Llama3-8B秒杀700亿巨兽?北大博士生等全新「BoT」框架推理暴涨70倍,24点图形推理一步成神
【新智元导读】24点游戏、几何图形、一步将死问题,这些推理密集型任务,难倒了一片大模型,怎么破?北大、UC伯克利、斯坦福研究者最近提出了一种全新的BoT方法,用思维模板大幅增强了推理性能。而Llama3-8B在BoT的加持下,竟多次超越Llama3-70B!
大语言模型不擅长推理怎么办?
用思维缓冲区(Buffer of Thoughts,BoT)来解决!
最近,北大、UC伯克利、斯坦福的研究人员提出了一种元缓冲区(meta-buffer)。它可以存储一系列信息丰富的高级思维,也就是所谓的「思维模板」,它是从各种任务的问题解决过程中蒸馏出来的。

论文地址:https://arxiv.org/abs/2406.04271
然后,对于每个问题,都可以检索相关的思维模板,然后用特定的推理结构让它自适应,这样就可以进行有效的推理了!
在以往,24点游戏(Game of24)、几何图形任务(Geometric Shapes)、一步将死问题(Checkmate-in-One)这些推理密集型任务,难倒了不少LLM。
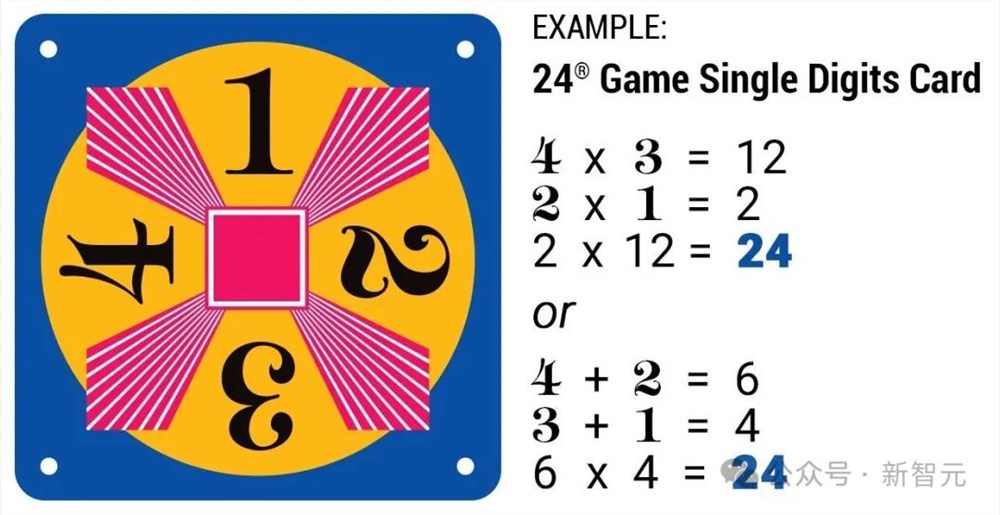
24点游戏
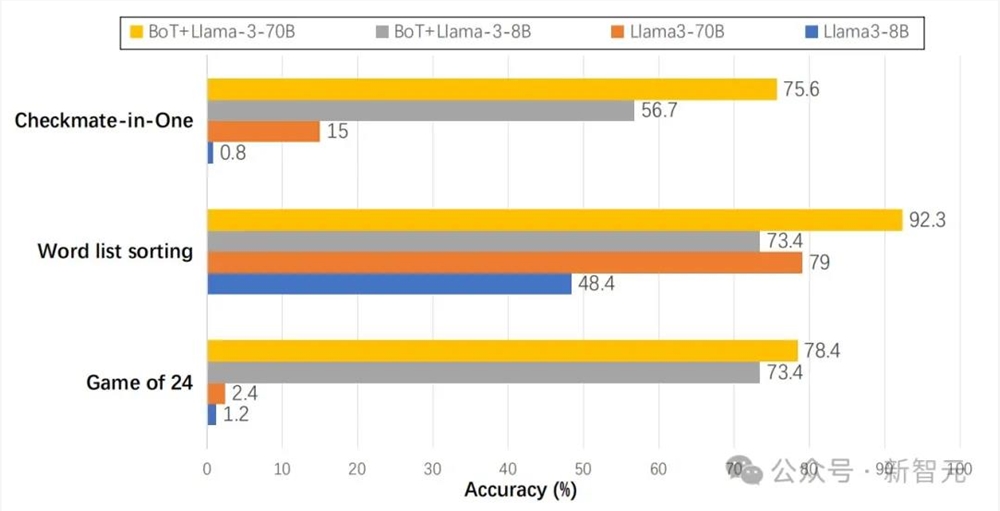
而使用思维缓冲区(BoT)后,与之前的SOTA相比,LLM在24点游戏的性能提升了11%,几何图形任务的性能提升了20%,一步将死问题的性能则一举提升了50%。
分析显示,BoT具有卓越的泛化能力和模型鲁棒性。
甚至,原本在各项任务中惨败的Llama3-8B小模型, 在BoT的加持下,竟然性能大升级,在多项任务上一举超越了Llama3-70B!
在实验过程中,团队设计了一种缓冲区管理器(buffer-manager)。这种管理器可以从各种解决方案中,蒸馏出思维模板,而随着LLM解决的任务越来越多,元缓冲区的容量也在不断增大。
而且,BoT的成本也很香,平均只需要多查询提示方法成本的12%。
几何图形推理任务
LLM推理难,两种方法均有局限
咱们都知道,GPT-4、PaLM、Llama这些大模型选手,都是完成推理任务的佼佼者了。
怎么能让它们的推理性能变强,更上一层楼呢?
