马斯克烧60亿美元难题,国内大厂有解?开源MoE模算效率黑马登场,3.7B参数单挑Llama 3-70B
【新智元导读】马斯克最近哭穷表示,xAI需要部署10万个H100才能训出Grok3,影响全球的大模型算力荒怎么解?昨天开源的这款MoE大模型,只用了1/19算力、1/19激活参数,性能就直接全面对标Llama3-70B!
如今,想训个SOTA的大模型,不仅缺数据和算力,甚至连电都不够用了。
最近马斯克就公开表示,因为苦于买不到足够的芯片,xAI只能推迟Gork2的训练和发布。
Grok3及更高版本,甚至需要10万个H100,按每台H100售价3万美元来算,仅芯片就要花掉28亿美元。
而且在未来几年,xAI在云服务器上可能就要花费100亿美元,直接逼得马斯克自谋生路,开建起自己的「超级计算工厂」。
那么问题来了,有没有一种可能,只用更少的算力,就让大模型实现更高的性能?
就在5月28日,浪 潮信息给业界打了个样——全面开源MoE模型「源2.0-M32」!
简单来说,源2.0-M32是一个包含了32个专家(Expert)的混合专家模型,总参数量达到了400亿,但激活参数仅37亿。
开源项目地址:https://github.com/IEIT-Yuan/Yuan2.0-M32
基于算法、数据和算力方面的全面创新,源2.0-M32的模型性能得到了大幅提升,一句话总结就是:模更强,算更优!
在业界主流的基准评测中,它的性能也能直接全面对标Llama3-70B!
32个小模型,挑战700亿Llama3巨兽
话不多说,先看跑分:
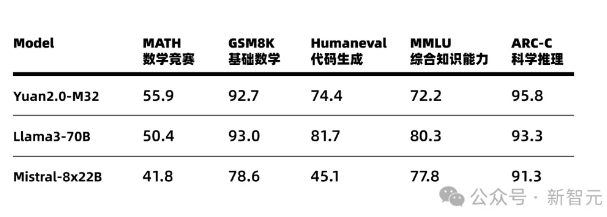
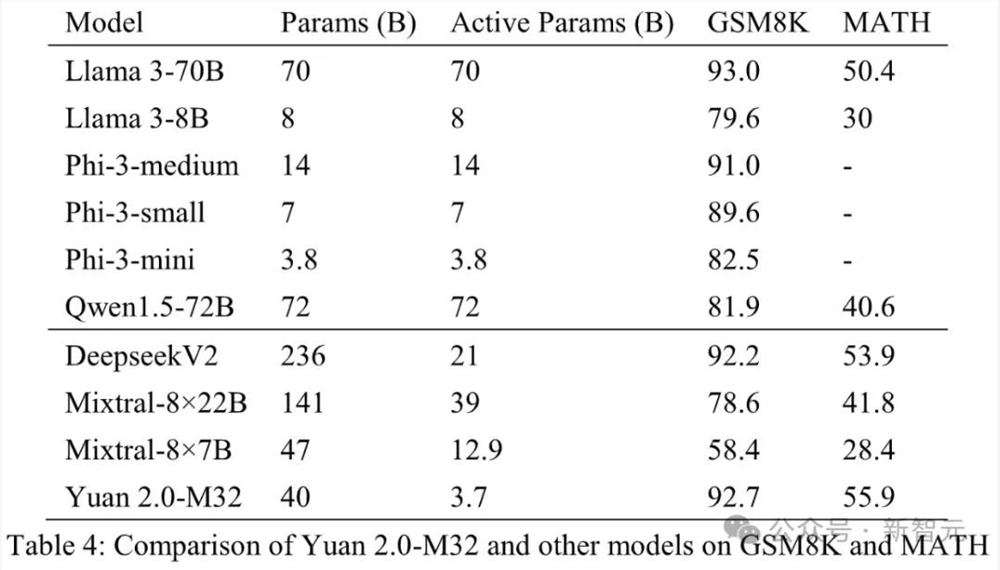
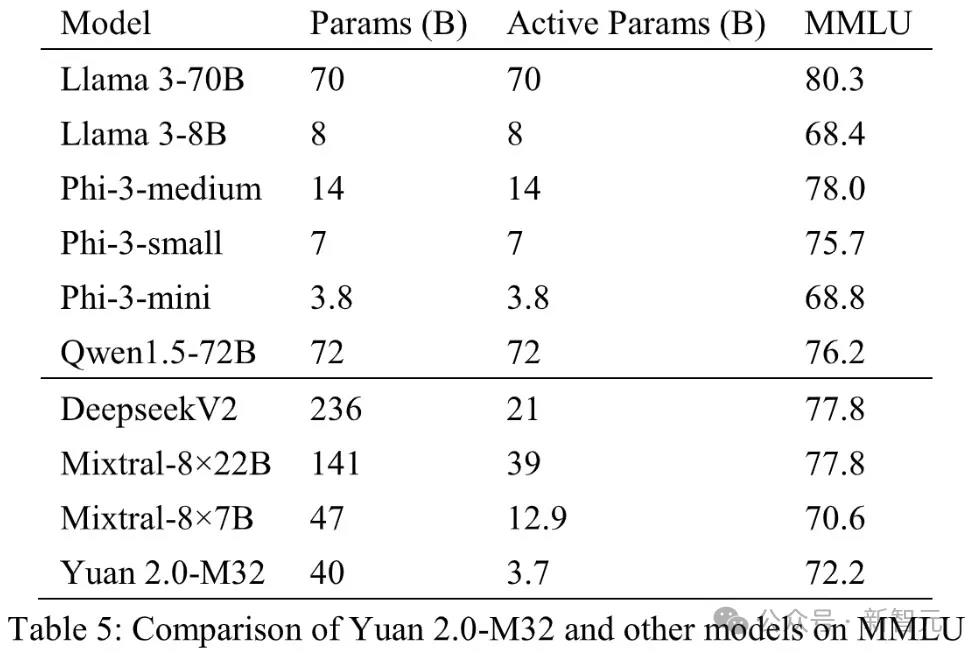
