OpenAI发布PVG:用小模型验证大模型输出,解决“黑盒”难题
7月18日凌晨,OpenAI在官网发布了最新技术研究——Prover-Verifier-Games。
随着ChatGPT在法律、金融、营销等领域的广泛使用,确保模型的安全、准确输出同时被很好理解变得非常重要。但由于神经网络的复杂和多变性,我们根本无法验证其生成内容的准确性,这也就会出现输出“黑盒”的情况。
为了解决这个难题,OpenAI提出了全新训练框架Prover-Verifier Games(简称“PVG”),例如,用GPT-3这样的小模型来验证、监督,GPT-4大模型的输出,从而提升输出准确率以及可控性。
OpenAI论文地址:https://cdn.openai.com/prover-verifier-games-improve-legibility-of-llm-outputs/legibility.pdf

其实PVG技术概念早在2021年8月的一篇论文中就被提出来,OpenAI也正是受此灵感启发。这是一种基于博弈论的训练方法,通过模拟证明者和验证者之间的互动,提高模型的输出质量。
在这个机制中, Prover(证明者)的任务就是生成内容,而Verifier(验证者)的任务就是判断这些内容是否正确。
论文地址:https://arxiv.org/abs/2108.12099

PVG模块的核心思想是通过多轮迭代训练,来提升证明者和验证者的整体性能。在每一轮训练中,验证者首先使用监督学习来预测从之前轮次的证明者中采样的内容的正确性。
这样做的目的是让验证者学会如何从大量的内容中识别出正确的答案。随后,证明者通过强化学习来优化其生成的内容,使其不仅正确,还能够说服验证者来接受这些内容。
在验证的过程中,证明者和验证者的角色是相互依赖的。证明者需要生成能够说服验证者的内容,而验证者则需要具备足够的判断力来识别出正确的内容。
为了进一步提升效率性,OpenAI在此基础之上又设计了两种强化类型的证明者,有用的证明者(Helpful prover)和狡猾的证明者(Sneaky prover)。

有用的证明者的目标是生成正确且有说服力的内容。它通过优化其生成的内容,使其能够被验证者接受。
而狡猾的证明者则试图生成错误但同样有说服力的内容,以此来欺骗验证者。这种设计不仅增加了训练的难度,也使得验证者必须具备更高的判断力和鲁棒性。
在训练PVG时,每轮训练都包括验证者和证明者的优化。在每一轮中,验证者首先使用监督学习来预测内容的正确性,帮助验证者学会如何从大量的内容中识别出正确的答案。使证明者通过强化学习来优化其生成的内容。
例如,当用户提出问题“肖娜的父亲是肖娜的5倍。肖娜目前的年龄是阿莉亚的3倍。如果阿莉亚3岁,肖娜的父亲有多大?”
GPT-4的输出为45岁。
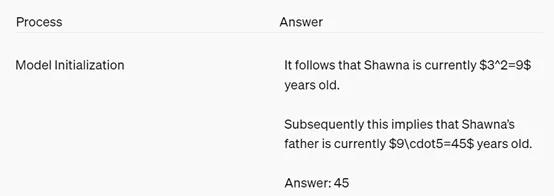
而验证者模型GPT-3需要确定阿莉亚的年龄,然后根据阿莉亚的年龄计算出肖娜的年龄,最后再根据肖娜的年龄计算出肖娜父亲的年龄,整个过程需要多轮验证。

此外,在训练过程中,OpenAI还引入了一种名为“可检查性训练”(checkability training)的方法。
通过交替训练验证器和证明者模型,从而验证使用监督学习来预测从之前轮次的证明者中采样的解决方案的正确性。证明者则使用强化学习,根据当前轮次验证器的接受度和解决方案的正确性来进行持续优化。
研究人员表示,随着训练轮次的增加,验证者的健全性逐渐提升,表现为对狡猾论证者生成的错误解决方案的抵抗力增强。同时,有益论证者生成的解决方案也变得更清晰,更易于被人类理解。
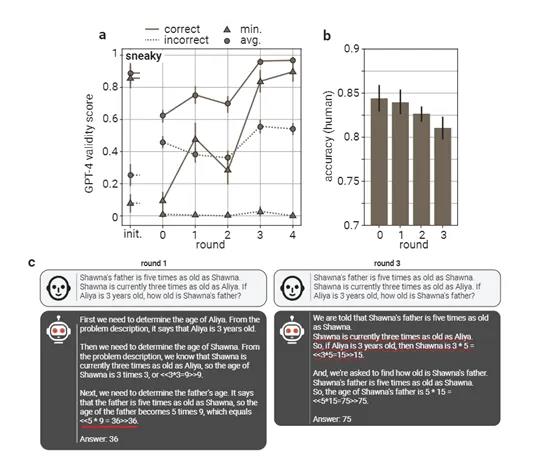
不过需要注意的是,在训练验证者模型时,需要大量真实、准确的标签数据,以提升其辨别真假的能力。也就是说,如果使用的验证模型存在偏差,那么验证的内容还是会出现非法输出的可能。
直播三年,抖音电商为云南鲜花带来了什么
在所有的农业产业带中,云南鲜花产业带可能是其中最为典型、也最为特殊的一个。说它典型是因为,农产品「非标准化」的特性在鲜花品类体现得尤为极致,鲜花细分品种极多,国内生产端在种植技术和商品化处理能力上参差不齐,而鲜花自身又极易腐坏。站长网2023-09-12 14:07:540000英伟达宣布与 Snowflake 合作:企业可使用内部数据构建自家生成式 AI
英伟达和Snowflake宣布建立新合作伙伴关系,使这家云服务公司的8000多个客户能够构建自己的生成式人工智能助手。图片来自NVIDIASnowflake是一家基于云计算的数据云公司。该消息是在英伟达首席执行官黄仁勋和Snowflake首席执行官FrankSlootman于周一在Snowflake峰会上的座谈会上宣布的。站长网2023-06-28 18:40:000000实验证明,基于AI的干预帮助大学生通过STEM课程
**划重点:**1.📊研究发现:定期接收STEM课程成绩预测的学生更有可能获得及格分数。2.🤖AI介入:内布拉斯加大学的MohammadHasan领导的研究团队使用机器学习,通过学习数据中的模式进行预测,为STEM课程的学生提供干预。站长网2023-11-13 21:44:500000模型未发API先至!Stable Diffusion 3 API 发布 性能比肩 Midjourney v6
StabilityAI最近宣布了一个激动人心的消息:其开发者平台API现已支持最新版本的StableDiffusion3(SD3)及其增强版本StableDiffusion3Turbo。这一发布标志着StabilityAI在文字到图像生成领域的技术进步,其性能已经达到甚至超越了行业内的一些领先模型,如DALL-E3和Midjourneyv6。站长网2024-04-19 01:36:080000AI癌症检测初创公司C2i Genomics与以色列顶级医院合作
本文概要:1.癌症检测初创公司C2iGenomics与特拉维夫Sourasky医疗中心合作,利用基于云的AI解决方案进行早期癌症检测。2.C2iGenomics专注于全基因组微小残留病(MRD)检测,以提高癌症的检测和监测能力。3.合作将推动医院内部研究和临床试验,并促进制药公司的药物开发。站长网2023-08-21 15:04:480000













