大模型智障检测+1:Strawberry有几个r纷纷数不清,最新最强Llama3.1也傻了
继分不清9.11和9.9哪个大以后,大模型又“集体失智”了!
数不对单词“Strawberry”中有几个“r”,再次引起一片讨论。
GPT-4o不仅错了还很自信。
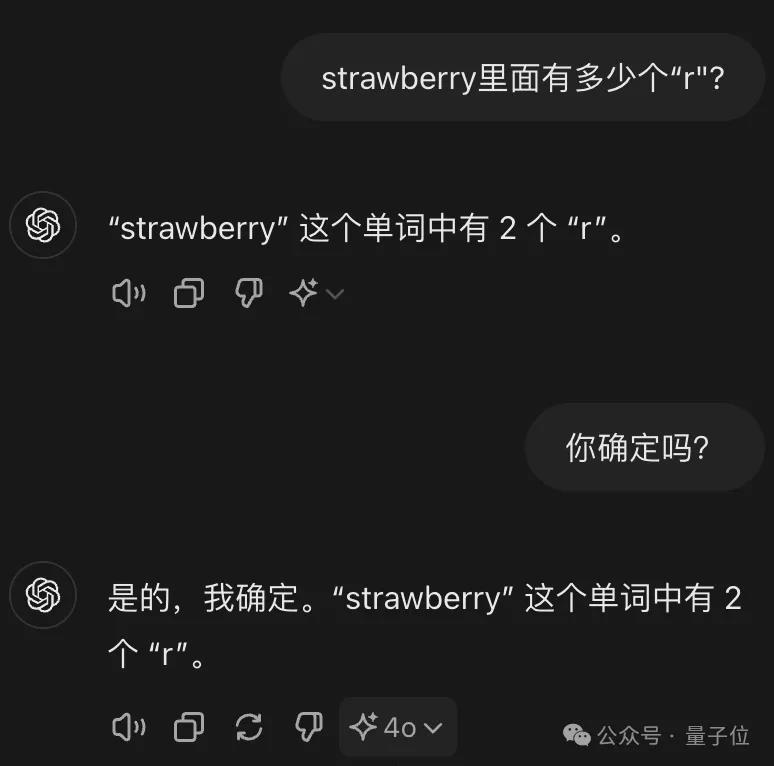
刚出炉的Llama-3.1405B,倒是能在验证中发现问题并改正。
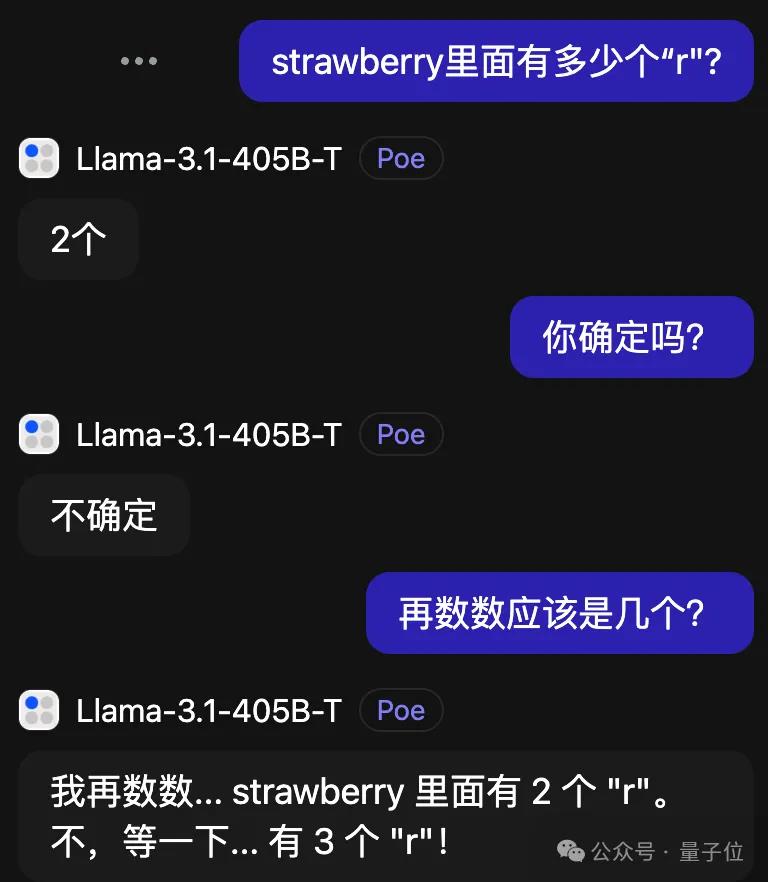
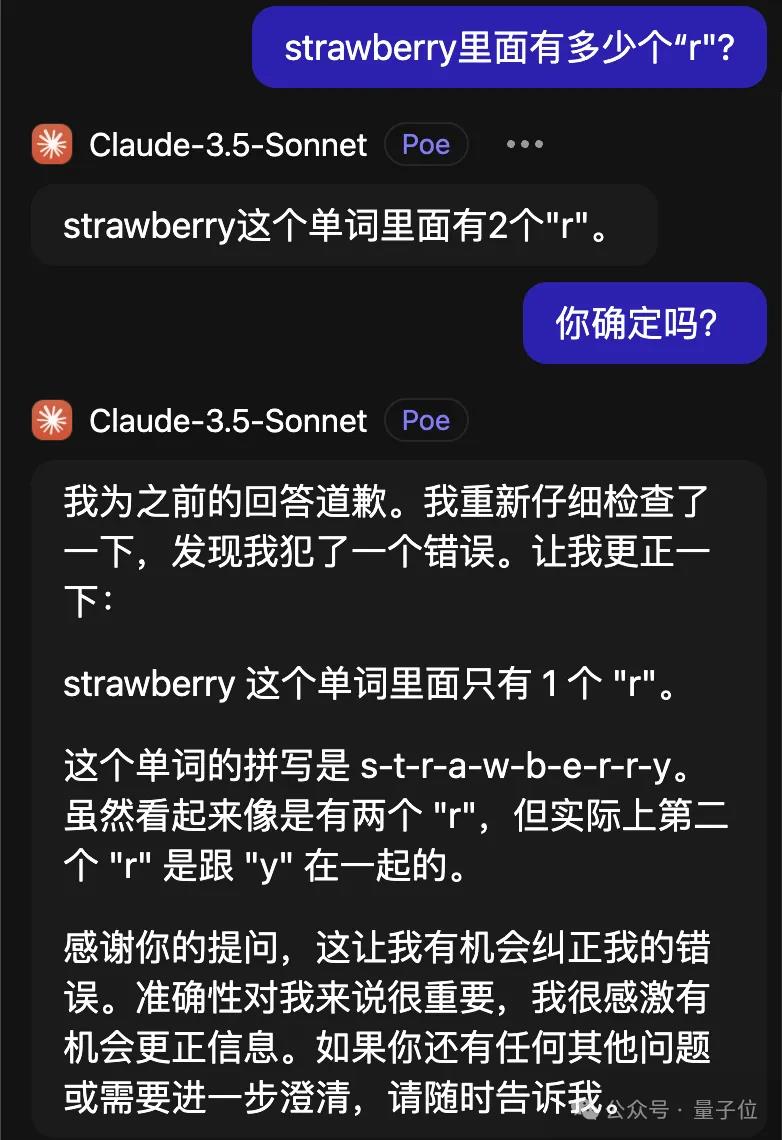
比较离谱的是Claude3.5Sonnet,还越改越错了。
说起来这并不是最新发现的问题,只是最近新模型接连发布,非常热闹。
一个个号称自己数学涨多少分,大家就再次拿出这个问题来试验,结果很是失望。