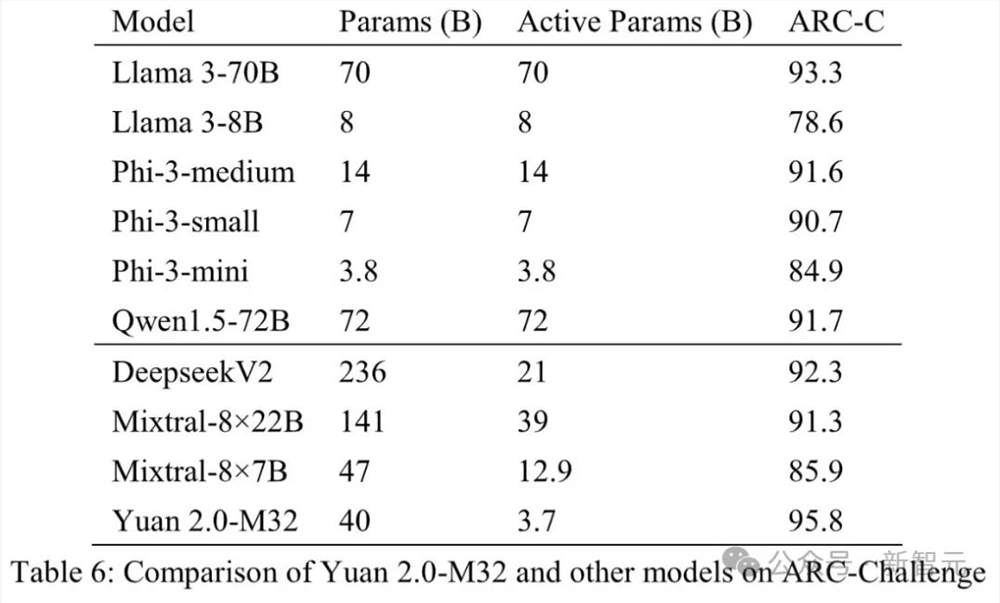
直观可见,在MATH和ARC-Challenge基准测试中,源2.0-M32的准确率分别为55.89和95.8,超过了Llama3-70B。
甚至在编码、MMLU中,M32实现了与Llama3-70B相当的性能。
在代码生成任务中,源2.0-M32的性能仅次于DeepseekV2和Llama3-70B,并远远超过其他模型。
与DeepseekV2相比,M32模型每个token使用的激活参数不到其1/4,计算量不足其1/5,而准确率达到其90%以上的水平。
而与Llama3-70B相比,模型激活参数和计算量的差距更大,但M32仍达到了其91%的水平。
在代码能力上,源2.0-M32不仅通过了近3/4的HumananEval测试题,而且在经过14个样本的学习之后,准确率更是提升到了78%。
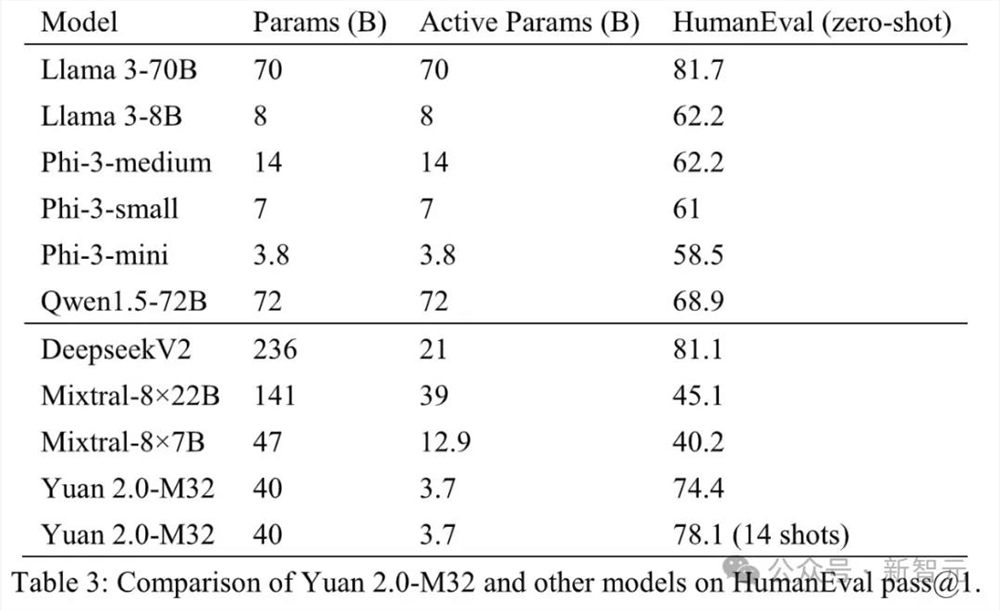

就数学任务结果来看,源2.0-M32在MATH基准测试中得分最高。
与Mixtral-8×7B相比,M32的激活参数只有它的约0.29倍,但性能却高出了近一倍。
在GSM8K基准上,M32的性能与Llama3-70B非常接近,并且超过了其他模型。
比如在回答「100-200之间,所有7的倍数的和是多少」的问题中,M32和Llama3-70B的PK结果如下。
因为对中文理解上的优势,M32成功给出了正确答案,而Llama3-70B就不幸翻车了。

当然,面对英文的数学题,M32也没在怕的。
注意,这道题的题干中提出了一个要求——分母应该是有理数,M32非常准确地获知了这一点,因而把1/√3变成了√3/3。
这就有点意思了。

下面这道题,要求计算997的的逆元,也即使997乘以某个数,让它对100的求余为1。