除了扩大模型规模,还有一个办法,就是通过更有效的提示方法。
具体来说,这些方法分为两类。
1. 单查询推理
这类方法主要是靠提示工程,让推理过程在单个查询中完成,比如CoT的「让我们一步一步思考」。
或者Few-shot Prompting,能提供与任务相关的示例来帮助生成答案。
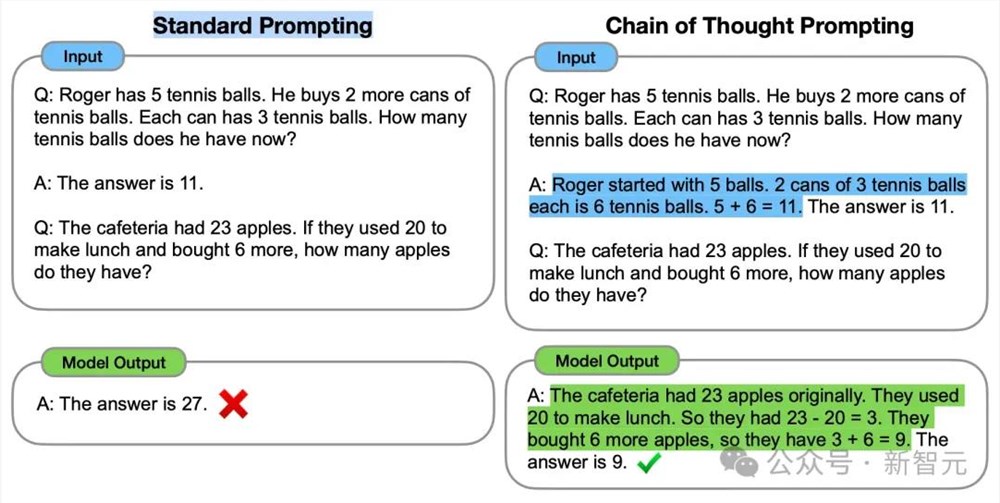
然而,单查询推理通常需要事先假设或推理过程的相关示例,逐个任务地手动设计,显然是不切实际的。因而它缺乏普适性和泛化性。
2. 多查询推理
包括Least-to-Most、ToT、GoT等,它们侧重于利用多个LLM查询,来引出不同的合理推理路径,从而将复杂问题分解为一系列更简单的子问题。
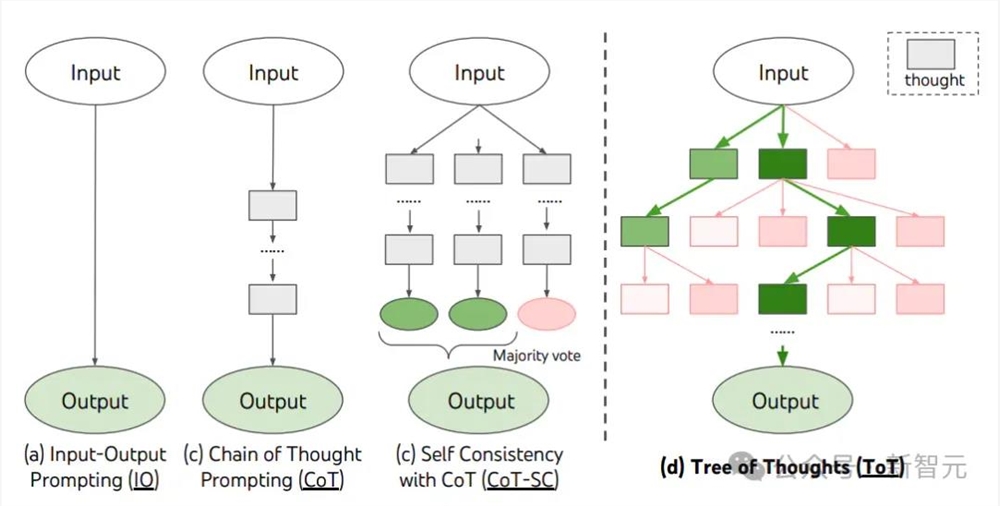
然而,由于推理路径的递归扩展,多查询推理在为每个特定任务找到推理过程背后唯一的内在结构时,通常是计算密集型的。
另外,这两种方法都受限于设计范例和推理结构的限制,而且之前的任务做完了就做完了,它们不会从中得到高级的指导方针和思维。再遇到类似问题时,它们依然效率很低。
因此,BoT诞生了!