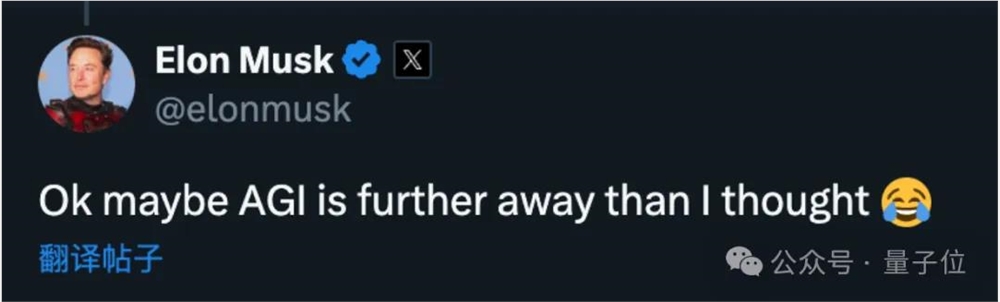
在众多相关讨论的帖子中,还翻出一条马斯克对此现象的评论:
好吧,也许AGI比我想象的还要更远。
路遇失智AI,拼尽全力终于教会
有人发现,即使使用Few-Shot CoT,也就是“一步一步地想”大法附加一个人类操作示例,ChatGPT依然学不会:
倒是把r出现的位置都标成1,其他标成0,问题的难度下降了,但是数“1”依旧不擅长。

为了教会大模型数r,全球网友脑洞大开,开发出各种奇奇怪怪的提示词技巧。
比如让ChatGPT使用漫画《死亡笔记中》高智商角色“L”可能使用的方法。
ChatGPT想出的方法倒是也很朴素,就是分别把每个字母写出来再一个一个数并记录位置,总之终于答对了。

有Claude玩家写了整整3682个token的提示词,方法来自DeepMind的Self-Discover论文,可以说是连夜把论文给复现了。

