AI日报:Claude 3 Haiku支持微调;Heygen推对口型工具;百度称萝卜快跑安全水平接近C919飞机
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、Anthropic宣布Claude 3 Haiku支持微调
Anthropic宣布用户现在可以在Amazon Bedrock中微调最新模型Claude 3 Haiku,提高模型在特定任务上的效果。微调功能使用户能根据业务需求定制模型知识和能力,带来诸多好处。
【AiBase提要:】
🛠️ 用户可以通过高质量的提示-完成对进行微调,提升模型的专业能力。
⚡ Claude 3 Haiku是最快和最具成本效益的模型,适合专门任务使用。
🔒 客户的专有训练数据保持在AWS环境内,确保安全性和低风险。
详情链接:https://aws.amazon.com/cn/bedrock/claude/
2、Heygen推对口型工具 上传照片 音频即可说话、唱歌
最近,AI照片“复活术”在网络上掀起波澜,Heygen推出对口型工具,让照片中人物根据音频内容说话、唱歌,支持长达20秒音频,唇形与表情同步。Heygen融资5亿美元,由Benchmark领投,发展势头强劲。中国区用户受限制,令部分用户失望。Heygen利用生成式AI技术制作影片,已筹集7400万美元。
【AiBase提要:】
🌟 Heygen推出对口型工具,让照片中人物根据音频内容说话、唱歌,支持长达20秒音频。
💡 Heygen融资5亿美元,由Benchmark领投,发展势头强劲。
🔒 中国区用户受限制,令部分用户失望。Heygen利用生成式AI技术制作影片,已筹集7400万美元。
详情链接:https://labs.heygen.com/guest/expressive-photo-avatar
3、百度飞桨PaddleOCR发布v2.8.0新版本
PaddleOCR v2.8.0作为飞桨深度学习开源框架下的文字识别开发套件,发布了里程碑式的更新。这个版本引入了前沿的OCR技术,包括PaddleOCR算法模型挑战赛的冠军方案,如场景文本识别算法SVTRv2和表格识别算法SLANet-LCNetV2,为OCR领域树立了新的标准。项目结构经过深度优化,非核心模块被迁移至新仓库,使项目更专注于OCR核心技术。新版本解决了历史疑难问题,提升了用户体验,增强了稳定性、兼容性和性能。
【AiBase提要:】
🚀 PaddleOCR v2.8.0引入了前沿的OCR技术,包括SVTRv2和SLANet-LCNetV2,树立了OCR领域新标准。
🔧 项目结构优化,非核心模块迁移至新仓库,专注于OCR核心技术。
🌟 新版本解决历史疑难问题,提升用户体验,增强稳定性、兼容性和性能。