这种新颖、多功能的思维增强框架,能够规避上述两种方法的弱点。
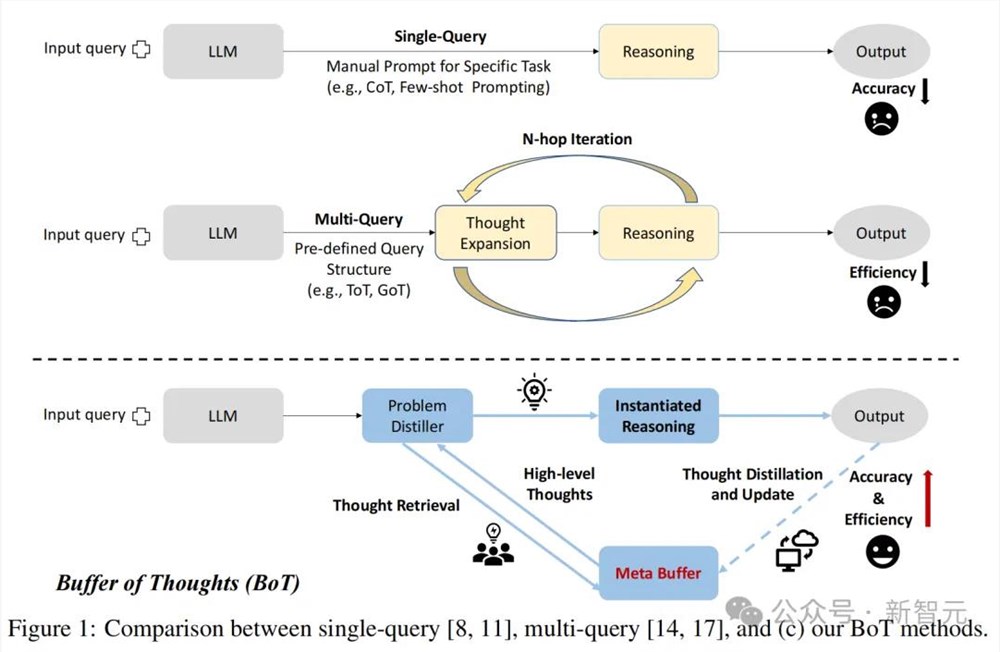
单查询、多查询都和BoT方法之间的比较
BoT有三个关键优势——
1. 准确性:通过共享的思维模板,LLM可以自适应地实例化高层次思维来解决不同任务,由于期间无需从头构建推理结构,因此推理的准确性便得到了提高。
2. 推理效率:通过思维增强推理,LLM能够直接利用信息丰富的历史推理结构进行推理,由于期间无需复杂的多查询过程,因此推理的效率便得到了提高。
3. 鲁棒性:从思维检索到思维实例化的过程,类似于人类的思维过程,这就让LLM能够以一致的方式解决类似问题,从而显著增强了模型的鲁棒性。

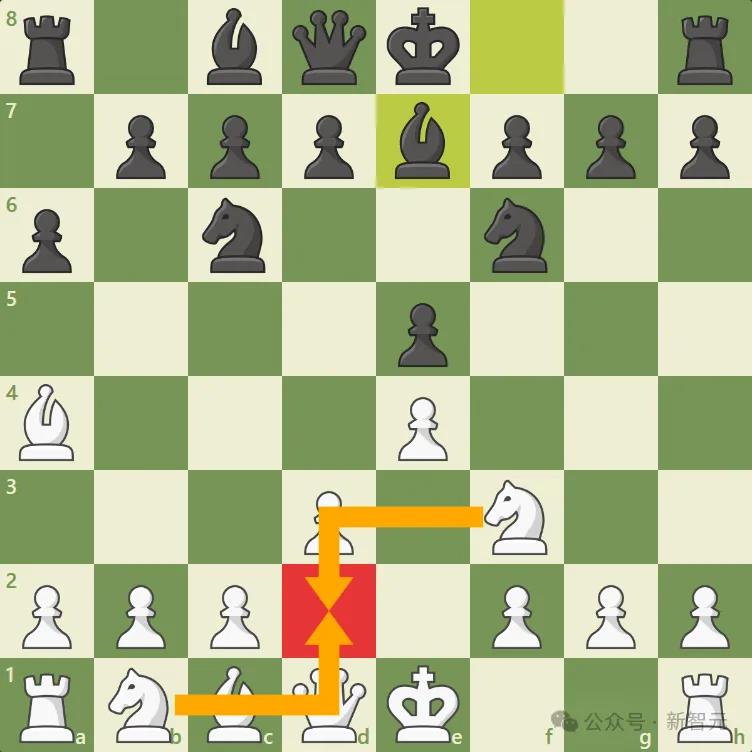
国际象棋中的「一步将死」
Buffer of Thoughts
从图2中,可以看出BoT是怎样用核心思维增强推理任务的。
对于给定的特定任务,团队首先会用问题蒸馏器来提取关键认为的具体信息,以及相关限制。
蒸馏出这些信息后,就可以在包含了一系列高级思维(思维模板)的元缓冲区中进行搜索了。这个过程中,会检索到与任务最相关的思维模板。

随后,就可以用更多特定任务的推理结构,实例化搜索到的思维模板,进行推理过程。
最后一步,就是使用缓冲区管理器来总结整个问题解决过程,并且蒸馏出增加其容量的高层思维。

不同推理过程的示意图(橙色为思维模板,蓝色为实例化的思维)
问题蒸馏器
大多数复杂任务,都包含隐含的约束、复杂的对象关系以及上下文中的复杂变量和参数。
因此,在推理阶段,LLM需要克服三个主要挑战:提取重要信息、识别潜在约束以及进行准确推理。
对于单个LLM,这些挑战会造成显著的负担。
因此,团队选择将任务信息的提取和理解阶段与最终的推理阶段分开,通过在推理过程中添加一个问题蒸馏器来实现。
为此,他们设计了一个元提示(meta prompt)φ,用于首先蒸馏和形式化任务信息。
蒸馏后的任务信息可以表示为:
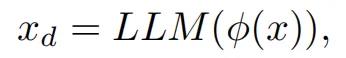
问题蒸馏器的详细元提示如下:

作为信息蒸馏领域的高度专业和智能专家,你擅长从用户输入查询中提取关键信息以解决问题。你能够熟练地将提取的信息转化为适合相应问题类型的格式。
请分类并提取解决问题所需的关键信息,包括:
1. 关键信息:从用户输入中提取的关键变量的值和信息,这些信息将交给相应的专家进行任务解决,确保提供解决问题所需的所有必要信息。
2. 限制条件:问题的目标和相应的约束。
3. 蒸馏任务:基于1和2扩展问题,总结一个可以解决用户查询并处理更多输入和输出变化的元问题。结合扩展问题的真实场景以及原始问题中的关键变量类型和信息约束来限制扩展问题中的关键变量。之后,使用用户查询输入的关键信息作为输入来解决问题作为示例。
用元缓冲区,让思维推理增强
- 动机
人类在解决问题时,常常总结和归纳出高层次的指导方针,然后将其应用于相关问题。
正是受此启发,团队提出了元缓冲区(meta-buffer),这是一种包含一系列高层次思维(思维模板)的轻量级库,用于解决各种类型的问题。
与传统方法不同,这种高层次思维模板可以在解决不同问题时自适应地实例化,从而为LLM提供更高的精度和灵活性。
- 思维模板
作为一种高层次的指导方针,思维模板存储在元缓冲区中,并由缓冲区管理器从各种问题解决过程中获取。
为了让BoT能够为各种任务提供通用的推理方法,团队相应地将思维模板分类为六类:文本理解、创造性语言生成、常识推理、数学推理、代码编程和应用调度。