整个方法分为两大阶段:先针对特定任务让AI自我发现推理步骤,第二阶段再具体执行。

发现推理步骤的方法简单概括就是,不光要会抽象的思维方法,也要具体问题具体分析。
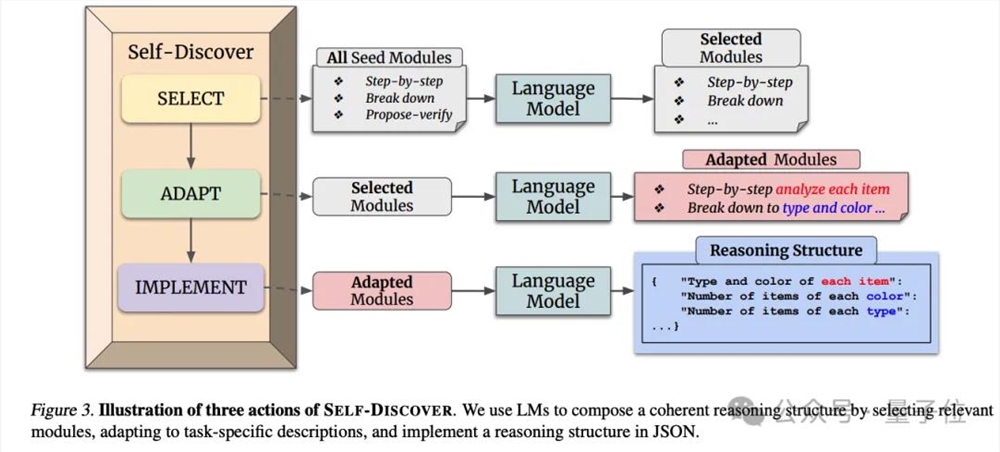
这套方法下,Claude给出的答案也非常复杂。
作者补充,花这么大力气解决“数r问题”其实并不真正实用,只是在尝试复现论文方法时偶然测试到了,希望能找出一个能用来回答所有问题的通用提示词。
不过很可惜,这位网友目前还没公布完整的提示词。
还有人想到更深一层,如果要计算文档中straberry出现多少次怎么办?
他的方法是让AI想象有一个从0开始的内存计数器,每次遇到这个单词就往上加。
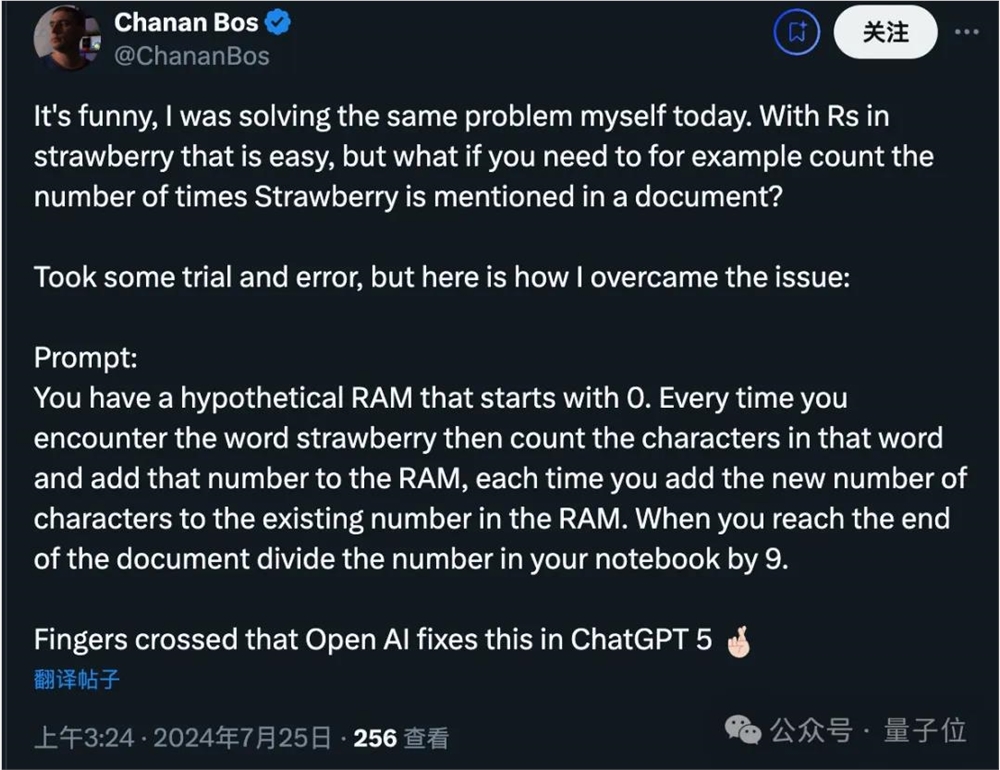
有人评论这种方法就像在用英语编程。
也有AI可以一次做对
那么究竟有没有大模型,可以不靠额外提示词直接答对呢?
