何恺明新作再战AI生成:入职MIT后首次带队,奥赛双料金牌得主邓明扬参与
何恺明入职MIT副教授后,首次带队的新作来了!
让自回归模型抛弃矢量量化,使用连续值生成图像。并借鉴扩散模型的思想,提出Diffusion Loss。

他加入MIT后,此前也参与过另外几篇CV方向的论文,不过都是和MIT教授Wojciech Matusik团队等合作的。
这次何恺明自己带队,参与者中还出现一个熟悉的名字:
邓明扬,IMO、IOI双料奥赛金牌得主,在竞赛圈人称“乖神”。
目前邓明扬MIT本科在读,按入学时间推算现在刚好大四,所以也有不少网友猜测他如果继续在MIT读博可能会加入何恺明团队。
接下来具体介绍一下,这篇论文研究了什么。
借鉴扩散模型,大改自回归生成
传统观点认为,图像生成的自回归模型通常伴随着矢量量化(Vector Quantization),比如DALL·E一代就使用了经典的VQ-VAE方法。
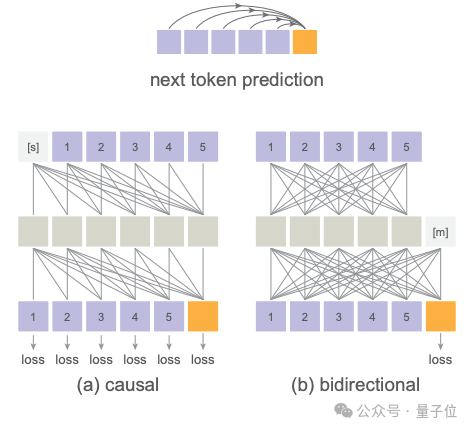
但团队观察到,自回归生成的本质是根据先前的值预测下一个token,这其实与值是离散还是连续没啥必然联系啊。
关键是要对token的概率分布进行建模,只要该概率分布可以通过损失函数来测量并用于从中抽取样本就行。
并且从另一个方面来看,矢量量化方法还会带来一系列麻烦:
需要一个离散的token词表,需要精心设计量化的目标函数,训练困难,对梯度近似策略很敏感
量化误差会带来信息损失,导致还原图像质量打折
离散token适合建模分类分布,有表达能力上的局限
那么有什么更好的替代方法?
何恺明团队选择在损失函数上动刀,借鉴近年大火的扩散模型的思想,提出Diffusion Loss,消除了离散tokenizer的必要性。
如此一来,在连续值空间中应用自回归模型生成图像就可行了。

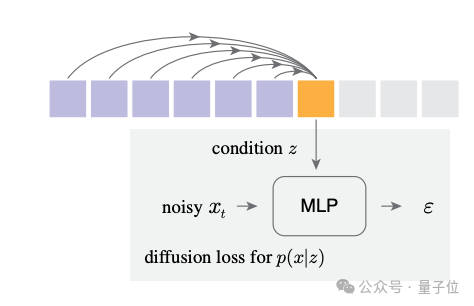
具体来说,它让自回归模型输出一个潜变量z作为条件,去训练一个小型的去噪MLP网络。
通过反向扩散过程,这个小网络就学会了如何根据z去采样生成连续值的token x。扩散的过程天然能建模任意复杂的分布,所以没有类别分布的局限。
这个去噪网络和自回归模型是端到端联合训练的,链式法则直接把损失传给自回归模型,使其学会输出最佳的条件z。
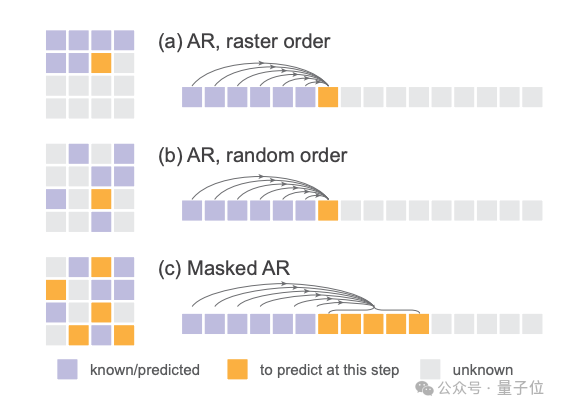
这篇工作的另一个亮点,是各种自回归模型的变体都适用。它统一了标准的自回归AR、随机顺序的AR、以及何恺明擅长的掩码方法。
其中掩码自回归(MAR)模型,可以在任意随机位置同时预测多个token,同时还能和扩散损失完美配合。