源2.0-M32非常准确地理解了这个过程,而且通过一步步的迭代,准确地求解出了一个具体数值。
而看这边的Llama3-70B,很明显就没有理解题干,也没有构建出准确的求解关系,结果也是错的。

在多语言测试MMLU中,源2.0-M32的表现虽然不及规模更大的模型,但优于Mixtral-8×7B、Phi-3-mini和Llama3-8B。
最后,在推理挑战中,源2.0-M32在解决复杂科学问题方面表现出色,同样超越了Llama3-70B。
创新的架构和算法
源2.0-M32研发的初衷,就是为了大幅提升基础模型的模算效率。
为了提升模型能力,很多人都会沿用当前的路径,但在浪 潮信息看来,要让模型能力真正快速提升,就一定要从算法层面、从模型架构层面做探索和创新。
从模型名字中便可以看出,源2.0-M32是基于「源2.0」模型构建的,是包含32个专家的MoE模型。
它沿用并融合局部过滤增强的注意力机制(Localized Filtering-based Attention),通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,更好地学习到了自然语言的局部和全局的语言特征。
因此,它对于自然语言的关联语义理解更准确,模型精度就得到了提升。

论文地址:https://arxiv.org/pdf/2405.17976
图1左展示了「源2.0」架构通过引入MoE层实现模型Scaling,其中MoE层取代了源2.0中的前馈层。
图1右放大显示了M32的MoE层的结构,每个MoE层由一组单独的密集前馈网络(FFN)作为专家组成。
专家之前的门控网络将输入的token,分配给总共32个相关的专家中的2个(图中以4个专家做为示例)。
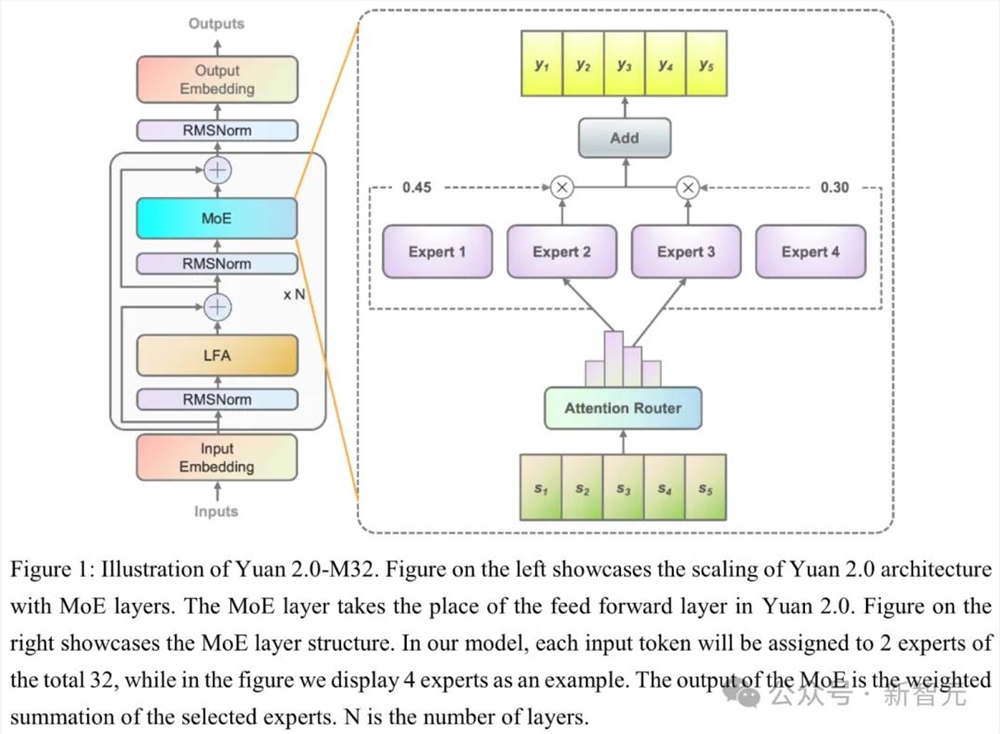
源2.0-M32结构示意图,其中MoE层取代了源2.0中的前馈层
