生成式 AI 安全标准发布,覆盖训练数据和生成内容
划重点:
⭐ 中国发布《生成式 AI 安全基本要求》,涵盖训练数据、生成内容等
⭐ 标准要求细化了训练数据、生成内容和模型安全要求
⭐ 中国连续出台安全管理条例,展示对创新技术重视,保障人工智能应用安全
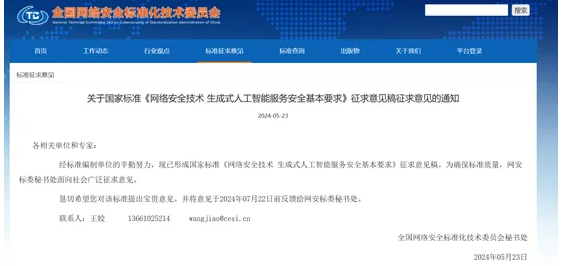
中国网络安全标准化技术委员会官网发布了《网络安全技术 生成式人工智能服务安全基本要求》征求意见稿。该标准细化了对生成式人工智能服务的安全要求,包括训练数据安全、生成内容安全和模型安全要求。其中,针对训练数据,要求对数据来源进行管理和核验,提高数据来源的多样性,并规定了使用开源、自采和商业训练数据的相关规定。
对于生成内容,要求进行内容过滤和知识产权管理,特别是对包含个人信息的训练数据,提出了使用授权和管理渠道等要求。在模型安全要求方面,标准要求在模型训练、输出、监测、更新、升级以及软硬件环境方面都有相应的安全措施和管理要求。
这一标准的发布展示了中国对生成式人工智能领域安全管理的重视程度,为该领域的健康发展保驾护航。同时,这也是中国连续出台安全管理条例,为人工智能应用场景的落地和应用安全提供了保障。整个标准的发布显示了对创新技术的重视,同时也保证了人工智能应用的安全性。
《生成式 AI 安全基本要求》内容如下:

数据来源安全
对服务提供者的要求如下。
a)采集来源管理:
1)面向特定数据来源进行采集前,应对该来源数据进行安全评估,数据内容中含违法不良信息超过5%的,不应采集该来源数据;
2)面向特定数据来源进行采集后,应对所采集的该来源数据进行核验,含违法不良信息情况超过5%的,不应使用该来源数据进行训练。
b)不同来源训练数据搭配:
1)应提高训练数据来源的多样性,对每一种语言的训练数据,如中文、英文等,以及每一种类型的训练数据,如文本、图片、音频、视频等,均应有多个训练数据来源;
2)如需使用境外来源训练数据,应与境内来源训练数据进行合理搭配。
c)训练数据来源可追溯:
1)使用开源训练数据时,应具有该数据来源的开源许可协议或相关授权文件;
2)使用自采训练数据时,应具有采集记录,不应采集他人已明确不可采集的数据;不可采集的网页数据,或个人已拒绝授权采集的个人信息等。
3)使用商业训练数据时:
应有具备法律效力的交易合同、合作协议等;
交易方或合作方不能提供数据来源、质量、安全等方面的承诺以及相关证明材料时,不应使用该训练数据;
应对交易方或合作方所提供训练数据、承诺、材料进行审核。
4)将使用者输入信息当作训练数据时,应具有使用者授权记录。
数据内容安全
a)训练数据内容过滤:对于每一种类型的训练数据,如文本、图片、音频、视频等,应在将数据用于训练前,对全部训练数据进行过滤,过滤方法包括但不限于关键词、分类模型、人工抽检等,去除数据中的违法不良信息。
b)知识产权:
1)应有训练数据知识产权管理策略,并明确负责人;
2)数据用于训练前,应对数据中的主要知识产权侵权风险进行识别,发现存在知识产权侵权等问题的,服务提供者不应使用相关数据进行训练;
注:训练数据中包含文学、艺术、科学作品的,需要重点识别训练数据以及生成内容中著作权侵权问题。
3)应建立针对知识产权问题的投诉举报渠道;
4)应在用户服务协议中,向使用者告知使用生成内容的知识产权相关风险,并与使用者约定相
关责任与义务;
5)应及时根据国家政策以及第三方投诉情况更新知识产权相关策略;
6)宜具备以下知识产权措施:
公开训练数据中涉及知识产权部分的摘要信息;在投诉举报渠道中支持第三方就训练数据使用情况以及相关知识产权情况进行查询。
c)个人信息方面:
1)在使用包含个人信息的训练数据前,应取得对应个人同意或者符合法律、行政法规规定的其他情形;
2)在使用包含敏感个人信息的训练数据前,应取得对应个人单独同意或者符合法律、行政法规规定的其他情形。
模型安全要求
对服务提供者的要求如下。
a)模型训练方面:
1)在训练过程中,应将生成内容安全性作为评价生成结果优劣的主要考虑指标之一;
注:模型生成内容是指模型直接输出的、未经其他处理的原生内容。