这样的思维模板分类,可以促进模板检索,找到最适合解决不同问题的方案。
其中,思维模板、模板描述及其对应的类别表示为 (Ti, D_Ti, Ck),其中i表示元模板的索引,k∈Z^ 且1≤k≤6。
以下就是六个不同类别的思维模板示例。
1.文本理解
在这个任务中,LLM需要分析一张涉及企鹅各种属性(如姓名、年龄、身高、体重)的表格,然后回答有关这些属性的问题。

解决方案描述:
为了准确回答有关企鹅属性的问题,必须能够解释表格形式的数据,理解自然语言提供的附加信息,并运用逻辑推理来识别正确的属性。
思维模板:
步骤1:解析初始表格,提取标题信息和每只企鹅的属性到结构化格式中(例如,一个字典列表)。
步骤2:阅读并整合任何更新或添加到表格中的自然语言信息,确保数据保持一致。
步骤3:识别所问的属性(例如,最老的企鹅、最重的企鹅)和表格中的相应列。
步骤4:运用逻辑推理比较所有条目的相关属性,以找到正确答案(例如,最老的企鹅的最高年龄)。
步骤5:从提供的选项中选择与逻辑比较结果相匹配的答案。

2.创造性语言生成
在这项任务中,LLM需要生成一首十四行诗,遵循传统的押韵模式「ABAB CDCD EFEF GG」,并在诗中逐字包含三个特定的词。

解决方案描述:
写十四行诗需要创作14行诗歌,遵循特定的押韵模式。这些诗行通常采用抑扬格五音步,但为了创意可以在节奏上进行适当调整。给定的押韵模式规定了每行的结尾音,以确保诗歌的结构性。逐字包含提供的三个词需要在诗行中进行巧妙安排,以保持诗歌的连贯性和主题一致性。
思维模板:
步骤1:确定必须包含在十四行诗中的三个词。
步骤2:理解押韵模式「ABAB CDCD EFEF GG」,并准备一份可以使用的押韵词列表。
步骤3:为十四行诗设计一个可以自然包含这三个词的主题或故事。
步骤4:开始起草十四行诗,按照「ABAB」押韵模式写第一节(四行),确保包含一个或多个提供的词。
步骤5:继续写第二节「CDCD」,第三节「EFEF」,最后是结束的对联「GG」,每次根据需要包含提供的词。
步骤6:检查十四行诗的连贯性、流畅性和对押韵模式的遵循情况,并根据需要进行调整。

3.常识推理
在这项任务中,会给出任务的日期和事件(例如假期或历史事件),让LLM确定日期。
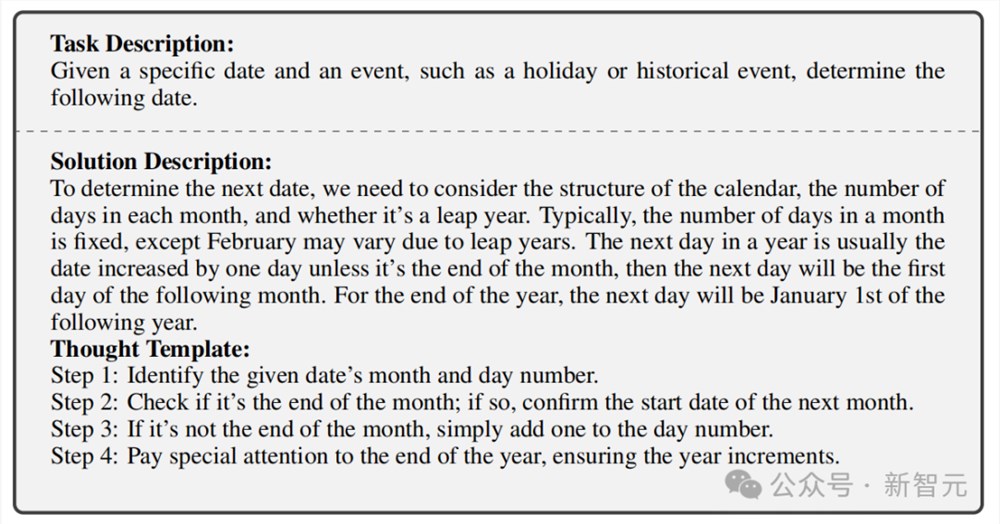
解决方案描述:
要确定下一个日期,我们需要考虑日历的结构、每个月的天数以及是否是闰年。通常,每月的天数是固定的,但二月可能因闰年而有所不同。一年中的第二天通常是日期增加一天,除非是月底,那么第二天将是下个月的第一天。对于年底第二天将是下一年的1月1日。
思维模板:
步骤1:识别给定日期的月份和日期。
步骤2:检查是否是月底;如果是,则确认下个月的开始日期。
步骤3:如果不是月底,只需在日数上加一即可。
步骤4:特别注意年底,确保年份递增。
4.数学推理
在这项任务中,LLM需要解决形式为ax^2 bx c =0的二次方程,并考虑所有可能的情况。

5.代码编程
在这项任务中,会给定一组数字,此时LLM需要尝试利用四种基本数学运算(加、减、乘、除)来得到目标数字。

6. 应用调度
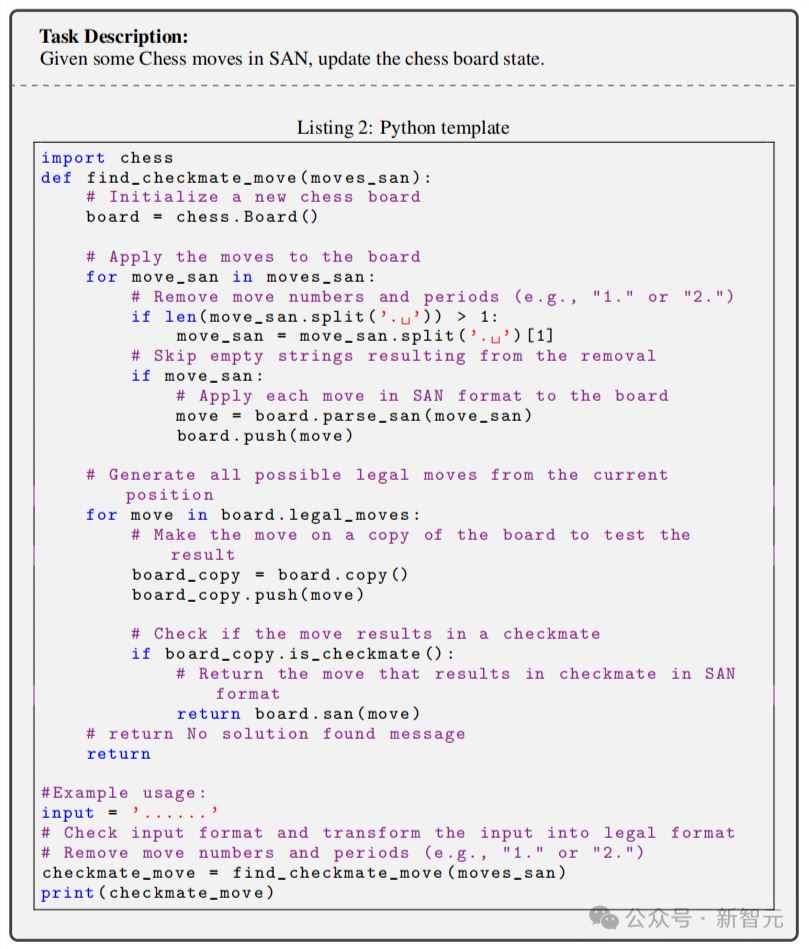
在这项任务中,LLM需要根据给定的国际象棋的标准代数记谱法(SAN)棋步,更新棋盘状态。
- 模板检索
对于每个任务,BoT会通过计算描述D_Ti和蒸馏问题xd之间的嵌入相似性,检索出与蒸馏问题xd高度相似的思维模板Ti。