其中,选择32个专家的原因是,比起8个、16个专家,32个专家的训练损失最低,效果最好。
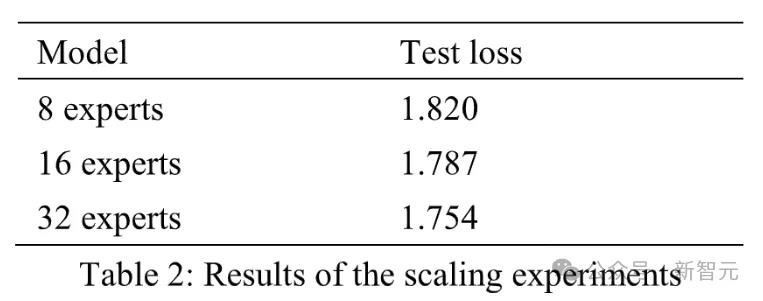
最终,虽然在推理过程中,32个专家每次只激活2个,激活参数只有37亿,但是M32在处理逻辑、代码方面,精度可以对标Llama3-70B。
全新门控网络AttentionRouter
在LFA之后,针对MoE结构中核心的门控网络,团队做了另外一个算法创新。
需要明确的是,混合专家模型由两个核心部分组成:一是门控网络(Gate),二是若干数量的专家(Expert)。
这当中,「门控机制」起着最关键的作用。
它通常会采用神经网络,根据输入的数据特征,为每个专家模型分配一个权重,从而决定哪些专家模型对当前任务更为重要。
简言之,通过计算token分配给各个专家的概率,来选择候选专家参与计算。
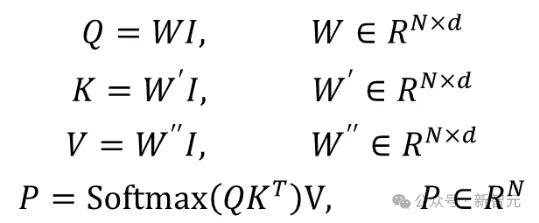
显然,门控网络的选择机制,对于模型的推理能力、运行效率起着关键的作用。
当前,流行的MoE结构大都采用简单的调度策略——将token与代表每个专家的特征向量进行点积,随后挑选点积结果最大的专家。
然而,这一方法的弊端是,只将各个专家特征向量视为独立的,进而忽略了它们之间的相关性,无疑会降低模型的精度。
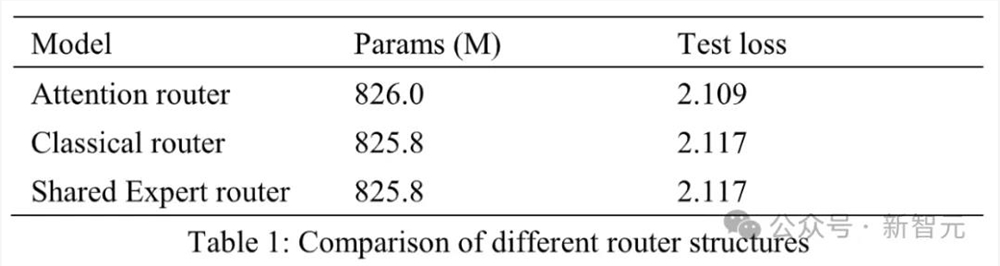
为了攻克这一难题,源2.0-M32创新性提出了新型的算法结构:基于注意力机制的门控网络(Attention Router),创造了一种专家间协同性的度量方法。
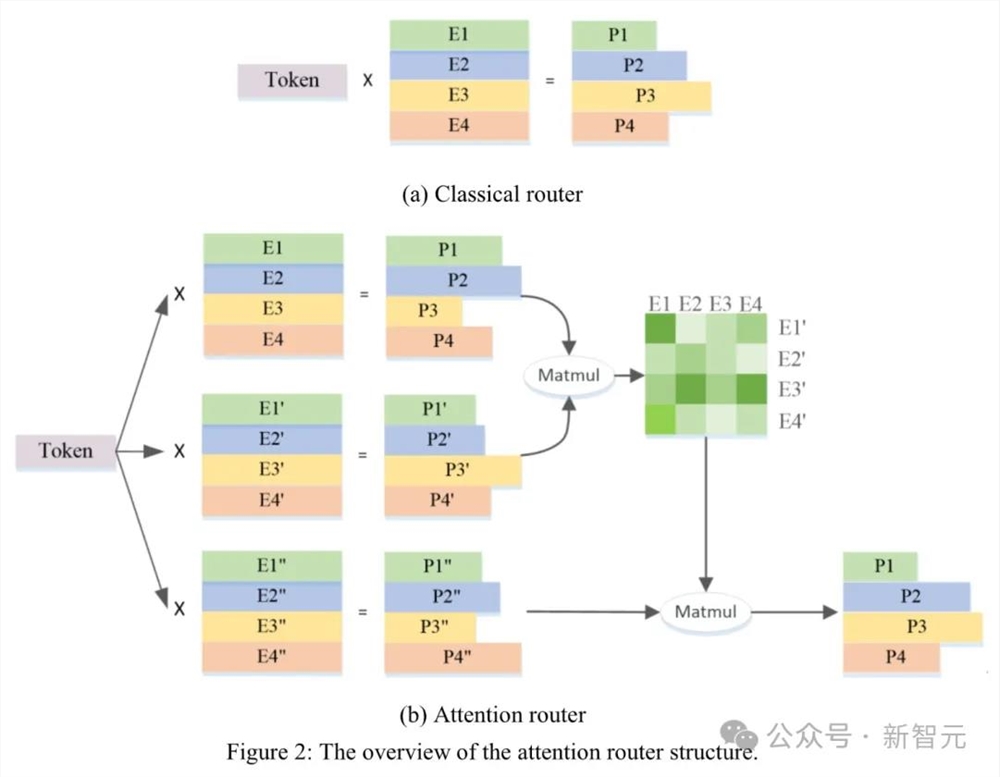
新策略可以在计算过程中,将输入样本中任意两个token,通过一个计算步骤直接联系起来。
