首个超越GPT4o级开源模型!Llama 3.1泄密:4050亿参数,下载链接、模型卡都有了
Llama3.1终于现身了,不过出处却不是 Meta 官方。
今日,Reddit 上新版 Llama 大模型泄露的消息遭到了疯传,除了基础模型,还包括8B、70B 和最大参数的405B 的基准测试结果。

下图为 Llama3.1各版本与 OpenAI GPT-4o、Llama38B/70B 的比较结果。可以看到,即使是70B 的版本,也在多项基准上超过了 GPT-4o。
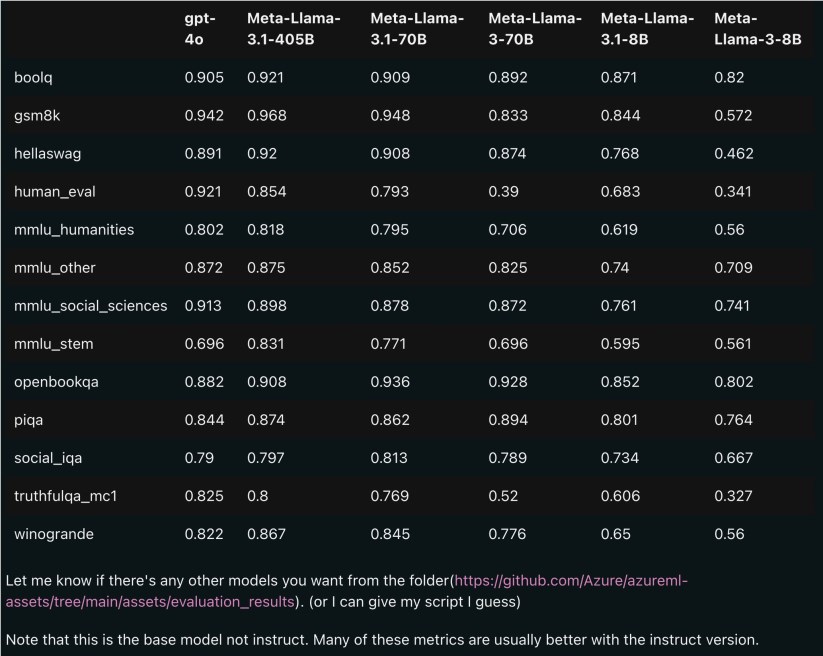
图源:https://x.com/mattshumer_/status/1815444612414087294
显然,3.1版本的8B 和70B 模型是由405B 蒸馏得来的,因此相比上一代有着明显的性能提升。
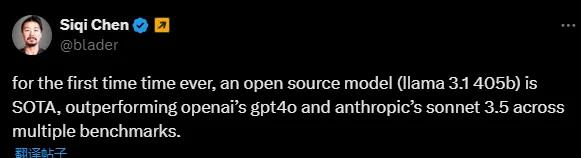
有网友表示,这是首次开源模型超越了 GPT4o 和 Claude Sonnet3.5等闭源模型,在多个 benchmark 上达到 SOTA。
与此同时,Llama3.1的模型卡流出,细节也泄露了(从模型卡中标注的日期看出基于7月23日发布)。
有人总结了以下几个亮点:
模型使用了公开来源的15T tokens 进行训练,预训练数据截止日期为2023年12月;
微调数据包括公开可用的指令微调数据集(与 Llama3不同)和1500万个合成样本;
模型支持多语言,包括英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。

图源:https://x.com/iScienceLuvr/status/1815519917715730702
虽然泄露的 Github 链接目前404了,但有网友给出了下载链接(不过为了安全,建议还是等今晚的官方渠道公布):
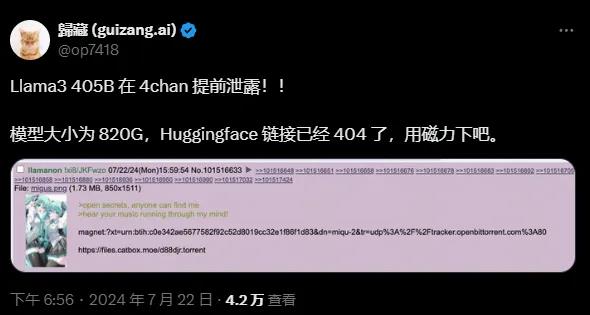
不过这毕竟是个千亿级大模型,下载之前请准备好足够的硬盘空间:
以下是 Llama3.1模型卡中的重要内容:
模型基本信息
Meta Llama3.1多语言大型语言模型 (LLM) 集合是一组经过预训练和指令微调的生成模型,大小分别为8B、70B 和405B(文本输入 / 文本输出)。Llama3.1指令微调的纯文本模型(8B、70B、405B)针对多语言对话用例进行了优化,在常见的行业基准上优于许多可用的开源和闭源聊天模型。