其中,检索过程可以表述为:
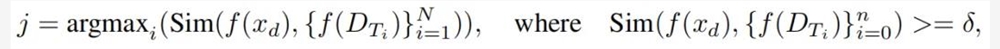
- 实例化推理
第一种情况是BoT成功为任务检索到一个思维模板Tj。
这时,BoT将使用团队设计的实例化提示自适应地实例化为合适的推理结构。
例如,在一步将死问题中,就会使用蒸馏信息xd和检索到的模板Tj对任务x进行实例化推理,并生成其解决方案Sx,如下所示:
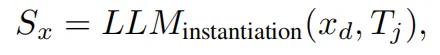
第二种情况是BoT将该任务被识别为一个新的任务。
为此,团队准备了三个通用的粗粒度思维模板,而BoT则会基于蒸馏的任务信息xd,自动分配一个合适的思维模板到推理过程中。

你是一位元推理者,精通各个领域的知识,包括计算机科学、数学、物理、文学、历史、化学、逻辑推理、文化、语言等。你还能根据不同任务找到合适的高级思维方式。以下是三种推理结构:
i) 基于提示的结构:在处理常识推理、应用调度等问题时表现良好。
ii) 基于过程的结构:在处理创造性任务如创造性语言生成和文本理解时表现良好。
iii) 基于编程的结构:在处理数学推理和代码编程时表现良好,还可以将现实世界的问题转化为编程问题,从而高效地解决问题。
(推理实例化)
你的任务是:
1. 深思熟虑地考虑上下文和问题蒸馏器蒸馏出的响应中的问题,并利用你对问题的理解找到适合解决问题的领域专家。
2. 考虑蒸馏的信息,为问题选择一种推理结构。
3. 如果提供了思维模板,请直接按照思维模板实例化给定问题。
缓冲区管理器
缓冲区管理器(buffer-manager)的作用是,总结从每个问题解决过程中获得的高层次指导方针和思维。
它可以将每个具体解决方案推广到更多问题中,并以思维模板的形式将关键的蒸馏知识存储在元缓冲区中。
与为每个问题临时生成示例或指令的方法不同,缓冲区管理器可以确保在准确性、效率和鲁棒性方面的永久性提升。

模板蒸馏提示:
用户:[问题描述] [解决方案步骤或代码]
要提取和总结解决此类问题的高级范例和一般方法,请按照以下步骤进行回复:
1. 核心任务总结:
识别并描述问题的基本类型和核心挑战,例如将其分类为数学问题(例如,求解二次方程)、数据结构问题(例如,数组排序)、算法问题(例如,搜索算法)等,并分析解决问题的最有效方法。
2. 求解步骤描述:概述求解的一般步骤,包括如何定义问题、确定变量、列出关键方程或约束、选择合适的求解策略和方法,以及如何验证结果的正确性。
3. 通用答案模板:根据上述分析,提出一个可以泛应用于此类问题的模板或方法,包括可能的变量、函数、类定义等如果是编程问题,提供一组基类和接口可用于构建具体问题的解决方案。
请确保你的回答高度简洁和结构化,以便具体解决方案可以转化为可推广的方法。
[可选]以下是思想模板的一些示例:(选择跨任务或-基于核心任务总结分析的任务范例。)
- 模板蒸馏
为了提取通用的思维模板,团队提出了一个三步法:
(1)核心任务总结:识别并描述问题的基本类型和核心挑战;
(2)解决步骤描述:总结解决问题的一般步骤;
(3)通用回答模板:基于上述分析,提出一个可以广泛应用于类似问题的解决模板或方法。
此外,为了提高模板蒸馏的泛化能力和稳定性,团队精心设计了两种上下文示例来生成思维模板——任务内示例和跨任务示例。
跨任务示是指,选择从某个任务中蒸馏出的模板,来解决其他任务的问题。例如,用与代码相关的思维模板来解决数学问题。
从输入任务x中蒸馏出的新模板可以表示为:
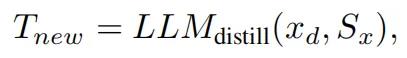
- 元缓冲区的动态更新
在模板蒸馏之后,需要考虑是否将蒸馏的模板更新到元缓冲区中。
- 如果初始化了一个空的元缓冲区或遇到没有合适思维模板的问题,蒸馏的思维模板将直接存储在元缓冲区中;
- 如果是用了检索到的思维模板解决的问题,也可能会在实例化某个思维模板的过程中会产生新的见解。
因此,为了在保持新生成有用思维的同时避免元缓冲区的冗余,需要计算
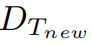
和
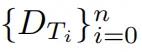
。
的嵌入向量之间的相似性,并根据以下规则更新元缓冲区:
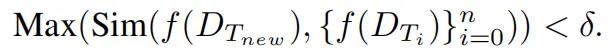
否则,这意味着元缓冲区已经具备解决此任务所需的知识,不需要进行更新。
这种动态更新策略有效减少了模板检索的计算负担,同时确保了元缓冲区的轻量化特性。
实验结果
- 数据集和任务
为了评估BoT的有效性,并与之前的方法进行比较,团队选择了一组多样化的任务和数据集。
这些任务和数据集需要不同程度的数学和算法推理、特定领域知识以及文学创造力:
1. 来自ToT的24点游戏(Game of24)
2. 三个BIG-Bench Hard (BBH)任务:几何图形(Geometric Shapes),多步算术二(Multi-Step Arithmetic Two),和单词排序(Word Sorting);
3. 直接从BIG-Bench中获得的三个推理任务:一步将死(Checkmate-in-One)、企鹅(Penguins),以及日期理解(DateUnderstanding);
4. Python编程题(P3),一组用Python编写的具有不同难度级别的挑战性编程题;
5. 多语言小学数学(MGSM),GSM8K数据集的多语言版本,包含十种语言类型(包括孟加拉语、日语和斯瓦希里语);
6. 根据元提示进行的莎士比亚十四行诗写作(Sonnet Writing)。

- 实现和基线
为了与之前的方法进行公平比较,团队选择了GPT-4作为BoT的基线模型。
并且还在NVIDIA A100-PCIE-40GB GPU上使用Llama3-8B和Llama3-70B进行了分析。
更好的准确性、效率和鲁棒性
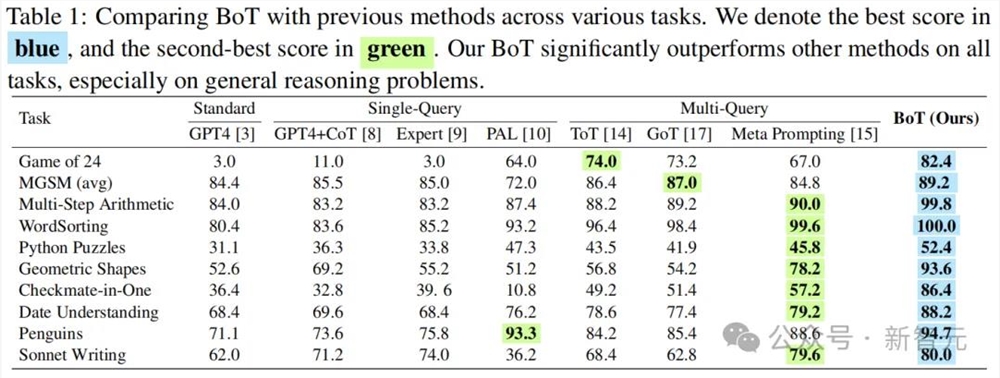
- 推理准确性
结果显示,BoT在多个具有挑战性的基准测试中始终优于所有之前的提示方法,特别是在诸如如24点游戏和一步将死这类的复杂推理任务上。
在24点游戏中,与原始GPT-4相比,BoT的准确性实现了高达79.4%的惊人提升;而与该项之前的SOTA——ToT相比,BoT也实现了8.4%的提升。
与最近提出的元提示相比,BoT在24点游戏中提高了23%的准确性,在几何图形中提高了20%,在一步将死中提高了51%。
现有方法需要复杂的、迭代的和启发式的搜索策略来逐个解决这些问题。
而BoT则会利用思维模板中的历史见解和信息性指导方针,并自适应地实例化一个更优的推理结构来解决这些复杂问题。
- 推理效率
除了在准确性上有着显著提升之外,作为一种多查询方法,BoT在各种任务中还可以实现与单查询方法相当的推理时间,同时显著少于传统的多查询方法(如ToT)。
例如,在24点游戏中,单查询和多查询方法都需要迭代和启发式搜索来找到可行的解决方案。
这个过程特别耗时且效率低下,尤其是对于多查询方法,它涉及进行多次查询搜索和回溯阶段。