这样一来,就可以解决传统的门控机制中,选择两个或多个专家参与计算时关联性缺失的问题。
最终选择的时候,这种策略选择的专家不仅绝对数值会比较高,两个专家协同的时候,自身的属性也会更相似。
举个通俗易懂的栗子:
就好比在一个医院中,主任要去做手术,一定是选择自己最这个领域最专业、且自己最熟悉的组员,这样大家的配合程度才会更好。
果然,与经典路由结构的模型相比,Attention Router让LLM准确率提升了3.8%。
总之,Attention Router算法可以让使得专家之间协同处理数据的水平和效能大为提升,从而实现以更少的激活参数,达到更高的智能水平。
算力消耗只需700亿Llama3的1/19
算力层面,源2.0-M32综合运用了流水线并行 数据并行的策略,显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。
正是基于算法和算力上创新优化,源2.0-M32实现了在三个阶段——预训练、推理和微调过程中,超高的模算效率。
这一突破,让MoE模型性能媲美Llama3-70B,也显著降低了单token训练和推理所需的算力资源。
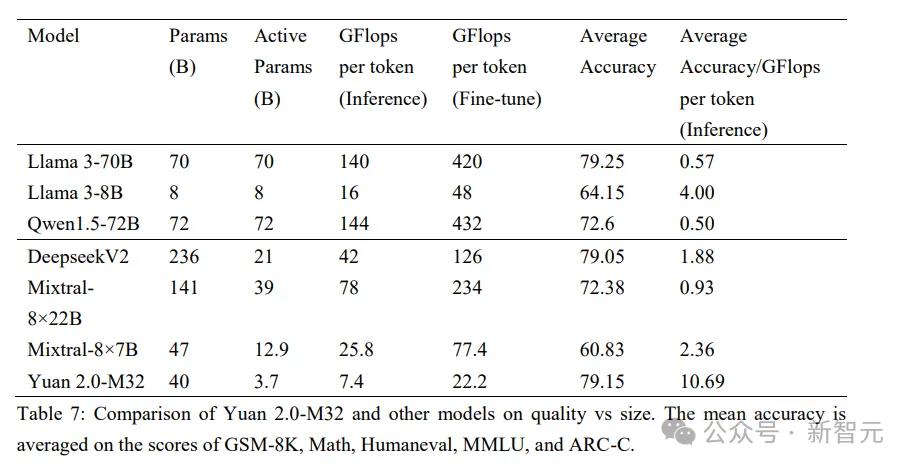
训练
在智能水平相当的情况下,源2.0-M32微调/训练时每token所需的算力资源最低——仅为22.2Gflops/token。
相比起Llama3-70B的420Gflops/token,源2.0-M32的需求只有其1/19。
推理
在相同条件下进行测试后可以发现,M32处理每token所需算力为7.4Gflops,而Llama3-70B所需算力为140Gflops。
也就是说,源2.0-M32的推理算力消耗也仅是Llama3-70B的1/19。
微调
