支持合成一分钟高清视频,华科等提出人类跳舞视频生成新框架UniAnimate
人类跳舞视频生成是一项引人注目且具有挑战性的可控视频合成任务,旨在根据输入的参考图像和目标姿势序列生成高质量逼真的连续视频。随着视频生成技术的快速发展,特别是生成模型的迭代演化,跳舞视频生成任务取得了前所未有的进展,并展示了广泛的应用潜力。
现有的方法可以大致分为两组。第一组通常基于生成对抗网络(GAN),其利用中间的姿势引导表示来扭曲参考外观,并通过之前扭曲的目标生成合理的视频帧。然而,基于生成对抗网络的方法通常存在训练不稳定和泛化能力差的问题,导致明显的伪影和帧间抖动。
第二组则使用扩散模型(Diffusion model)来合成逼真的视频。这些方法兼具稳定训练和强大迁移能力的优势,相较于基于 GAN 的方法表现更好,典型方法如 Disco、MagicAnimate、Animate Anyone、Champ 等。
尽管基于扩散模型的方法取得了显著进展,但现有的方法仍存在两个限制:一是需要额外的参考网络(ReferenceNet)来编码参考图像特征并将其与3D-UNet 的主干分支进行表观对齐,导致增加了训练难度和模型参数;二是它们通常采用时序 Transformer 来建模视频帧之间时序依赖关系,但 Transformer 的复杂度随生成的时间长度成二次方的计算关系,限制了生成视频的时序长度。典型方法只能生成24帧视频,限制了实际部署的可能性。尽管采用了时序重合的滑动窗口策略可以生成更长的视频,但团队作者发现这种方式容易导致片段重合连接处通常存在不流畅的转换和外貌不一致性的问题。
为了解决这些问题,来自华中科技大学、阿里巴巴、中国科学技术大学的研究团队提出了UniAnimate 框架,以实现高效且长时间的人类视频生成。

论文地址:https://arxiv.org/abs/2406.01188