详情链接:https://github.com/PaddlePaddle/PaddleOCR
4、百度称萝卜快跑安全水平接近C919飞机
萝卜快跑公司推出第六代无人车,成功接入百度ApolloADFM大模型,安全性超过人类驾驶员10倍以上。百度对无人车安全性充满信心,每辆车及乘客投保500万元保险。运行数据显示出险率仅为人类司机的1/14,安全性表现卓越。百度Apollo自动驾驶技术已行驶超过1亿公里,无重大伤亡事故,成功实现武汉全域、全时空自动驾驶服务覆盖。
【AiBase提要:】
🚗 无人车安全性超过人类驾驶员10倍以上
💼 每辆车及乘客投保500万元保险
🛣️ 运行数据显示出险率仅为人类司机的1/14
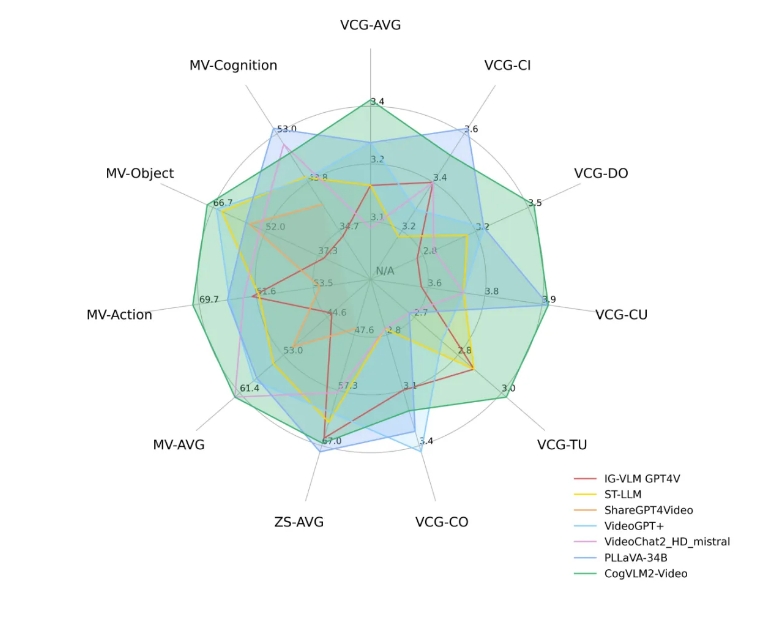
5、智谱AI宣布开源视频理解模型CogVLM2-Video
智谱AI最新开源的CogVLM2-Video模型在视频理解领域取得显著进展,通过解决时间信息丢失问题,实现了优异的性能表现。该模型不仅在视频字幕生成和时间定位方面表现出色,还为视频生成和摘要等任务提供了强大工具。通过自动生成丰富的时间定位数据集,模型在公共视频理解基准上达到最新性能,展现出卓越的性能。
【AiBase提要:】
⏰ CogVLM2-Video通过引入多帧视频图像和时间戳作为编码器输入,解决了现有视频理解模型在处理时间信息丢失问题上的局限。
💡 模型利用自动化的时间定位数据构建方法,生成了3万条与时间相关的视频问答数据,为训练提供丰富的时间定位数据。
🚀 CogVLM2-Video在多个公开评测集上展现了卓越性能,包括在VideoChatGPT-Bench和Zero-shot QA以及MVBench等量化评估指标上的优异表现。
详情链接:https://github.com/THUDM/CogVLM2
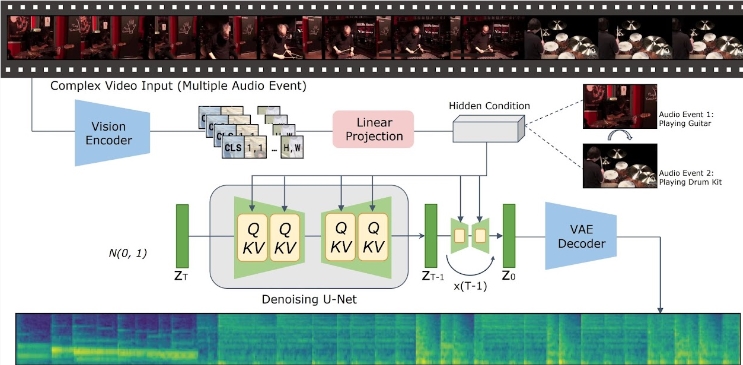
6、腾讯AI实验室的项目vta-ldm:输入视频生成对齐音频
随着文本到视频生成技术的进步,研究者们关注如何生成与视频输入在语义和时间上对齐的音频内容。腾讯AI实验室推出VTA-LDM模型,通过隐含对齐技术提供高效音频生成解决方案,拓展视频生成应用场景。
【AiBase提要:】
🎬 研究聚焦于生成与视频输入在语义和时间上对齐的音频内容。
🔍 探讨了视觉编码器、辅助嵌入和数据增强技术的重要性。
📈 实验结果显示模型在视频到音频生成领域达到先进水平,推动相关技术发展。
详情链接:https://top.aibase.com/tool/vta-ldmVTA-LDM
7、GPT-4o和Sonnet-3.5在视力测试中败北,VLM们竟是“盲人”?
