开源音频模型Stable Audio Open,文本生成47秒高清音效
站长网2024-06-06 17:42:593阅
6月6日,著名开源大模型平台Stability.ai在官网宣布,开源最新文生音频模型Stable Audio Open。
用户通过文本就能生成最多47秒,钢琴、笛子、鼓点、模拟人声等不同类型的44.1kHz音效。
值得一提的是,Stable Audio Open支持数据微调,歌手、音乐人可以让其生成基于自己的音乐数据,例如,架子鼓手可以根据自己的鼓点来进行微调。
开源地址:https://huggingface.co/stabilityai/stable-audio-open-1.0
在线demo:https://huggingface.co/spaces/artificialguybr/Stable-Audio-Open-Zero

根据Stability.ai介绍,Stable Audio Open使用了486,492个录音训练数据,其中472,618个来自Freesound,13874个来自免费音乐档案馆,并且所有音频文件均根据 CC0、CC BY或CC Sampling 获得了商业许可。
就是说通过Stable Audio Open生成的音效无需担心商业化问题,不会受到法律方面的追究。
「AIGC开放社区」根据其提供的在线demo体验了一下,在文本语义理解、生成音效等方面还是相当优秀。
需要注意的是,目前只支持英文提示词,其他任何语言都不行,即便你使用了识别效果也是相当的差。
在生成的过程中,用户可以对时间、扩散步数和CFG进行详细控制,以达到更好的效果。例如,一首非常舒适抒情的钢琴曲。

此外,Stable Audio Open目前只能用于学术研究,还无法商业化。
0003
评论列表
共(0)条相关推荐
Redmi Note13 Pro系列支持应用启动、退出打断动效
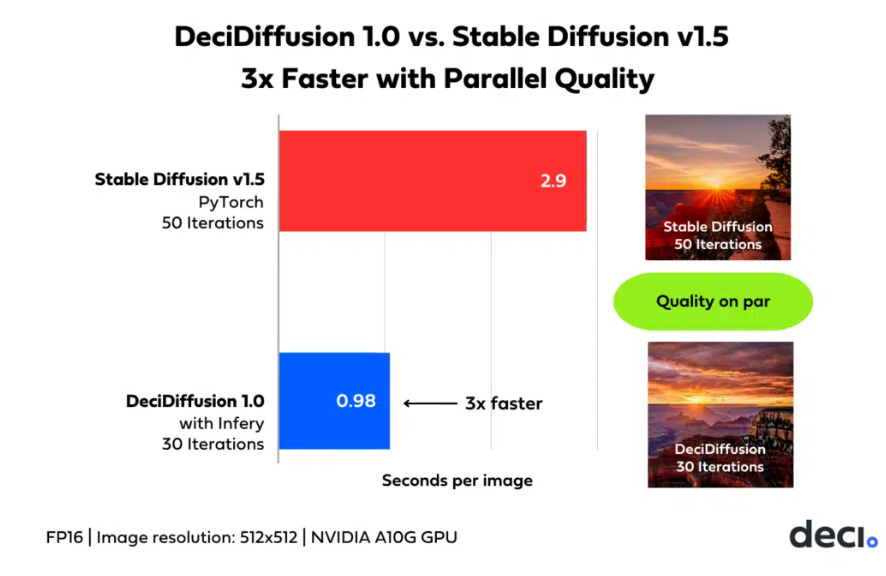
小米官方今日宣布RedmiNote13Pro系列系统迎来了一场重磅的革新升级。此次升级特别引入了应用启动和退出打断动效,让用户的日常使用变得更为流畅和丝滑。站长网2024-05-24 17:45:140000Deci AI推出8.2亿参数的文本到图像潜在扩散模型DeciDiffusion 1.0
