据飞轮。
AI大规模落地需要什么条件?
不论是投入解决图片幻觉问题,还是从业务需求出发发展多模态的路线,百度的目标似乎都围绕着李彦宏所说的:让技术被更多人用起来。
李彦宏这段时间不断强调的一个观点是“模型本身不产生直接价值”,只有在模型之上开发各种各样应用,在各种场景找到所谓的PMF,才能真正产生价值。
百度需要做的,是为个人和企业提供开发应用的基建,帮助更多人、更多企业打造出数百万“超级有用”的应用。
长远来看,幻觉问题的解决为行业应用消除了障碍,使得AI技术能够在更广泛的领域得到应用和推广。
用业务需要的多模态技术支持业务先跑起来,能让更多的AI应用场景为大家所用。
同时,大量的行业应用所产生的数据,又能为AGI的发展提供丰富的养分,形成良性循环,推动数据飞轮的高速运转,从而加快我们迈向AGI的步伐。
做小红书必知的50个专业名词,建议收藏!
近年来小红书发展迅猛,月活用户达到2.6亿。越来越多的商家和个人开始重视起小红书,想要入局挖掘红利。在这样的行业背景下,各类岗位应运而生。对于从事小红书相关工作的人来说,熟悉各种专业名词更是基础中的基础。掌握这些名词不仅有助于更好地理解和应用相关概念,还能提高与同行和合作伙伴之间的沟通效率。今天,我将总结出小红书中的50个高频词汇,我建议你将它们先收藏起来,作为参考资料,随时查阅。站长网2023-05-31 21:02:410000“AI训练师”培训,盯上小城市
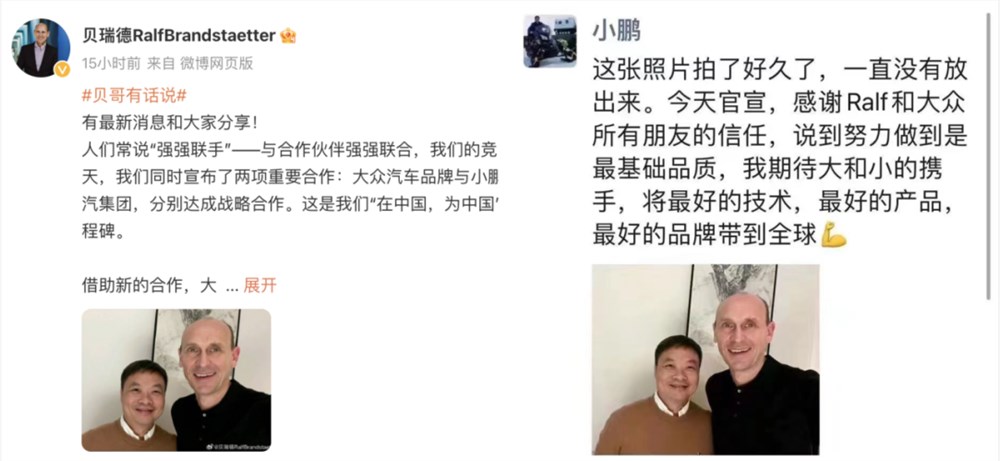
家处某二线城市的明明,在当地一所普通高校就读,还有一年就要大学毕业的他,害怕毕业后不好找工作,最近花了2万多元在当地培训机构报名了“AI训练师”的课程。AI训练师指“使用智能训练软件,在人工智能产品实际使用过程中进行数据库管理、算法参数设置、人机交互设计、性能测试跟踪及其他辅助作业的人员”,可以简单理解为,所有与AI训练相关的职业,这一职业,在2020年被纳入国家职业分类目录。0000大众给小鹏交了50亿学费
一夜之间,大众汽车将小鹏变成了“大鹏”。美东时间7月26日美股收盘,小鹏汽车股价暴涨26.69%,总市值一夜增加约35亿美元,来到168.48亿美元的近一年新高。小鹏能够取得上述成绩,都得拜大众汽车送上的一份大礼包所赐。7月26日晚,大众汽车发布公告,宣布将联合小鹏开发两款B级纯电动汽车车型,预计于2026年以大众汽车品牌在中国市场销售。站长网2023-07-27 16:50:270000用了两天最近很火的Dia,我们看到了AI浏览器的新范式
最近,AI浏览器界又冒出一位新贵:Dia。Dia受到关注,不仅仅是因为产品本身,更因为其背后的明星操盘手——TheBrowserCompany,也就是那个曾打造出Arc浏览器的团队。Arc浏览器首页虽然Arc没有进入中国市场,也没做大规模用户营销,但硅谷创投圈和极客社群中,Arc是话题度非常高的圈层爆款,吸引了上百万高粘性用户,曾一度被很多人称为“下一代浏览器范式”。0000