相比之下,BoT能够直接检索代码格式的思维模板,从而实例化一个程序来遍历数字和符号的组合,从而无需从头构建推理结构。
这使得在调用问题蒸馏器后,仅用一次查询即可解决问题,显著减少了复杂推理所需的时间。
值得注意的是,BoT平均仅需多查询方法12%的成本。
- 推理鲁棒性
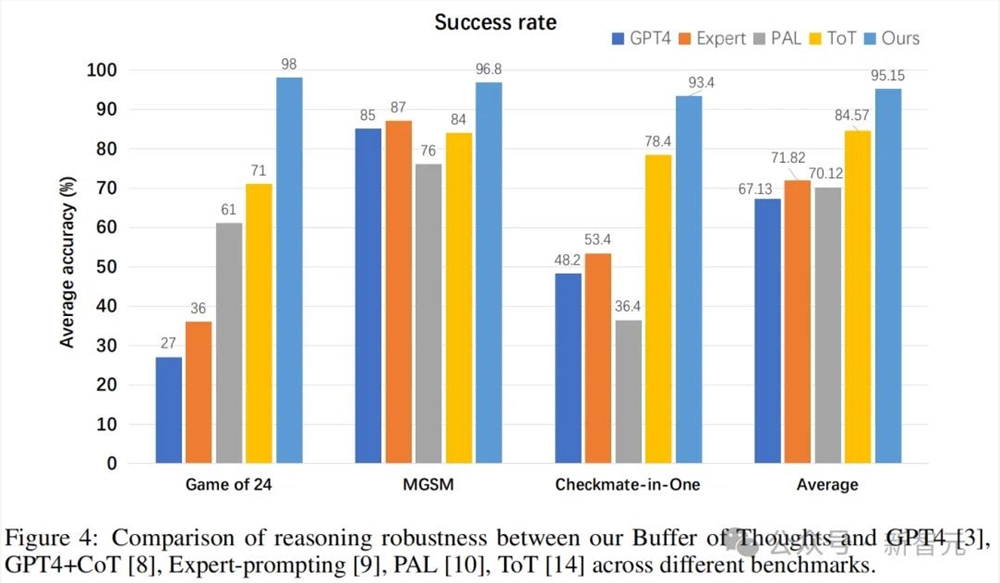
为了更好地评估BoT,团队设计了一种用于评估推理鲁棒性的新指标——成功率。
首先,从各种基准中随机抽取1000个示例作为测试子集,并在该子集上评估不同的方法。其次,重复这一评估过程10次,并将平均准确率作为不同方法在每个基准上的成功率。
结果显示,与其他方法相比,BoT在各种任务中都保持着最高的成功率——
不仅在平均成绩上,比ToT高出了10%;甚至在24点游戏中,比原始的GPT-4高出了71%之多。
这是因为BoT在不同任务中蒸馏的思维模板,有着出色的泛化能力。通过利用思维模板中提供高层次思维,BoT在不同任务中的稳定性得到了极大提升。
模型分析
- 思维模板的分布分析
测试结果显示,在包含更多多样化场景的MGSM任务中,BoT生成了更多的思维模板。而在相对简单的任务中,则生成了更具针对性的固定思维模板。
模板的分布表明,BoT可以有效地为不同的基准发现合适的思维模板。
- 时间成本分布分析
在时间成本方面,蒸馏任务信息和模板检索所需的时间相对较短,而实例化推理所需的时间较长。
考虑到不同组件的复杂性,BoT整体上还是实现了相对平衡的时间成本分布,展示出了新框架的高效。
思维模板和时间的分布分析(左为思维模板;右为时间成本)
- 更好的规模与性能权衡
可以看到,原始Llama3-8B和Llama3-70B模型在测试任务中的表现很差,但在获得BoT的加持之后,它们的准确性都有显著提升。
不仅如此,BoT Llama3-8B还在24点游戏和一步将死任务中成功实现了对Llama3-70B的大幅超越。
消融研究
- 问题蒸馏器的影响
当问题蒸馏器被禁用时,Llama3-70B和GPT-4的准确性都有所下降。
其中,在诸如24点游戏和一步将死这类更为复杂的问题上,降幅更为明显。而在诸如单词排序和MGSM这类相对简单的问题上,降幅较小。
这是因为,在处理复杂问题时,提取关键信息和潜在约束更具挑战性,由此使得问题蒸馏器的作用更加突出。
- 元缓冲区的影响
当元缓冲区被禁用时,Llama3-70B和GPT-4模型的性能显著下降,特别是在需要复杂推理的基准测试中,如24点游戏和一步将死。
这进一步强调了我们元缓冲区在解决复杂问题上的优势。
- 缓冲区管理器的影响
实验共分4轮,每一轮都会从各个基准中随机抽取50个问题并进行推理。
随着轮次的增加,带有缓冲区管理器的模型不断扩展元缓冲区,同时利用从先前解决的问题中获得的思维模板来帮助解决后续类似的问题。
因此可以看到,BoT的准确性在每一轮中稳步提高。相反,没有缓冲区管理器的模型未能表现出上升趋势。
推理时间方面,当轮次增加时,带有缓冲区管理器的模型的推理效率会持续提高。
这是因为随着元缓冲区的不断扩展,检索到合适思维模板的可能性也增加。因此,模型可以避免从头构建推理结构,从而相应地提高推理效率。
作者介绍
Ling Yang
论文的共同一作Ling Yang目前是北京大学的三年级博士生,导师是Bin Cui、Luxia Zhang和Ming-Hsuan Yang。
他的研究兴趣包括扩散模型(Diffusion Models)、多模态学习(Multimodal Learning)和AI for Science。