项目主页:https://unianimate.github.io/
方法简介
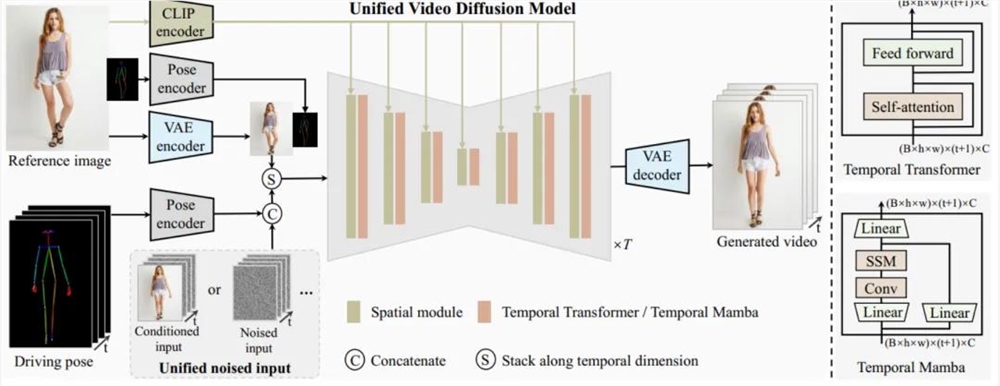
UniAnimate 框架首先将参考图像、姿势指导和噪声视频映射到特征空间中,然后利用统一的视频扩散模型(Unified Video Diffusion Model)同时处理参考图像与视频主干分支表观对齐和视频去噪任务,实现高效特征对齐和连贯的视频生成。
其次,研究团队还提出了一种统一的噪声输入,其支持随机噪声输入和基于第一帧的条件噪声输入,随机噪声输入可以配合参考图像和姿态序列生成一段视频,而基于第一帧的条件噪声输入(First Frame Conditioning)则以视频第一帧作为条件输入延续生成后续的视频。通过这种方式,推理时可以通过把前一个视频片段(segment)的最后一帧当作后一个片段的第一帧来进行生成,并以此类推在一个框架中实现长视频生成。
最后,为了进一步高效处理长序列,研究团队探索了基于状态空间模型(Mamba)的时间建模架构,作为原始的计算密集型时序 Transformer 的一种替代。实验发现基于时序 Mamba 的架构可以取得和时序 Transformer 类似的效果,但是需要的显存开销更小。
通过 UniAnimate 框架,用户可以生成高质量的时序连续人类跳舞视频。值得一提的是,通过多次使用 First Frame Conditioning 策略,可以生成持续一分钟的高清视频。与传统方法相比,UniAnimate 具有以下优势:
无需额外的参考网络:UniAnimate 框架通过统一的视频扩散模型,消除了对额外参考网络的依赖,降低了训练难度和模型参数的数量。
引入了参考图像的姿态图作为额外的参考条件,促进网络学习参考姿态和目标姿态之间的对应关系,实现良好的表观对齐。