这篇文章揭示了视觉语言模型(VLMs)在图像处理能力上的局限性,通过BlindTest测试发现它们并非像人类一样能准确理解图像细节。文章呼吁对VLMs的视觉理解能力持谨慎态度,警示AI并未达到完全替代人类的水平。
【AiBase提要:】
👓 VLMs在BlindTest测试中表现不佳,平均准确率仅56.20%
🔍 VLMs处理图像时缺乏精确的空间信息,难以判断图形重叠或相交
🔢 VLMs在数数时存在偏好,对数字5特别熟悉,表现不稳定
论文地址:https://arxiv.org/pdf/2407.06581
文章详细内容:https://www.chinaz.com/ainews/10186.shtml
8、商汤科技发布「东风」泰语大模型
商汤科技与泰国DTGO集团及Quinnnova联合发布了名为「东风」的泰语大模型(DTLM),这是全球首个能够在泰文、中文、英文三种语言环境下高效工作的AI大语言模型。该模型结合了商汤的基模型和算力优势以及DTGO对泰国语言文化的深入了解,旨在提供本地化的生成式AI体验。
【AiBase提要:】
⚙️ 「东风」是全球首个能够在泰文、中文、英文三种语言环境下高效工作的AI大语言模型。
🌏 模型结合了商汤的基模型和算力优势以及DTGO对泰国语言文化的深入了解,旨在提供本地化的生成式AI体验。
💡 模型将服务于泰国的个人用户和企业,满足多语言需求,同时为当地企业和政府客户提供创新的AI解决方案,推动泰国AI生态系统的发展。
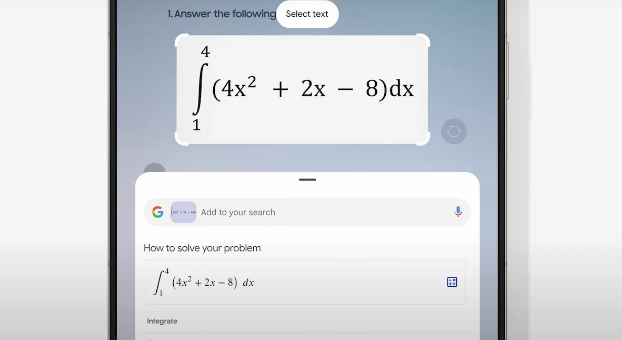
9、三星 Galaxy AI 推出“数学辅导”新模式 告诉孩子解题技巧
三星在昨日的Unpacked活动上宣布了Galaxy AI的重大进展,推出了专为帮助儿童完成家庭作业而设计的AI助手。这一举措展现了三星在人工智能领域的雄心壮志,为智能手机市场带来新的竞争维度,推动整个行业向更智能、更有教育价值的方向发展。
【AiBase提要:】
🚀 三星发布Galaxy AI,覆盖高达2亿台设备,展现雄心壮志。
🔍 家庭作业助手基于Galaxy AI的“圆圈搜索”功能,引导孩子完成问题解决过程。
📚 家庭作业助手提供数学问题解决,培养孩子独立思考能力。
10、三家欧洲汽车制造商将集成ChatGPT功能 提升驾驶体验
Stellantis旗下的法国标致、德国欧宝和英国沃克斯豪尔将整合ChatGPT人工智能技术,通过SoundHound的ChatAI系统提供语音助手功能,改善驾驶体验。这一合作标志着汽车科技的发展,将带来更自然、流畅的驾驶交互体验。
【AiBase提要:】
🚗 Stellantis旗下Peugeot、Opel和Vauxhall将集成ChatGPT人工智能技术,提升汽车产品功能。
🌍 跨越17个国家,支持12种语言的语音助手系统,为更多驾驶者提供便利。
📱 SoundHound的ChatAI将带来更自然的驾驶交互体验,推动汽车科技发展。
11、谷歌正通过Gemini AI训练机器人,提高导航和任务完成能力
谷歌正在利用Gemini AI训练机器人,提高其导航和任务完成能力。通过Gemini1.5Pro,机器人可以执行自然语言指令,计划执行超出导航范围的任务。研究表明,Gemini让机器人成功执行用户指令的成功率高达90%。尽管处理指令需要一定时间,但这些机器人有望帮助人们完成各种任务,如找到遗失物品。