他曾担任多个国际会议和期刊的程序委员会成员或审稿人,包括SIGGRAPH、TPAMI、ICML、ICLR、NeurIPS、CVPR、KDD、AAAI。
崔斌(Bin Cui)
崔斌现为北京大学计算机学院教授、博士生导师,担任数据科学与工程研究所长。在相关领域顶级会议和期刊发表学术论文300多篇。
他主持和承担多个科研项目,如国家自然科学基金、国家重点研发计划、核高基项目、863计划等。
他担任/曾担任中国计算机学会理事、数据库专委会副主任,VLDB理事会理事,DSE期刊主编,IEEE TKDE、VLDB Journal、DAPD等国际期刊编委,担任过数十个国际会议的程序委员会委员,包括一流国际会议SIGMOD、VLDB、ICDE、KDD等。
参考资料:
https://arxiv.org/abs/2406.04271
小米14 Ultra国际版即将登场!小米官网开启倒计时
小米官方近日宣布,备受瞩目的小米14系列手机将于2月25日在海外市场正式亮相。此次发布不仅涵盖小米14和小米14Pro,更有备受期待的小米14Ultra。小米官网已提前预热,小米14Ultra国际版即将登场。这款新机的设计细节和配置信息也逐渐浮出水面。据悉,小米14Ultra将采用2K居中单孔等深四曲屏,分辨率高达2K,为用户带来卓越的视觉体验。站长网2024-02-07 10:54:000000研究:ChatGPT或币医生更好的遵循抑郁症治疗指南
划重点:1.AIChatGPT被认为可能比医生更好地遵循抑郁症的治疗标准,而且没有性别或社会阶层偏见。2.研究发表在英国医学杂志旗下的开放获取期刊《FamilyMedicineandCommunityHealth》上。3.ChatGPT与1,249名法国初级医生进行了比较,结果显示其在遵循抑郁症治疗指南方面表现出更高的准确性。站长网2023-10-18 11:43:050000韩国研究人员开发小样本学习模型,仅凭脑波数据就能发现人的意图
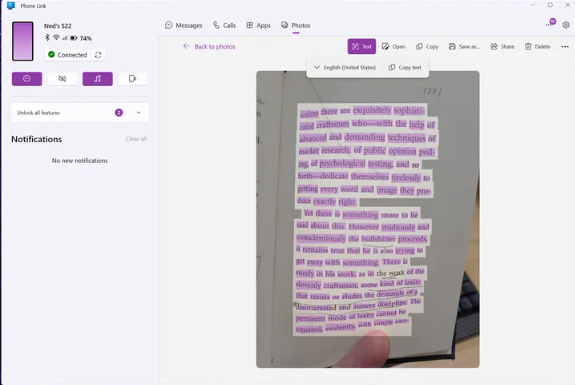
文章概要:1.研究团队成功开发了一种小样本学习模型,能够准确分类脑波,仅需少量信息。2.传统深度学习模型需要大量脑波数据,而新开发的模型可以即使使用少量数据也能准确分类脑波,有望推动脑波相关研究。3.研究团队采用了嵌入模块、时间注意模块、聚合注意模块和关系模块,成功提高了模型的分类准确性,为脑波研究提供了新的可能性。站长网2023-09-21 11:49:280000Windows新功能将允许用户从Android照片中提取文本
划重点:-MicrosoftPhoneLink的新功能允许您从Android手机的照片中选择和复制文本-这个功能目前在预览版本中可用,很快将向所有用户推出-WindowsSnippingTool去年已经添加了文本提取功能,但这次更新可以在应用内完成站长网2024-05-28 17:28:170001语音合成工具Narakeet:输入文本即可快速创建解说视频
Narakeet是一个语音合成工具,可以快速创建语音解说视频。它可以将PowerPoint、GoogleSlides或Keynote文稿转换为视频,还可以将文字脚本转换为音频文件。Narakeet提供了多种语言和声音选择,可用于创建培训视频、市场营销视频或作为YouTube视频的旁白。体验地址:https://www.narakeet.com/站长网2023-08-29 11:43:190004