在微调阶段,M32只需消耗约0.0026PD(PetaFlops-Day),就可以完成对1万条平均长度为1024token的样本进行全量微调,而Llama3则需消耗约0.05PD的算力。
更直观来讲,源2.0-M32在支持BF16精度的2颗CPU服务器上,约20小时即可完成这1万条样本的全量微调。
而同样条件之下的Llama3-70B,完成全量微调约为16天。
近50%训练数据都是代码
众所周知,丰富、全面、高质量的数据集,是LLM预训练核心。
这次,源2.0-M32使用了2万亿(2T)token进行训练。
且代码数据占比最高,几乎近一半(47.46%),而且从6类最流行的代码扩充至619类,并通过对代码中英文注释的翻译,将中文代码数据量增大至1800亿token,占比约8.0%。
此外,占比第二高的预料数据来自中英文互联网(25.18%),有效提升了模型的知识实时性与跨领域、跨语言应用效果。
之所以加入了如此之多的代码数据,是因为其本身就具有非常清晰的逻辑性。
当模型在海量的代码数据上完成「高强度」训练之后,不仅可以在代码生成、代码理解、代码推理上取得出色的表现,而且还能在逻辑推理、数据求解等方面获得可观的提升。
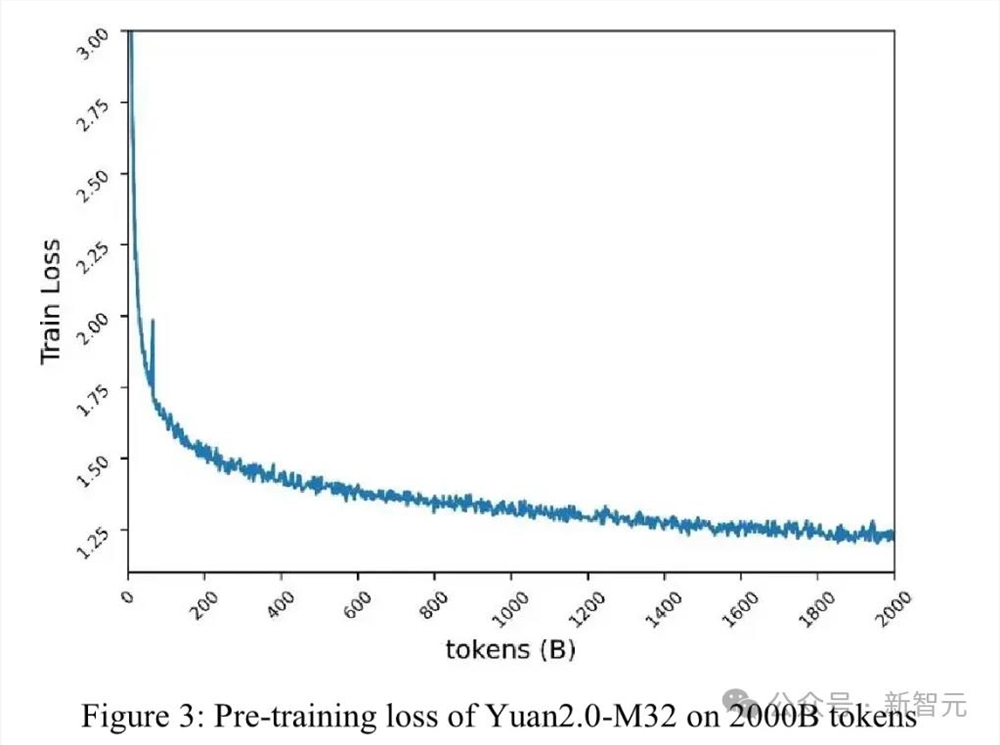
源2.0-M32的性能随着训练数据的增加而增强,且过程十分稳定
模更强,算更优,是终解!
可以看出,浪潮 信息的MoE模型,在榜单上基本上达到了Llama3的水平,甚至有些可以超越Llama3。
然而最大的不同,就是浪 潮信息显著降低了单个token在训练推理和微调过程中的算力消耗。
由此,大模型训练和应用过程中的门槛也随之降低,高智能水平的模型就能更顺利地普及到千行百业当中去。
浪 潮信息之所以选择攻坚这个问题,也是他们长期「深根沃土」,服务行业客户的深刻认知。
在浪 潮信息看来,如今大模型智能水平提升,但背后所面临的算力消耗,却大幅攀升!