2)应定期对所使用的开发框架、代码等进行安全审计,关注开源框架安全及漏洞相关问题,识别和修复安全漏洞。
b)模型输出方面:
1)生成内容准确性方面,应采取技术措施提高生成内容响应使用者输入意图的能力,提高生成内容中数据及表述与科学常识及主流认知的符合程度,减少其中的错误内容;
2)生成内容可靠性方面,应采取技术措施提高生成内容格式框架的合理性以及有效内容的含量,提高生成内容对使用者的帮助作用;
3)问题拒答方面,对明显偏激以及明显诱导生成违法不良信息的问题,应拒绝回答;对其他问题,应均能正常回答;
4)图片、视频等生成内容标识方面,应满足国家相关规定以及标准文件要求。
c)模型监测方面:
1)应对模型输入内容持续监测,防范恶意输入攻击,例如注入攻击、后门攻击、数据窃取、对抗攻击等;
2)应建立常态化监测测评手段以及模型应急管理措施,对监测测评发现的提供服务过程中的安全问题,及时处置并通过针对性的指令微调、强化学习等方式优化模型。
d)模型更新、升级方面:
1)应制定在模型更新、升级时的安全管理策略;
2)应形成管理机制,在模型重要更新、升级后,再次自行组织安全评估。
e)软硬件环境方面:
1)模型训练、推理所采用的计算系统方面:
应评估系统所采用芯片、软件、工具、算力等方面的供应链安全,侧重评估供应持续性、稳定性等方面;
所采用芯片宜支持基于硬件的安全启动、可信启动流程及安全性验证。
2)应将模型训练环境与推理环境隔离,避免数据泄露、不当访问等安全事件,隔离方式包括物理隔离与逻辑隔离。
上面只是部分内容,整个安全标准书是非常详细的,有兴趣的可以去官网查看全部内容。
我国也是全球为数不多在生成式人工智能领域连续出台安全管理条例的国家,一方面展示了国家对创新变革技术的重视程度,另外保证了生成式人工智能的场景化落地和应用安全。
金字塔内部竟有“神秘空洞”?科学家是如何发现的?
你知道埃及金字塔的“神秘空洞”是如何被发现的吗?你知道外太空的高能宇宙射线是如何被探测的吗?其中很重要的一种方式,就是利用气体探测器。近日,中国原子能科学研究院核物理研究所团队实现了大面积、低功耗、高位置灵敏光刻一体化微结构探测器的自主可控。站长网2023-05-24 05:44:460000腾讯好未来入股AI公司深言科技
天眼查App显示,近日,北京深言科技有限责任公司发生工商变更,股东新增腾讯旗下广西腾讯创业投资有限公司、好未来旗下公司欣欣相融教育科技(北京)有限公司等,同时,注册资本由约131.6万人民币增至约183.5万人民币。站长网2023-06-03 13:06:060000OpenAI图像生成器DALL-E2停止服务,DALL-E3接替其位置
划重点:🛑DALL-E2停止服务,由DALL-E3替代🔍DALL-E3整合ChatGPT,提供更简单界面和更优质图像💡用户可在ChatGPT中使用DALL-E3生成更好的图像OpenAI宣布关闭DALL-E2图像生成器服务,由其后续产品DALL-E3替代。站长网2024-04-19 11:29:510002办公神器!10款自动做Excel表格的AI工具
当与其他数据来源相结合,包括营销数据平台时,Excel可以让一切一目了然。虽然大多数人认为Excel是电子表格程序,但它是一种强大的计算工具,能够解决复杂的问题。以往,要很好的利用Exce表格需要掌握很多复杂的公式。而这也成为很多人放弃使用这个工具的原因。而随着人工智能(AI)的发展,Excel用户不再需要记忆成百上千个复杂的长公式来进行复杂计算和获得全面的洞察力。站长网2023-08-22 11:53:150009一帧秒创:支持图文转视频,AI数字人等功能
一帧秒创是一款基于秒创AIGC引擎的智能AI内容生成平台,旨在为创作者和机构提供多种AI生成服务,包括文字续写、文字转语音、文生成图、图文转视频等多项创作服务。这个平台的核心特点是其智能分析技术,能够快速将文案、素材、AI语音和字幕等元素整合,创作出高质量的视频内容,无需复杂的编辑和制作过程。地址:https://aigc.yizhentv.com/以下是该产品的五大核心功能:站长网2023-09-26 10:58:020000