模型架构:Llama3.1是优化了的 Transformer 架构自回归语言模型。微调后的版本使用 SFT 和 RLHF 来对齐可用性与安全偏好。
支持语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
从模型卡信息可以推断,Llama3.1系列模型的上下文长度为128k。所有模型版本都使用分组查询注意力(GQA)来提高推理可扩展性。



预期用途
预期用例。Llama3.1旨在用于多语言的商业应用及研究。指令调整的纯文本模型适用于类助理聊天,而预训练模型可以适应各种自然语言生成任务。
Llama3.1模型集还支持利用其模型输出来改进其他模型(包括合成数据生成和蒸馏)的能力。Llama3.1社区许可协议允许这些用例。
Llama3.1在比8种受支持语言更广泛的语言集合上进行训练。开发人员可以针对8种受支持语言以外的语言对 Llama3.1模型进行微调,前提是遵守 Llama3.1社区许可协议和可接受使用策略, 并且在这种情况下负责确保以安全和负责任的方式使用其他语言的 Llama3.1。
软硬件基础设施
首先是训练要素,Llama3.1使用自定义训练库、Meta 定制的 GPU 集群和生产基础设施进行预训练,还在生产基础设施上进行了微调、注释和评估。
其次是训练能耗,Llama3.1训练在 H100-80GB(TDP 为700W)类型硬件上累计使用了39.3M GPU 小时的计算。这里训练时间是训练每个模型所需的总 GPU 时间,功耗是每个 GPU 设备的峰值功率容量,根据用电效率进行了调整。
训练温室气体排放。Llama3.1训练期间基于地域基准的温室气体总排放量预估为11,390吨二氧化碳当量。自2020年以来,Meta 在全球运营中一直保持净零温室气体排放,并将其100% 的电力使用与可再生能源相匹配,因此训练期间基于市场基准的温室气体总排放量为0吨二氧化碳当量。
用于确定训练能源使用和温室气体排放的方法可以在以下论文中找到。由于 Meta 公开发布了这些模型,因此其他人不需要承担训练能源使用和温室气体排放。
论文地址:https://arxiv.org/pdf/2204.05149
训练数据
概述:Llama3.1使用来自公开来源的约15万亿个 token 数据进行了预训练。微调数据包括公开可用的指令数据集,以及超过2500万个综合生成的示例。
数据新鲜度:预训练数据的截止日期为2023年12月。
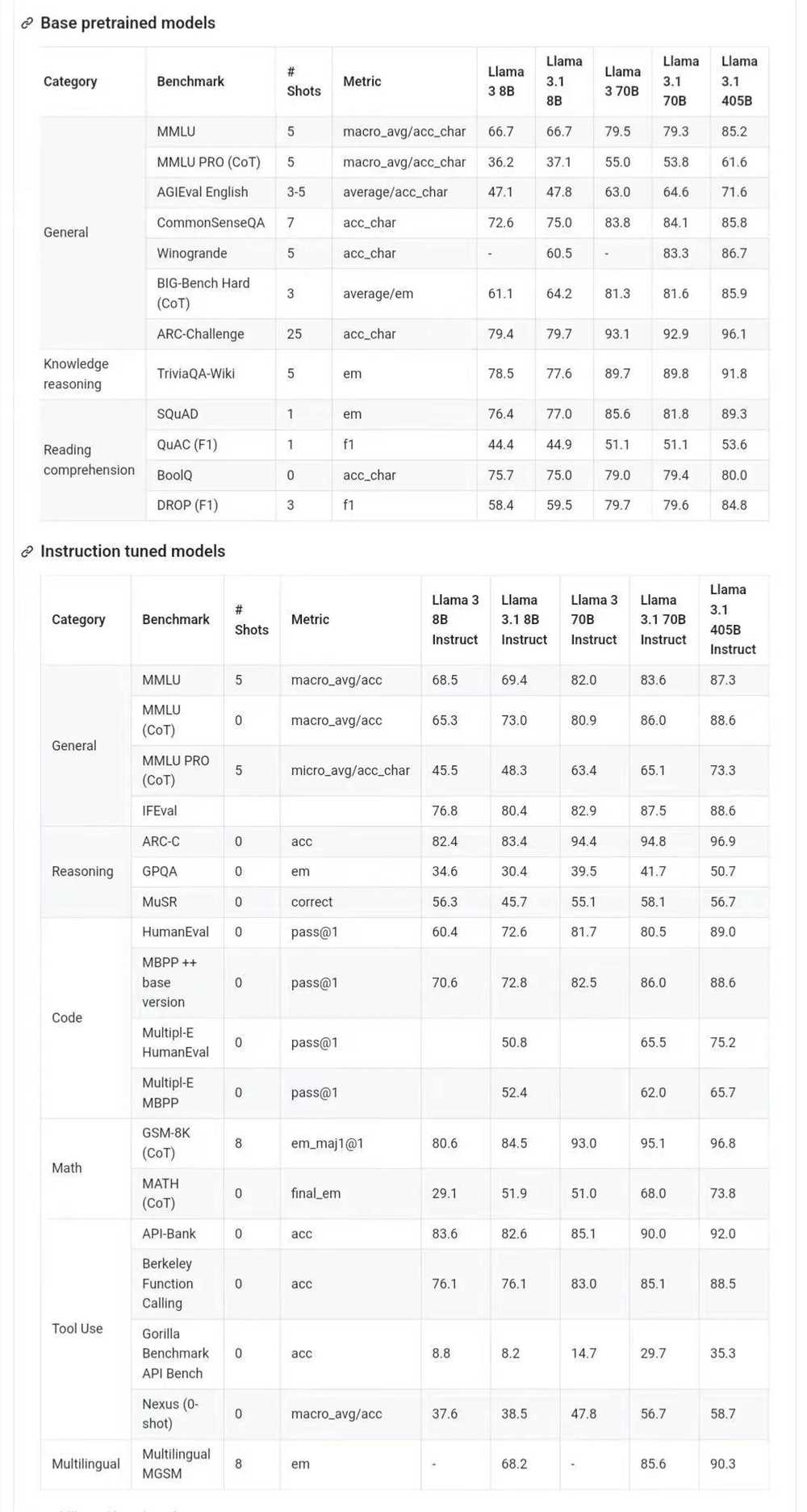
Benchmark 评分
在这一部分,Meta 报告了 Llama3.1模型在标注 benchmark 上的评分结果。所有的评估,Meta 都是使用内部的评估库。