【AiBase提要:】
🤖 Gemini AI训练机器人,提高导航和任务完成能力
🧠 Gemini1.5Pro让机器人执行自然语言指令
🔍 研究发现Gemini让机器人能够计划执行超出导航范围的指令
12、OpenAI首次披露AGI评估标准:ChatGPT仅为第一级
OpenAI公司公布了内部量表,用于追踪其大型语言模型在通用人工智能(AGI)方面的进展,展示了其在AGI领域的雄心。该举措为业界提供了衡量AI发展的新标准,引发了对AI安全和伦理的担忧。
【AiBase提要:】
🚀 OpenAI创建AGI评估标准,展示雄心
💡 量表分为五级,包括能创造新创新的AI和执行整个组织工作的AI
⏳ 专家对AGI实现时间表存在分歧,OpenAI与洛斯阿拉莫斯国家实验室合作探索AI在生物科学研究中的应用
谷歌推出AI音乐创作工具“MusicFX”,几句话即可创作音乐
**划重点:**1.🚀MusicFX利用Google的MusicLM和DeepMind的SynthID技术,让用户通过几句话即可创作音乐,标志性的AI音乐创作工具。2.🛡️工具在保护原创艺术家声音和风格的同时,强调了负责任的AI创新,通过早期公众参与和隐私保护解决了潜在问题。站长网2023-12-14 10:24:380000李想:理想汽车6月实现32000辆交付成绩
理想汽车CEO李想在8周年全员信中表示,理想汽车6月实现了32000辆的交付成绩。2023年到2025年将是理想汽车发展中最重要的三年。公司的目标是成为中国市场所有豪华品牌销量的第一,并将交付量提升至每年160万辆。李想在员工信中还透露,到2025年,理想汽车的产品矩阵将包括一款超级旗舰车型、五款增程电动车型和五款纯电车型,以满足更广泛的家庭用户市场需求。站长网2023-06-30 19:25:080002基于牛顿求根法,新算法实现并行训练和评估RNN,带来超10倍增速
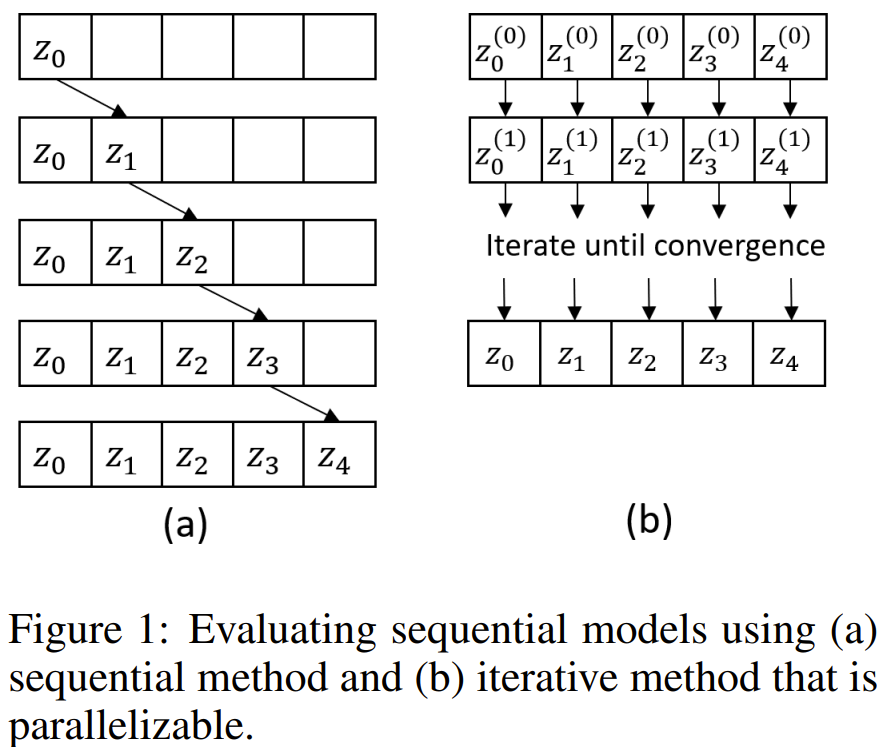
人们普遍认为RNN是无法并行化的,因为其本质上的序列特性:其状态依赖于前一状态。这使得人们难以用长序列来训练RNN。近日,一种新算法的出现打破了这一惯常认知,可以并行化RNN和NeuralODE等非线性序列模型的评估和训练,从而为相关研究和开发带来显著的速度提升。站长网2023-10-07 18:16:020000这届打工人太难带?全能智能体出手了
打工人捅娄子,现在都能靠AI来补救了!领导马上就要的促销方案,唰一下就写好了。不仅能直接导出Word:还能一键生成PPT。职场新人不熟悉的电脑设备,还总是遇到bug,截图问AI,它就能给出具体的解决方案。和请教ChatGPT不同,它能主动识别设备信息,结合具体情况回答。不知道如何操作还能继续问。还有连不上打印机、系统报错这种很细小的问题,现在都可以求助AI。站长网2024-12-31 18:32:350000亚马逊发布生成式 AI 助手 Amazon Q,功能强大易用
划重点:⭐亚马逊正式发布生成式AI助手AmazonQ,可生成创意文本、代码、总结文档、分析数据等功能⭐AmazonQ包括面向业的助手AmazonQBusiness和专业开发人员的AmazonQDeveloper⭐AmazonQDeveloper集成了AI代理功能,可现代码生成、测试、调试、漏洞扫描等一站式服务站长网2024-05-02 21:50:040000