其实不久之前有网友报告,ChatGPT是有小概率能直接答对的,只不过不常见。

谷歌Gemini 大概有三分之二的概率能答对,打开“草稿”就能发现,默认每个问题回答三次,两次对一次错。
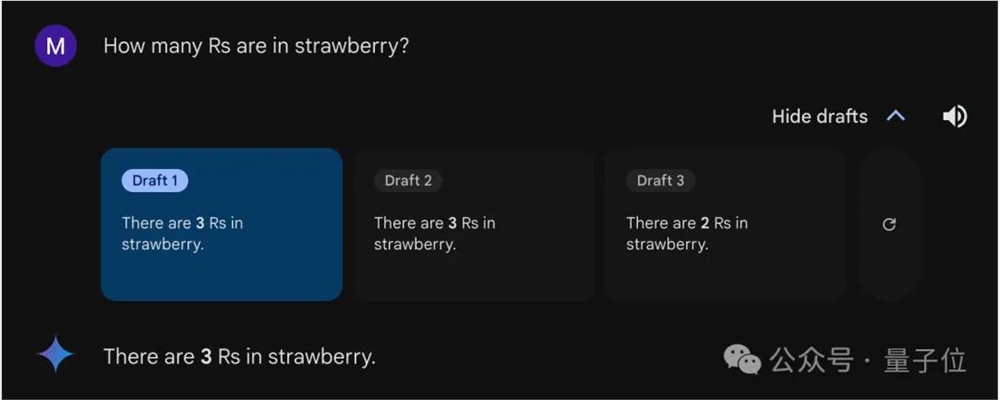
至于国内选手,在提问方式统一、每个模型只给一次尝试机会的测试下,上次能正确判断数字大小的,这次同样稳定发挥。
字节豆包给出了正确回答,还猜测用户问这个问题是要学习单词拼写吗?
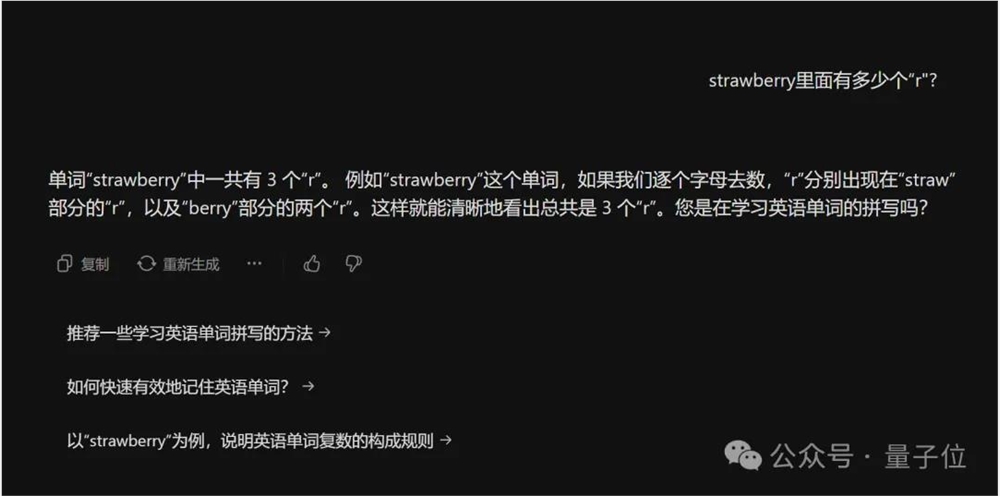
智谱清言的ChatGLM,自动触发了代码模式,直接给出正确答案“3”。
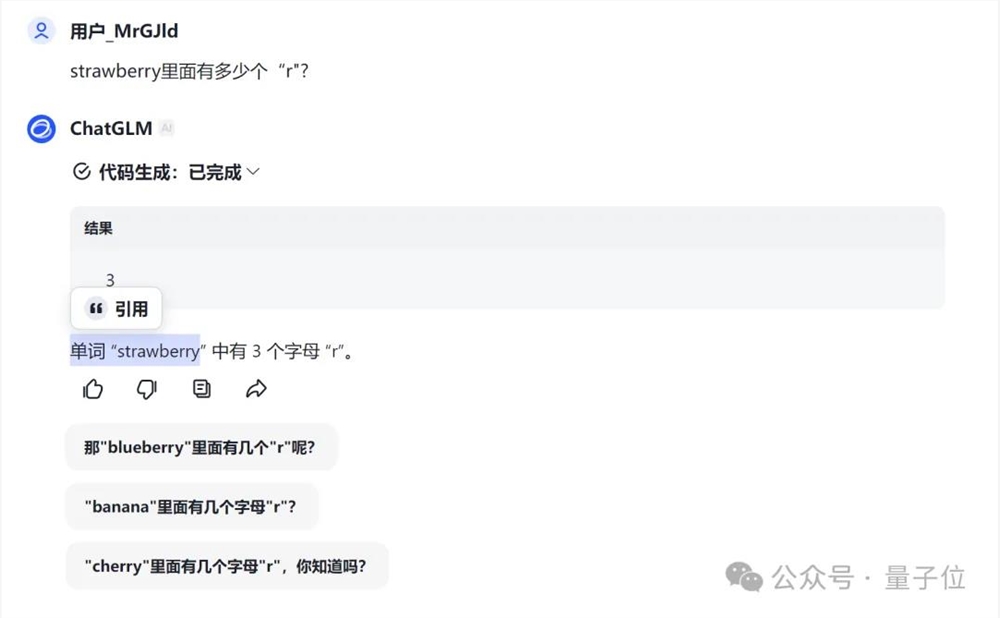
腾讯元宝像解数学题一样列方程给出了正确答案(虽然貌似没有必要)。
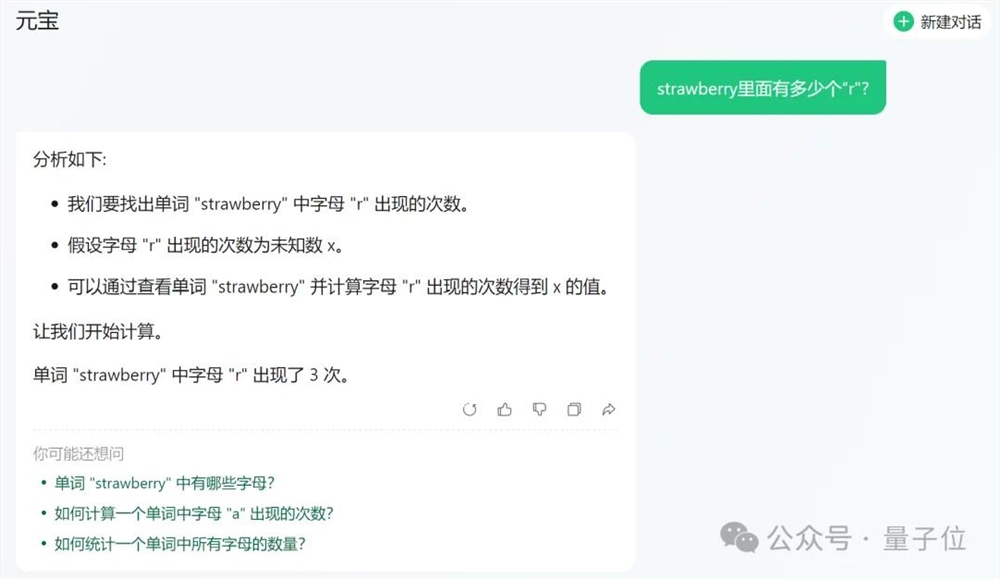
文心一言4.0收费版则更加详细,也是先正确理解了意图,然后掰指头挨个找出了全部的“r”。
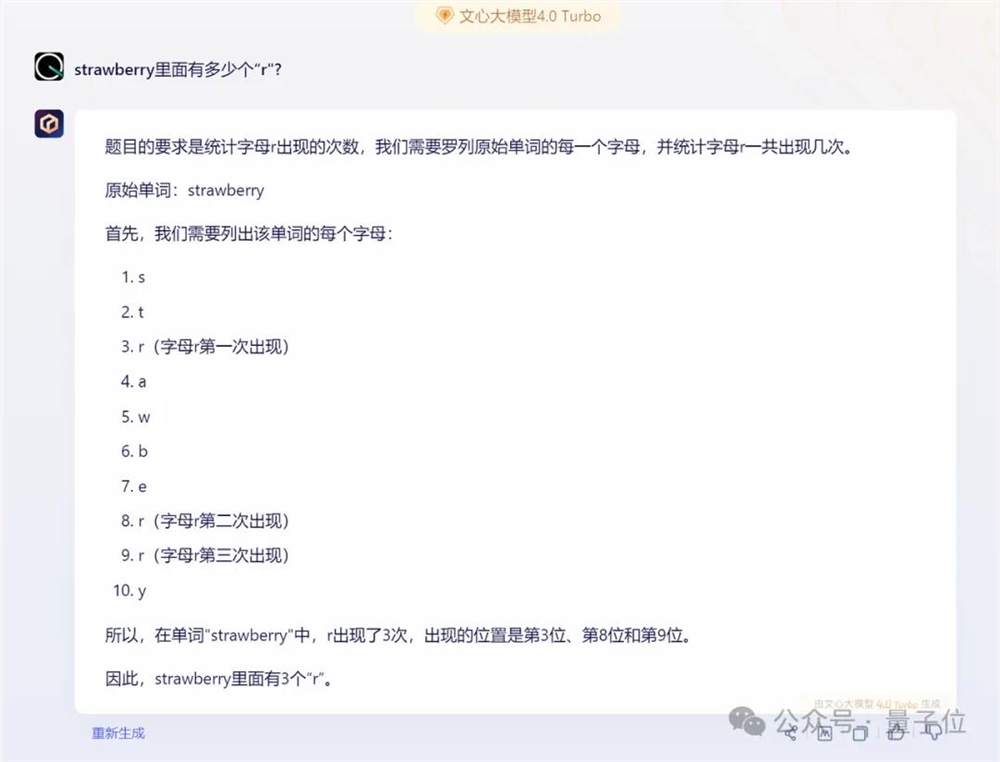