安全风险考量
Llama 研究团队致力于为研究界提供宝贵的资源来研究安全微调的稳健性,并为开发人员提供适用于各种应用的安全且强大的现成模型,以减少部署安全人工智能系统的开发人员的工作量。
研究团队采用多方面数据收集方法,将供应商的人工生成数据与合成数据相结合,以减轻潜在的安全风险。研究团队开发了许多基于大型语言模型 (LLM) 的分类器,以深思熟虑地选择高质量的 prompt 和响应,从而增强数据质量控制。
值得一提的是,Llama3.1非常重视模型拒绝良性 prompt 以及拒绝语气。研究团队在安全数据策略中引入了边界 prompt 和对抗性 prompt,并修改了安全数据响应以遵循语气指南。
Llama3.1模型并非设计为单独部署,而是应作为整个人工智能系统的一部分进行部署,并根据需要提供额外的「安全护栏」。开发人员在构建智能体系统时应部署系统安全措施。
请注意,该版本引入了新功能,包括更长的上下文窗口、多语言输入和输出,以及开发人员与第三方工具的可能集成。使用这些新功能进行构建时,除了需要考虑一般适用于所有生成式人工智能用例的最佳实践外,还需要特别注意以下问题:
工具使用:与标准软件开发一样,开发人员负责将 LLM 与他们所选择的工具和服务集成。他们应为自己的使用案例制定明确的政策,并评估所使用的第三方服务的完整性,以了解使用此功能时的安全和安保限制。
多语言:Lama3.1除英语外还支持7种语言:法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语。Llama 可能可以输出其他语言的文本,但这些文本可能不符合安全性和帮助性性能阈值。
Llama3.1的核心价值观是开放、包容和乐于助人。它旨在服务于每个人,并适用于各种使用情况。因此,Llama3.1的设计宗旨是让不同背景、经历和观点的人都能使用。Llama3.1以用户及其需求为本,没有插入不必要的评判或规范,同时也反映了这样一种认识,即即使在某些情况下看似有问题的内容,在其他情况下也能达到有价值的目的。Llama3.1尊重所有用户的尊严和自主权,尤其是尊重为创新和进步提供动力的自由思想和表达价值观。
但 Llama3.1是一项新技术,与任何新技术一样,其使用也存在风险。迄今为止进行的测试尚未涵盖也不可能涵盖所有情况。因此,与所有 LLM 一样,Llama3.1的潜在输出无法事先预测,在某些情况下,该模型可能会对用户提示做出不准确、有偏差或其他令人反感的反应。因此,在部署 Llama3.1模型的任何应用之前,开发人员应针对模型的具体应用进行安全测试和微调。