在这个统一的框架下,所有变体要么逐个token预测,要么并行预测一批token,但本质上都是在已知token的基础上去预测未知token,都是广义的自回归模型,所以扩散损失都能适用。
通过消除矢量量化,团队训练的图像生成模型获得了强大的结果,同时享受序列建模的速度优势。
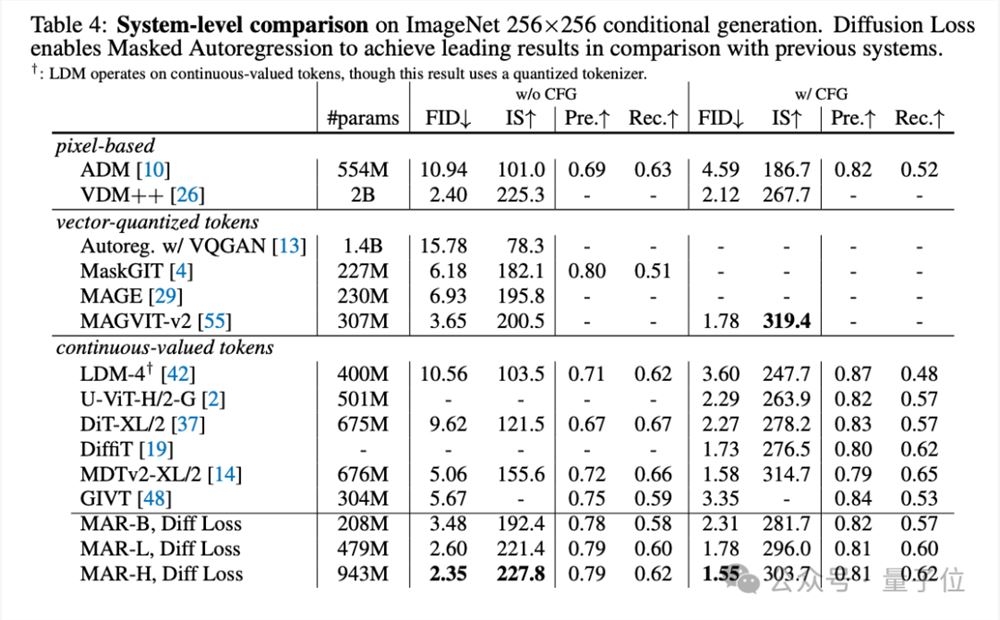
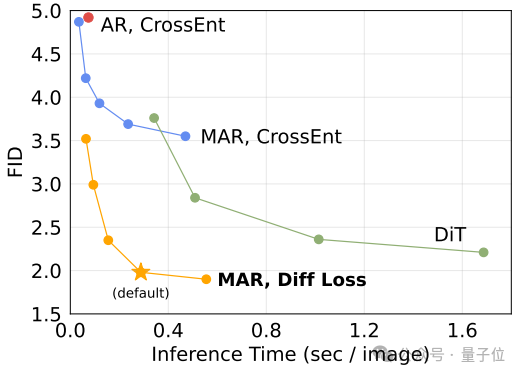
论文在AR、MAR的各种变体上做了大量实验,结果表明扩散损失比交叉熵损失稳定带来2-3倍的提升。
与其他领先模型一比也毫不逊色,小模型都能做到1.98的FID分数,大模型更是创下了1.55的SOTA。
而且它生成256x256图像速度也很快,不到0.3秒一张。这得益于自回归生成本来就很快,比扩散模型少采样很多步,再加上去噪网络又很小。
最后总结一下,这项工作通过自回归建模token间的相关性,再搭配扩散过程对每个token的分布进行建模。
这也有别于普通的潜空间扩散模型中用单个大扩散模型对所有token的联合分布建模,而是做局部扩散,在效果、速度和灵活性上都展现出了巨大的潜力。
当然,这个方法还有进一步探索的空间,团队提出,目前在在某些复杂的几何图形理解任务上还有待提高。
何恺明团队都有谁
最后再来介绍一下即将或可能加入何恺明课题组的团队成员。。
Tianhong LI(黎天鸿),清华姚班校友,MIT博士生在读,将于2024年9月加入何恺明的课题组,担任博士后。
Mingyang Deng(邓明扬),MIT本科数学和计算机科学专业在读。
他在高一获得IMO金牌,高三获得IOI金牌,是竞赛圈为数不多的双料金牌得主,也是IOI历史上第三位满分选手。
目前邓明扬的研究重点是机器学习,特别是理解和推进生成式基础模型,包括扩散模型和大型语言模型。
不过他的个人主页上还没有透露下一步计划。
One More Thing
何恺明当初在MIT的求职演讲备受关注,其中提到未来工作方向会是AI for Science,还引起圈内一阵热议。

现在,何恺明在AI4S方向的参与的首篇论文也来了:强化学习 量子物理学方向。
把Transformer模型用在了动态异构量子资源调度问题上,利用自注意力机制处理量子比特对的序列信息。并在概率性环境中训练强化学习代理,提供动态实时调度指导,最终显著提升了量子系统性能,比基于规则的方法提高了3倍以上。

这样一来,何恺明在自己的成名领域CV和探索新领域AI4S上都没耽误,两开花,两开花。
论文:
https://arxiv.org/abs/2406.11838
参考链接:
[1]https://www.tianhongli.me
[2]https://lambertae.github.io