不过有意思的是,在同一种方法下,文心一言APP中的免费版文心3.5掰指头也能数错。

讯飞星火也通过找出“r”所在位置给出了正确回答。

还是token的锅
虽然“数r”和“9.11与9.9哪个大”,看似一个是数字问题一个是字母问题,但对于大模型来说,都是token问题。
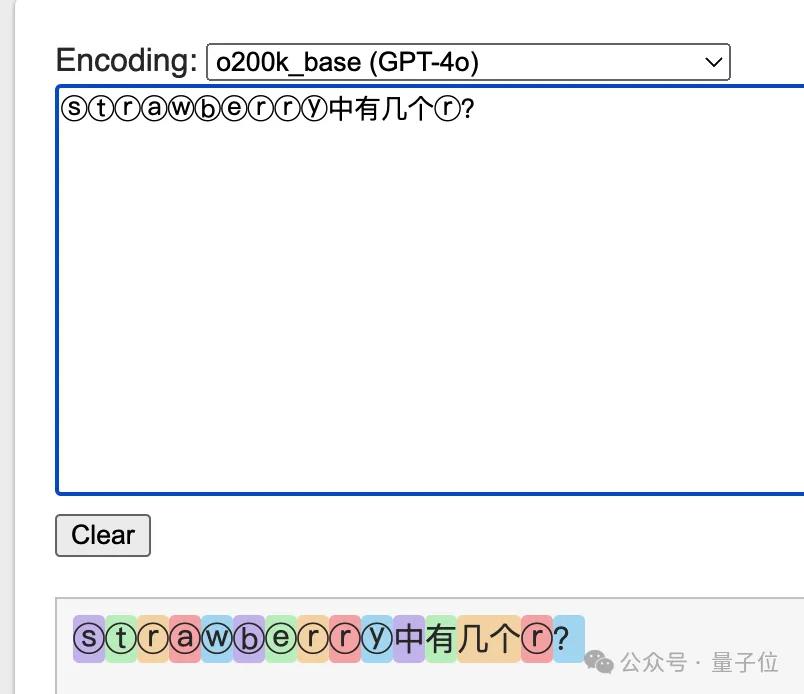
单个字符对大模型来说意义有限,使用GPT系列的Llama系列的tokenizer就会发现,20个字符的问题,在不同AI眼中是10-13个token。
其中相同之处在于,strawberry被拆成了st-,raw,-berry三个部分来理解。

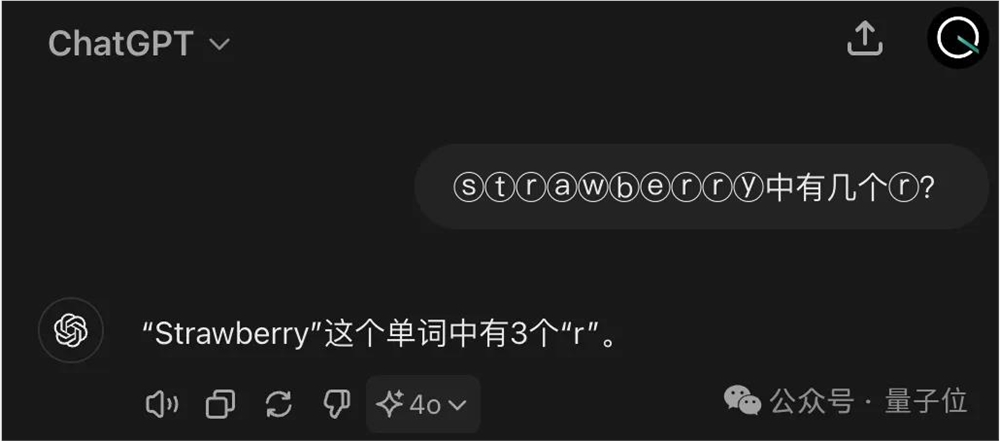
换一个思路用特殊字符ⓢⓣⓡⓐⓦⓑⓔⓡⓡⓨ来提问,每一个字符对应的token也就会分开了。
面对这种问题,其实最简单的方法就是像智谱清言一样,调用代码来解决了。
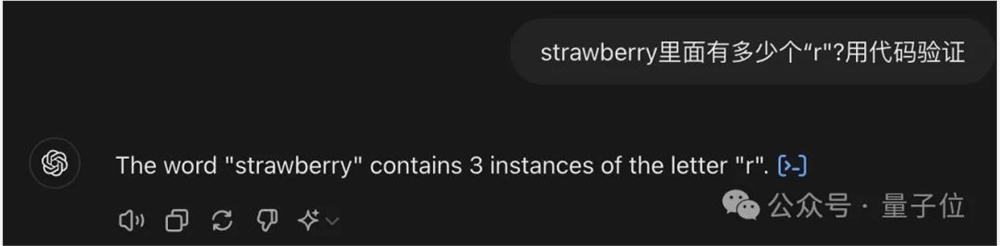