对企业落地,是极大的困难和挑战。
由此,找到一种「模型水平高、算力门槛低」的技术方式就变得很重要。这也是我们在开头所想强调的「模算效率」。这个指标不仅是大模型创新的关键,也是企业真正应用大模型的关键。
为什么这么说?让我们来举个例子。
如果Llama3-70B的每个token推理是140GFlops,用这个实际精度除以每token的推理算力,就可以得到一个模型的算力效率。
结果显示,Llama3的模型精度很高,但推理时的算力开销将极大。这也就意味着,在单位算力下,它的相对精度是比较差的。
与之形成鲜明对比的,就是Mistral的8×7B模型。虽然它和Llama3有较大差距,但它激活专家的参数量较小,所以模算效率反而更高。
追求模算效率,因为它意义非常深远。
比如,一个5000亿的Dense模型,训练20T token的话,需要的算力开销是巨大的。因此,如果能获得很高的模算效率,我们就能在更多token上,训练更大参数的模型。
第二点,从推理上来说,模算效率也极有意义。企业类用户的推理都需要本地化部署,需要购买算力设备。
在这种情况下,给定精度水平下的推理回报就会显出差别。
比如Mistral8×22B和Llama3-70B,二者的精度差别虽然不大,但前者的模算效率就会很高,
此前,业内更加关注的是单个维度,即平均精度的提升。
而在大模型进入快速落地的当下,我们显然就需要从模算效率上来考虑精度和开销了。
此外,模算效率的提升也让LLM微调的门槛和成本大幅降低,这就能让高智能模型更加易于企业应用开发,实现智能落地。
尤其是考虑到现在,「微调」已成企业应用大模型的关键环节。
因为它能结合特定业务场景和专业数据对LLM完成优化,帮助LLM在专用场景中提高生成准确性、可解释性,改善「幻觉」问题。
一如既往,全面开源
坚持开源,也是浪 潮信息一直以来的传统。
2021年,这家公司便开始布局大模型算法开发,同年首次发布了2457亿参数的「源1.0」中文语言大模型,并全面开源,在业界树立了千亿模型的新标杆。
值得一提的是,「源1.0」的MFU高达44%,可见算力利用率非常高。
而当时GPT-3的MFU只有22%,也就是说有近80%的算力被浪费掉了。
彼时的浪 潮信息团队还开源近5TB的中文数据集,在国内100 个大模型厂商中,有近50个LLM的训练中得到应用。
之后,历时近2年研发,2023年,浪 潮信息将千亿参数基础大模型从1.0升级到「源2.0」。
「源2.0」包含了三种参数规模,1026亿、518亿、21亿,并在代码编程、逻辑推理、数学计算等领域展现出领先的性能。

论文地址:https://arxiv.org/ftp/arxiv/papers/2311/2311.15786.pdf
这一次,升级后的2.0版本同样采取了「全面开放开源」的策略,全系列模型的参数、代码,均可免费下载和商用。
「源2.0」也在不断进行版本更新,并针对代码能力、数理逻辑、推理速度等方面完成深度优化。
浪 潮信息还提供了丰富的预训练、微调以及推理服务脚本,并与流行框架工具全面适配,比如LangChain、LlamaIndex等。
正如前面所述,「源2.0-M32」 将继续采用全面开源策略,又将给开源社区添砖增瓦,留下浓墨重彩的一笔。
首席科学家吴韶华表示,「当前业界大模型在性能不断提升的同时,也面临着所消耗算力大幅攀升的问题,这也对企业在落地应用大模型时带来了极大的困难和挑战」。
降低应用门槛
除了全面开源之外,浪 潮信息还通过发布方便可用的工具,进一步降低了大模型应用的门槛。
今年4月,企业大模型开发平台「元脑企智」(EPAI)正式推出,为企业LLM训练提供了更加高效、易用、安全的端到端开发工具。
从数据准备、模型训练、知识检索、应用框架等系列工具全覆盖,且支持多元算力和多模算法。
EPAI提供了非常丰富的基础数据,规模达1亿 ,同时提供自动化的数据处理工具,帮助行业伙伴和企业客户整理行业数据和专业数据,减少针对不同落地场景中出现的「幻觉」。
对于企业来说,甚至是企业小白用户,EPAI可以帮助他们高效部署开发AI应用,能够释放极大的商业价值。
如今,源2.0-M32也将集成到EPAI大模型库,帮助企业加快AI应用落地的步伐。

在算力愈发紧俏的当下,浪 潮信息用「模更强 算更优」的M32交出了答卷,让整个业内为之振奋。
接下来,我们等待它的更多惊喜!