统一框架内生成长序列视频:通过增加统一的噪声输入,UniAnimate 能够在一个框架内生成长时间的视频,不再受到传统方法的时间限制。
具备高度一致性:UniAnimate 框架通过迭代利用第一帧作为条件生成后续帧的策略,保证了生成视频的平滑过渡效果,使得视频在外观上更加一致和连贯。这一策略也使得用户可以生成多个视频片段,并选取生成结果好的片段的最后一帧作为下一个生成片段的第一帧,方便了用户与模型交互和按需调整生成结果。而利用之前时序重合的滑动窗口策略生成长视频,则无法进行分段选择,因为每一段视频在每一步扩散过程中都相互耦合。
以上这些特点使得 UniAnimate 框架在合成高质量、长时间的人类跳舞视频方面表现出色,为实现更广泛的应用提供了新的可能性。
生成结果示例
1. 基于合成图片进行跳舞视频生成。


2. 基于真实图片进行跳舞视频生成。


3. 基于粘土风格图片进行跳舞视频生成。
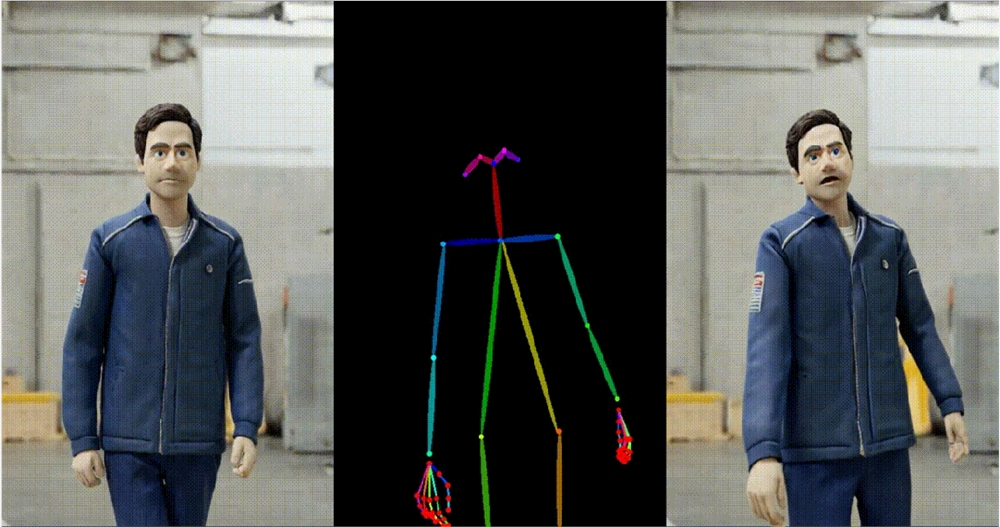

4. 马斯克跳舞。
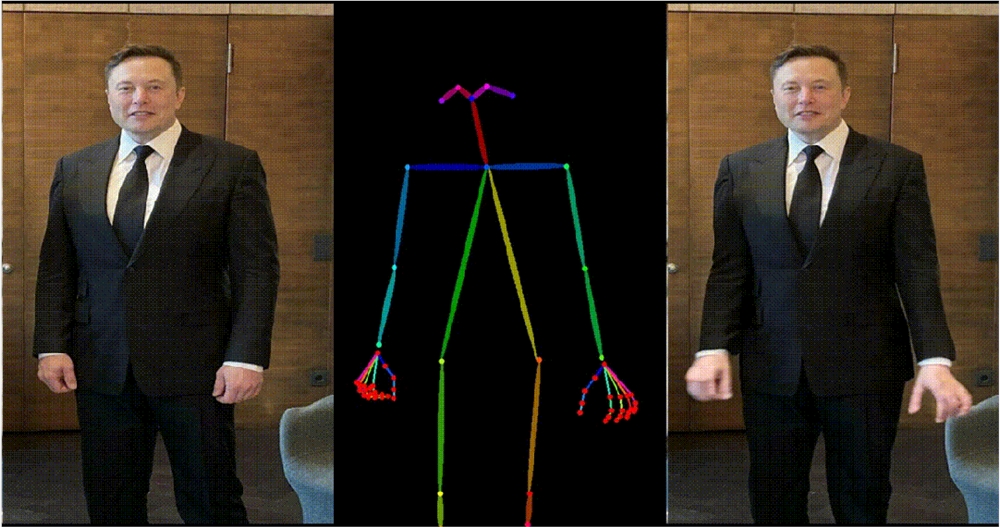
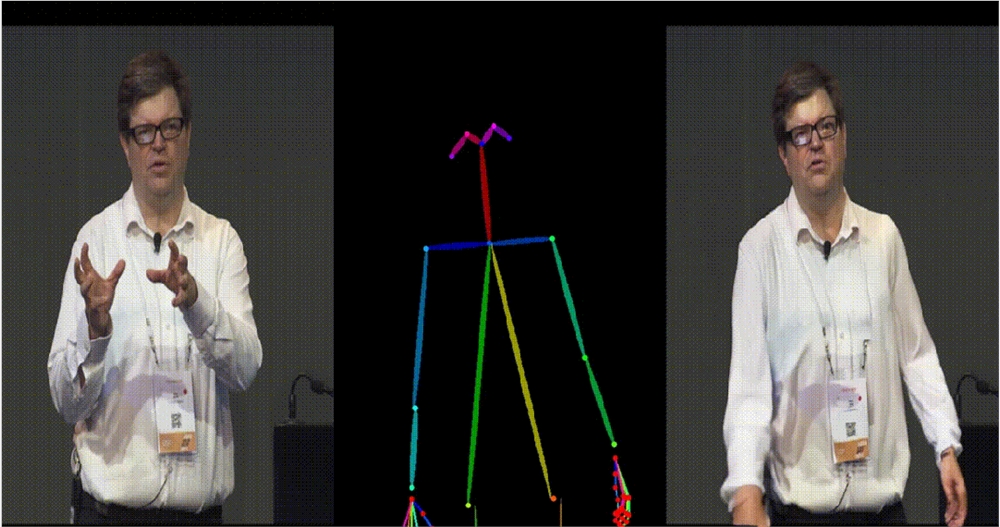
5. Yann LeCun 跳舞。
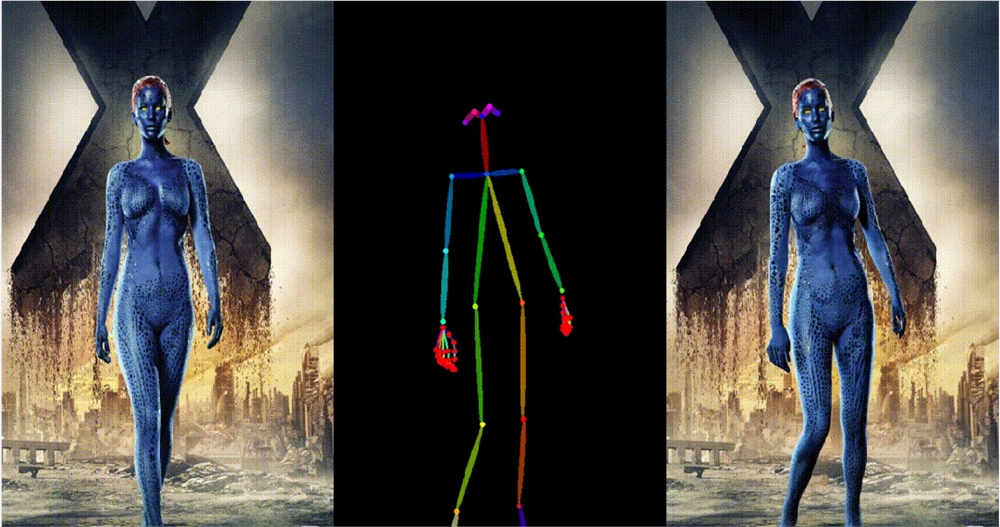
6. 基于其他跨域图片进行跳舞视频生成。
7. 一分钟跳舞视频生成。
,时长01:05
获取原始 MP4视频和更多高清视频示例请参考论文的项目主页https://unianimate.github.io/。
实验对比分析
1. 和现有方法在 TikTok 数据集上的定量对比实验。
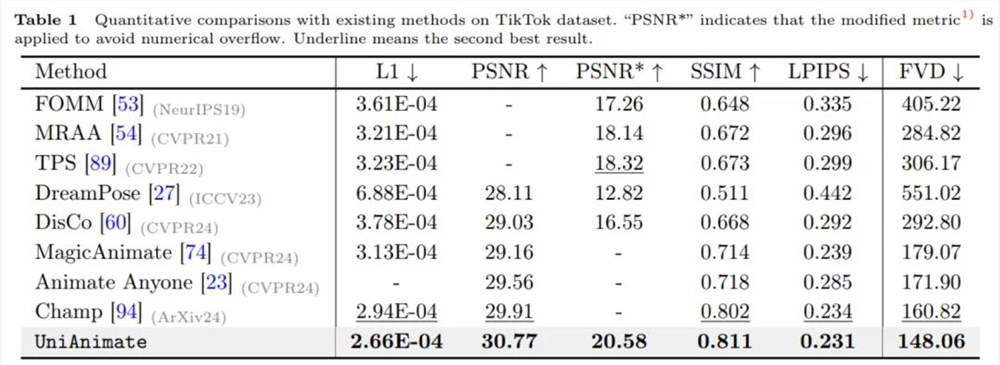
如上表所示,UniAnimate 方法在图片指标如 L1、PSNR、SSIM、LPIPS 上和视频指标 FVD 上都取得了最好的结果,说明了 UniAnimate 可以生成高保真的结果。