要点:1.DeciAI推出DeciDiffusion1.0,这是一个具有8.2亿参数的文本到图像潜在扩散模型,速度比稳定扩散快3倍。2.DeciDiffusion1.0采用创新的U-Net-NAS架构,以更高效的方式生成高质量图像,并通过四阶段的培训过程优化了样本效率和计算速度。站长网2023-09-25 10:32:550000小米SU7 Max交付周期已达24-27周:现在下单6个月后提车
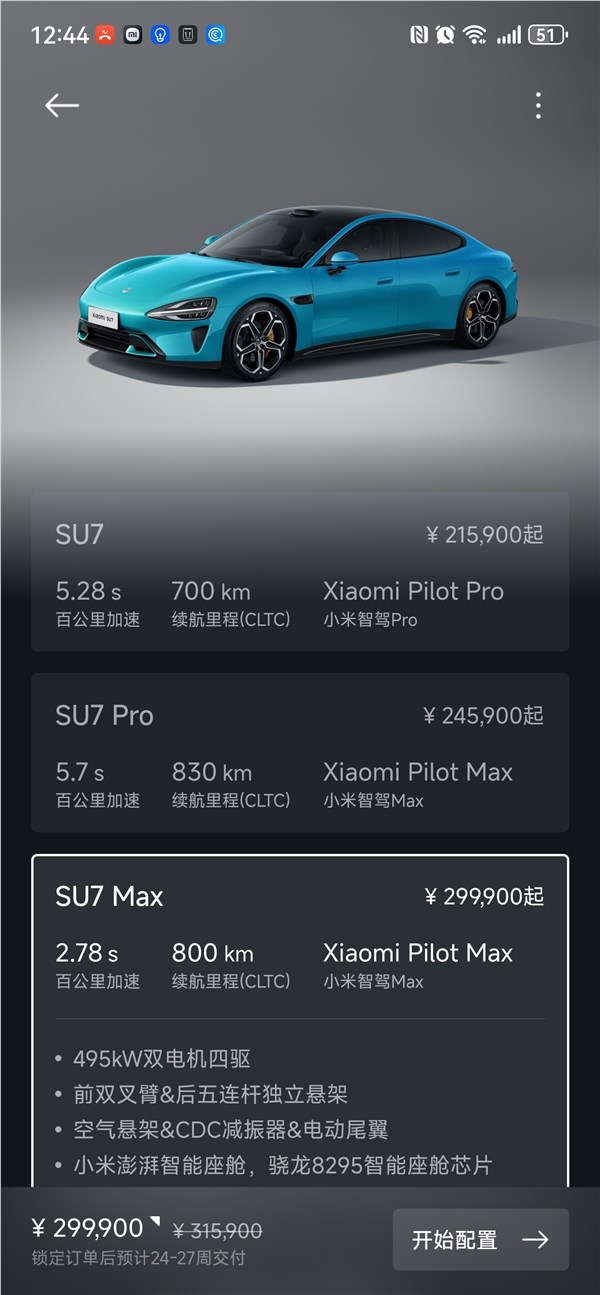
快科技3月31日消息,小米SU7上市后热度持续高涨。小米汽车APP显示,小米SU7标准版、Pro版、Max三个版本交付周期均已延长,最快13周,最慢27周。其中,标准版锁定订单后预计13-16周交付,Pro版预计16-19周交付。Max版则需24-27周交付。也就是说,现在下单Max版,最快也要6个月才能提车。站长网2024-04-06 14:14:000001谷歌突失Hinton!深度学习之父警告AI风险,对毕生工作表示遗憾
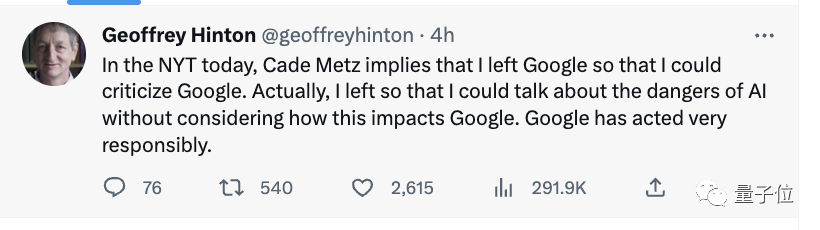
BreakingNews!深度学习三巨头、神经网络之父GeoffreyHinton已离职谷歌,结束十载生涯。最新推文中透露了原因:为了自由地讨论人工智能的风险。消息一出,整个科技圈炸了,人们震惊于AI已经让Hinton感到害怕了。有网友直接懵住:到底发生了什么?还是我漏掉了什么?你不是曾说过GPT-4为人类的蝴蝶吗?站长网2023-05-02 10:18:460001画颜AI:你的免费AI照相馆
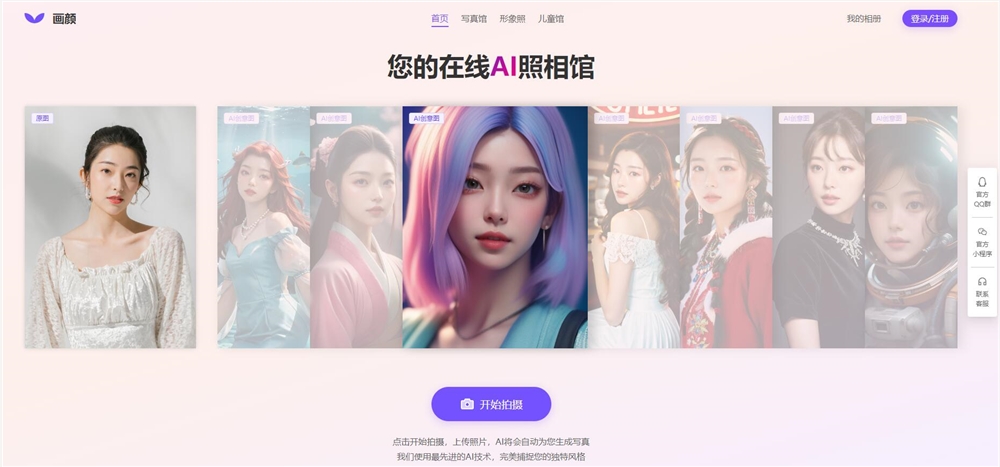
画颜AI写真是一款利用人工智能技术的在线照相馆应用,用户可以上传自己的照片,应用将自动为用户生成具有艺术感的写真。该应用能够快速捕捉用户的独特风格,并在短时间内创造出独特的照片模型。用户可以根据自己的喜好选择多种绘画风格和画布尺寸,定制属于自己的画作,并在社交媒体上分享自己的作品。体验地址:https://aihuayan.com/站长网2023-08-26 16:12:130000