参考资料:
https://github.com/IEIT-Yuan/Yuan2.0-M32
https://huggingface.co/IEITYuan/Yuan2-M32-hf
https://modelscope.cn/models/YuanLLM/Yuan2-M32-hf/summary
完胜Win自带功能 文件复制神器FastCopy 5.0升级:SSD提速30%
快科技4月15日消息,CtrlC、CtrlV复制粘贴是电脑使用中最常见的操作之一,小文件可以用Win自带功能,大量数据拷贝的话自带功能就有些弱了,很多人都知道FastCopy这个神器,完胜Win自带复制功能。站长网2023-04-15 17:38:400003上线四个月“苹果版余额宝”用户存款已超过 100 亿美元
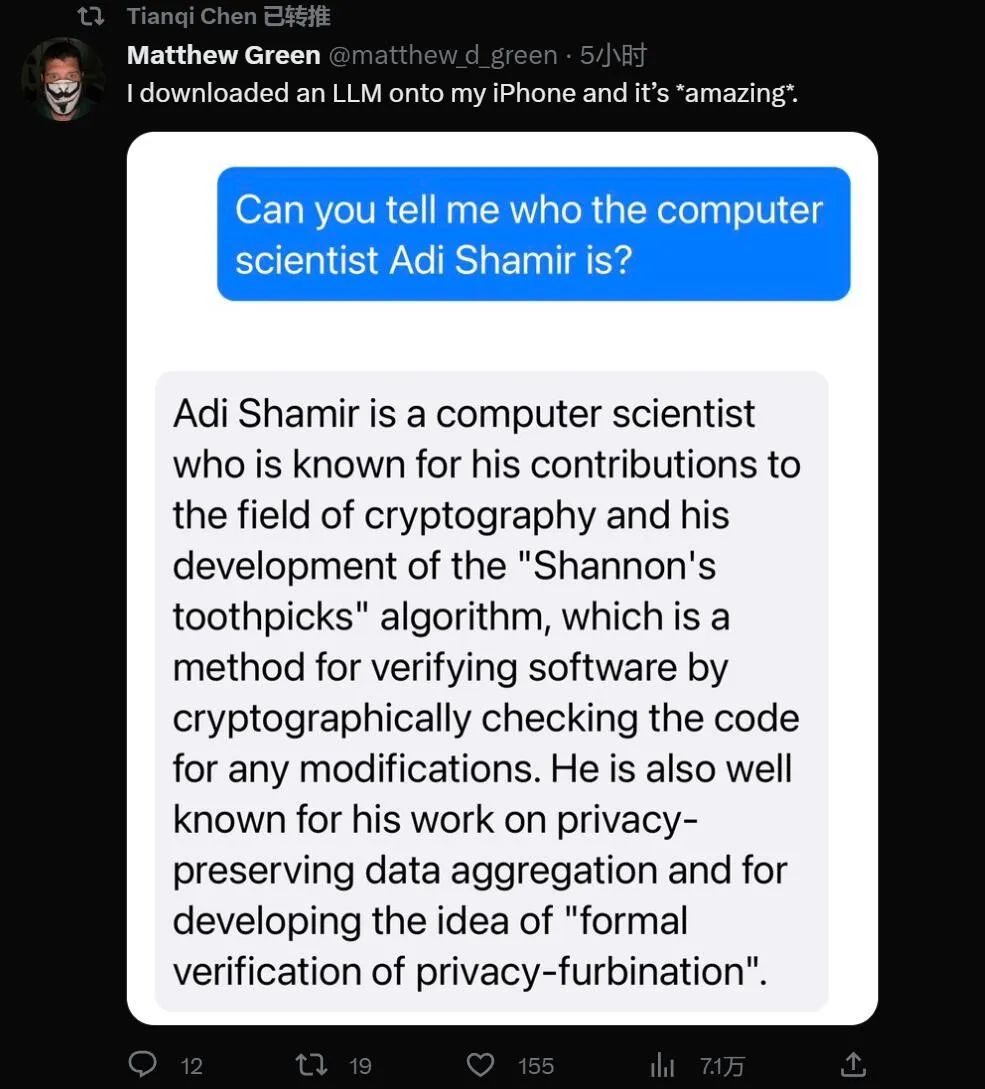
苹果今天宣布,高盛提供的AppleCard高收益储蓄账户自4月份推出以来,用户存款已超过100亿美元。储蓄账户的APY(年收益率)为4.15%。站长网2023-08-03 10:41:330000陈天奇等人新作引爆AI界:手机原生跑大模型,算力不是问题了
从此,大模型可以在任何设备上编译运行。「我把大语言模型下到我的iPhone上,它神奇地跑起来了!」五一假期还没过半,大模型领域的技术就已经发展到了这种程度。对于陈天奇等人开源的新技术,大家一致的评论是「Amazing」。站长网2023-05-02 15:32:260005FF:美国著名说唱歌手Chris Brown成为第五位FF19车主
据法拉第未来官方消息,全球巨星兼企业家克里斯布朗在过去一个月里,经过试驾和体验FF912.0FuturistAlliance后,正式成为了这款车的第五位车主。现在,克里斯布朗已身兼FF车主及开发者共创官两重身份,他已向FF提供了宝贵的反馈意见,这些意见不仅会进一步完善属于他的FF912.0,也会对提升FF的整体用户体验起到推动作用。站长网2023-11-06 16:00:250000解清帅20天狂涨300万粉丝,直播带货被吐槽,风评反转?
本文由运营公举小磊磊(公众号ID:gongjulei)原创关于我:全网近30W粉丝,只写干货,教你自媒体怎么做,快速起号赚钱。今年12月初,河北“千万富翁”解克锋的寻亲经历轰动全网。在25年的寻子漫漫征途后,他终于与失散的儿子解清帅在江西成功相见,一家人团聚的感人故事感动了千万网友。该事件在抖音等平台广泛传播,许多人祝福他及家人。短短20天,解清帅的抖音账号狂涨300万粉丝!站长网2023-12-25 17:31:480000