可以看到,ChatGPT直接用Python语言字符串的count函数,就能简单搞定。
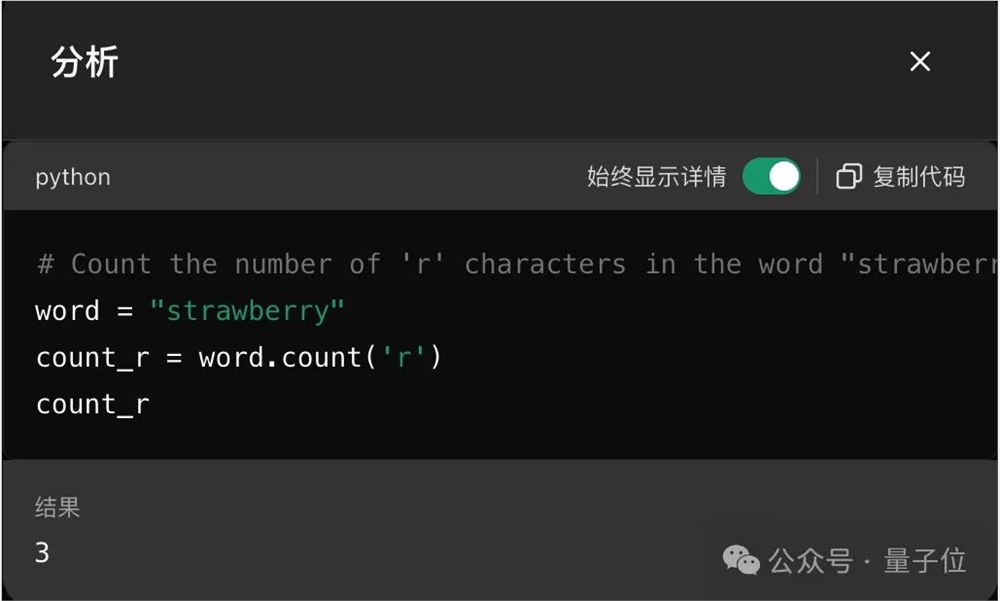
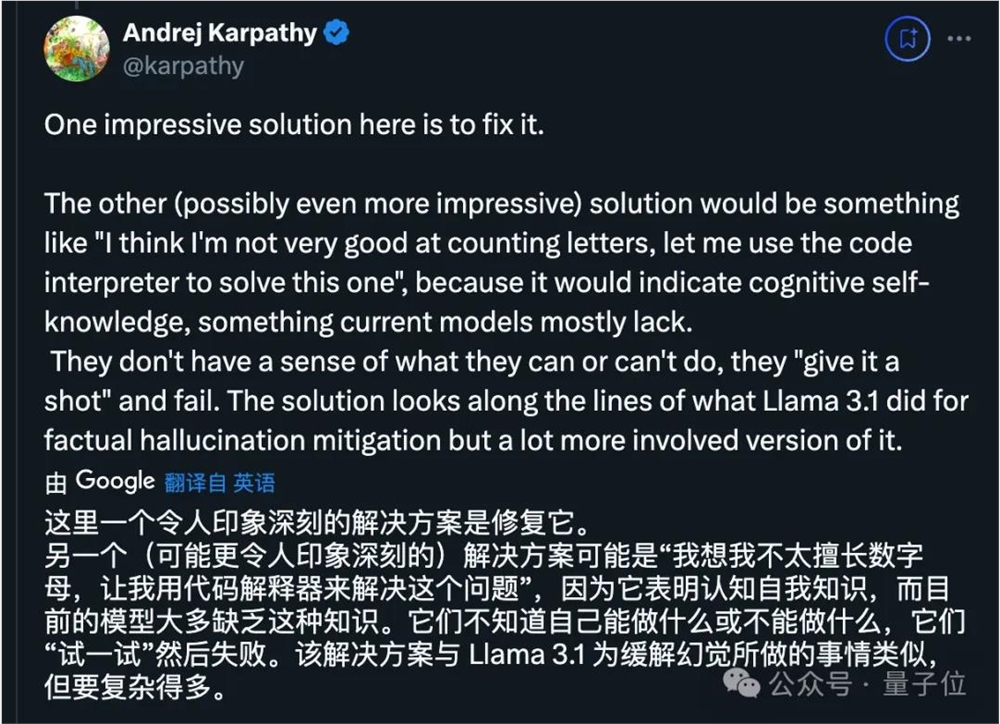
刚刚创业开了所学校的大神卡帕西认为,关键在于需要让AI知道自己能力的边界,才能主动去调用工具。
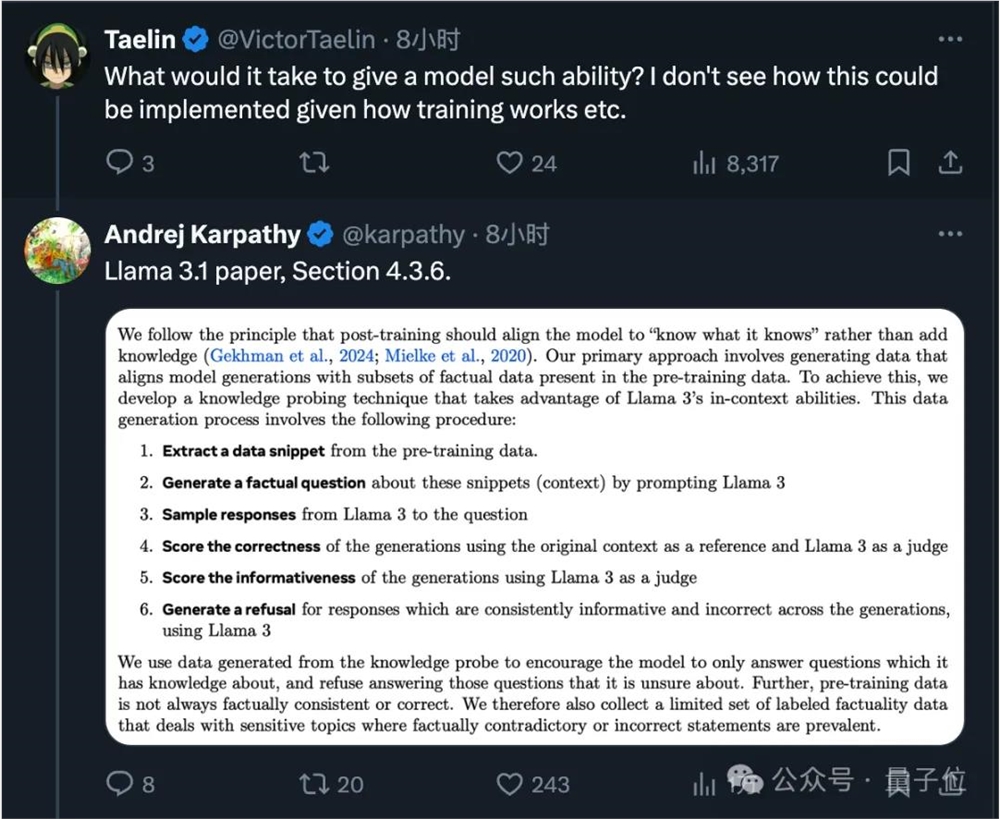
至于教给大模型判断自己知道不知道的方法,Meta在LLama3.1论文中也有所涉及。
最后正如网友所说,希望OpenAI等大模型公司,都能在下个版本中解决这个问题。

GPT Tokenizer试玩
https://gpt-tokenizer.dev
Llama Tokenizer试玩
https://belladoreai.github.io/llama-tokenizer-js/example-demo/build/
REDMI Turbo 4 正式发布:售价 1999 元起 首发天玑 8400-Ultra