模型卡来源:https://pastebin.com/9jGkYbXY
参考信息:https://x.com/op7418/status/1815340034717069728
https://x.com/iScienceLuvr/status/1815519917715730702
https://x.com/mattshumer_/status/1815444612414087294
GPT-5 短期内不会问世,AI的安全问题仍被放大
【CSDN编者按】一封要求暂停AI的公开信引发热议,随之而来的是GPT-5被抵制。在麻省理工学院的活动中,OpenAI的首席执行官兼联合创始人SamAltman首次进行正面回应。站长网2023-04-18 20:45:450000英格兰法官获准使用ChatGPT进行法律裁决
#划重点1.法官可使用ChatGPT协助书写法律裁决,尽管有人警告AI可能捏造不存在的案例。2.英格兰和威尔士的数千名法官收到司法办公室的官方指导,认为AI可用于总结大量文本或执行行政任务。3.指导警告ChatGPT等聊天机器人在进行研究时效果差,容易虚构案例或法律文本,并提到深度伪造技术可能用于制造虚假证据。站长网2023-12-12 16:29:370002准确率超99%!最新研究算法能精准检测ChatGPT写作
堪萨斯大学的科学家周三发表了一篇论文,详细介绍了一种算法ChatGPTspotter,他们说这种算法可以检测来自ChatGPT的学术写作,准确率超过99%。站长网2023-06-09 23:45:290000前“京东副总裁”开播带货,销售额破亿,曾被质疑博流量
12月14日,“蔡磊破冰驿站”(以下简称“破冰驿站”)的粉丝数量突破了250万。看到这个数据时,他和妻子段睿只是在直播间里简单拍了拍手,表示庆祝,仿佛这是一件再小不过的事情。蔡磊,曾经的“京东集团副总裁”,如今的“渐冻症斗士”。这个以他为名的直播间,诞生于2022年的9月21日,距离第一次开播已经过去了一年多时间。直播,并不是蔡磊真正关心的事情。0000OpenAI:计划与合作伙伴共同生成用于训练 AI 模型的数据集
OpenAI宣布将与合作伙伴共同生成用于训练AI模型的公共/私有数据集,以推动AI的未来发展并让更多组织从中受益。为了实现这一目标,OpenAI计划收集反映人类社会、涵盖不同语言、主题和格式的大量数据,并寻求合作伙伴的帮助以数字化并删除敏感信息。OpenAI希望创建公开开源数据集供所有人使用,以及私有数据集供希望保持数据私密性的组织使用。站长网2023-11-10 08:19:200000