2. 和现有方法的定性对比实验。

从上述定性对比实验也可以看出,相比于 MagicAnimate、Animate Anyone, UniAnimate 方法可以生成更好的连续结果,没有出现明显的 artifacts,表明了 UniAnimate 的有效性。
3. 剥离实验。
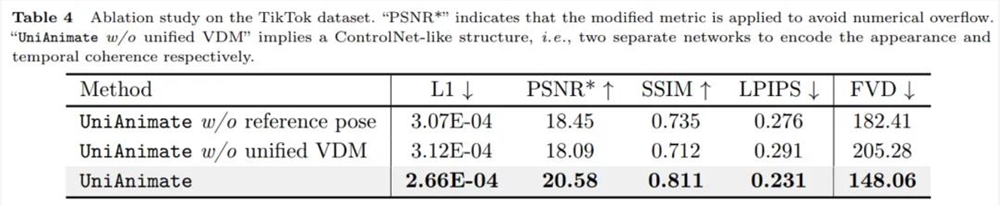
从上表的数值结果可以看出,UniAnimate 中用到的参考姿态和统一视频扩散模型对性能提升起到了很关键的作用。
4. 长视频生成策略对比。

从上图可以看出之前常用的时序重合滑动窗口策略生成长视频容易导致不连续的过渡,研究团队认为这是因为不同窗口在时序重合部分去噪难度不一致,使得生成结果不同,而直接平均会导致有明显的变形或者扭曲等情况发生,并且这种不一致会进行错误传播。而本文利用的首帧视频延续生成方法则可以生成平滑的过渡。
更多的实验对比结果和分析可以参考原论文。
总而言之,UniAnimate 的示例结果表现和定量对比结果很不错,期待 UniAnimate 在各个领域的应用,如影视制作、虚拟现实和游戏产业等,为用户带来更为逼真、精彩的人类形象动画体验。
7天B站涨粉20万,“猫meme”为何风靡全网?
“猫meme”正在入侵互联网。最近,一个名为“ねこのつぶやき”(猫的自言自语)的日本UP主在B站走红,短短半个月涨粉超27万。这位UP主是一名单亲妈妈,她分享了自己来中国生活后价值观发生变化的故事,不过她并没有真人出镜,而是加入了各种好玩的猫咪表情包进行视频剪辑,做成了“猫meme”版vlog。比如在去中国的飞机上,刚出生不久的孩子猛哭两小时,这里配上双手抱头尖叫的小奶猫表情;站长网2024-03-15 15:09:250000“李维刚的日常”周涨粉榜第一位,他是怎么突破低谷的?