[3]https://arxiv.org/abs/2405.16380
—完—
可灵通用!runway Gen-3发布保姆级教程 深度解析文本提示词技巧
在AIGC领域,文本提示词的艺术至关重要。Runway的Gen-3Alpha模型的发布,带来了一场关于如何精准操控生成式AI的革命。这不仅是技术的胜利,更是创意与表达的飞跃。在使用Gen-3等生成式AI产品时,你可能会发现,生成的结果有时与预期相去甚远。这通常是因为提示词不够详尽或精准。例如,简单的“沙漠落日”太过宽泛,无法指导模型理解你的真正意图。站长网2024-07-09 20:12:460001小杨哥徒弟小黄回应近期改变:从给兄弟带来欢笑到全面思考
1月10日晚,小杨哥的徒弟“红绿灯的黄”在直播中分享了她的近期感悟。她表示,过去自己只想着给观众带来欢乐,而忽视了这种行为可能对年轻观众造成的影响。现在,她开始意识到自己的责任,并努力提升直播内容的品质。“红绿灯的黄”坦言,以前自己的思考方式较为狭隘,认为某些行为并无大碍。但现在,她开始全面地看待问题,努力优化自己的缺点,希望为观众提供更有价值的内容。0000为什么全球监管可能无法阻止危险的人工智能
划重点:-🌍全球政府正在努力限制人工智能的风险,但一些专家对控制这一技术表示怀疑。-🤔一些人对人工智能可能带来的威胁的灾难性场景持怀疑态度,但也有观察家认为这些场景被夸大了。-🛡️尽管国际社会在人工智能安全方面展现了新的统一态度,但目前的提议法规可能不足以限制风险。全球政府正致力于寻找限制人工智能风险的方法,但一些专家对这一技术能否被控制住持怀疑态度。站长网2023-11-10 10:21:380000马斯克、Grok与“数据封建主”
下周,马斯克踌躇已久的Grok就要上线了。在OpenAI接连甩出炸街新闻的这段时间,这事似乎没掀起太大波澜。然而,越低调的狙击,往往伤害越高。具体来说,Grok的这次年末突袭,隐藏了老马背刺OpenAI的一件“秘术”。所谓的“秘术”,其实也很简单,就是X平台上不断涌现的,真实的人类数据。在大模型数据愈发吃紧的今天,连OpenAI自己,也开始直接拿用户数据训练了。站长网2023-11-29 11:22:240000微信进一步打击不良直播PK行为 近一周封停直播帐号7个
微信发布《关于进一步打击不良直播PK行为的公告》称,近段时间以来,直播PK环节恶俗现象引发社会关注。微信坚决反对并持续打击以博眼球、吸引流量为目的的不良直播行为,如拼酒斗狠、剧本炒作、低俗惩罚等,平台对此类行为保持零容忍态度,并将深入开展专项治理,从严处置相关违规行为。近一周,平台处置违规PK直播间438个,处置违规PK帐号356个,封停直播帐号7个。站长网2023-06-07 20:08:290001