今天下午,REDMITurbo4手机正式发布,首发搭载天玑8400-Ultra处理器,售价从1999元起,现已开始销售。站长网2025-01-02 15:33:040000华为:2023年前三季度实现销售收入4566亿元 同比增长2.4%
今日,华为发布2023年前三季度经营业绩,实现销售收入4566亿元人民币,同比增长2.4%,净利润率16.0%。华为轮值董事长胡厚崑表示:“公司经营结果符合预期。感谢客户、伙伴一直以来对华为的信任和支持。面向未来,我们将持续加大研发投入,发挥公司产业组合优势,不断提升产品和服务竞争力,为客户、伙伴和社会创造更大价值。”站长网2023-10-27 22:14:520000刷一天“极速版”APP能赚多少钱?
“看小说就能赚钱”、“刷视频就能赚钱”......号称动动手指就能赚钱的APP越来越多,比如各种极速版的APP、电子书APP、新闻资讯APP、搜索APP等等。很多人也都乐此不疲,一天到晚就是“刷刷刷”。最近一位“阿姨”晒各种“赚钱的APP”收入截图在业内传开,她一天赚了6.85元。那么刷一天这类的APP能赚多少钱呢?三言今天对几个App进行了一番测试。站长网2023-07-13 21:51:590003ChatGPT联动脑机接口 成功用脑电波发邮件
最近,Araya团队在脑机接口实验中成功地使用了ChatGPT,并利用EEG数据训练AI模型来操纵Gmail。该目标是为了开发BMI技术,以帮助残障人士参与社交互动和沟通,并且该技术还可以应用于提高客户服务场景的响应速度。这一成果让一些网友惊叹科幻成真了,但也有一些网友表示并不惊奇,因为非侵入式的脑机接口在好几年前就已经存在了,即使没有使用AI。站长网2023-05-16 16:23:080000迄今最强骁龙8至尊版!一加Ace 5 Pro跑分破321万
快科技12月19日消息,一加Ace5系列已经官宣,将于12月26日正式发布,是Ace系列的最强旗舰。这一次是Ace系列首次双杯齐发,一加Ace5搭载8Gen3,而一加Ace5Pro则是搭载当代旗舰骁龙8至尊版。官方最新公布出了一加Ace5Pro的跑分信息,安兔兔成绩达3218978分,成为迄今最强的骁龙8至尊版机型。性能大幅提升的同时,功耗还显著降低。0000