有人说,健身和读书,是全世界成本最低的升值方式,所以要么读书,要么健身,灵魂和身体,必须有一个在路上。我们以为的健身教练还在健身房内挥汗如雨,殊不知,他们其实也是冲浪达人,早已活跃在互联网的前端。站长网2023-09-04 18:09:030000亚马逊现正向受邀请的买家销售 Astro:一款人工智能驱动的家用机器人
大约两年前,亚马逊的产品副总裁CharlieTritschler谈到了Astro,这是该公司智能家居机器人的第一代。Charlie反思性地解释了这个设备的愿景:「Astro是一种新型而不同寻常的机器人,旨在帮助客户完成各种任务,如家庭监控和与家人保持联系。它融合了人工智能、计算机视觉、传感技术、语音和边缘计算等新进展,打包成一个旨在实用和方便的设备。」站长网2023-05-10 16:42:210000日销破千元!AI生成的3D梗图挂件,被我们卖爆了
先说结论:我们花15天做的AI3D挂件,在线下卖爆了,单日营收破千元!故事的开始,是因为我们发现把AI3D打印手办做成一门小生意的可行性越来越高,这也激发了我们的“搞钱基因”。再加上前不久新榜在上海举办了「新榜内容节」,一拍即合,我们于是做了一批模型去大会现场摆摊试水!最后结果还不错,单日最高收入突破1000元,是我们“创业史”上的一个高光表现。站长网2025-04-10 15:34:350000小米任命栾剑为技术委员会 AI 实验室大模型团队负责人
小米集团近日发布一份内部邮件,任命栾剑为技术委员会AI实验室大模型团队的负责人,并向技术委员会副主席、AI实验室主任王斌汇报。公开资料显示,栾剑目前担任小米技术委员会AI实验室语音生成团队的负责人,之前曾担任东芝(中国)研究院研究员、微软(中国)工程院高级语音科学家、微软小冰首席语音科学家以及语音团队负责人等职位。站长网2023-04-15 15:07:400000