研究发现 52% 的 ChatGPT 编程问题回答错误
划重点:
- 研究人员发现,ChatGPT 生成的编程问题答案中有52% 是错误的。
- ChatGPT 的答案在语言上更正式和分析性更强,但存在信息不准确、冗长和与人类答案不一致的问题。
- 尽管存在严重缺陷,但许多人类程序员更偏好 ChatGPT 的答案。
在过去的几年里,计算机程序员纷纷转向诸如 OpenAI 的 ChatGPT 之类的聊天机器人来帮助他们编码,这对 Stack Overflow 等网站造成了打击,导致其去年不得不裁员近30% 的员工。然而,问题在于,普度大学的研究团队在计算机 - 人类交互会议上发布了研究成果,发现 ChatGPT 生成的编程问题答案中有52% 是错误的。

图源备注:图片由AI生成,图片授权服务商Midjourney
对于一个人们依赖于准确性和精确性的程序来说,这一比例是惊人的,这也突显出其他最终用户如作家和教师所经历的问题:像 ChatGPT 这样的 AI 平台经常在空中凭空产生完全错误的答案。研究人员在研究中回顾了517个 Stack Overflow 的问题,并分析了 ChatGPT 尝试回答这些问题的结果。他们写道:“我们发现52% 的 ChatGPT 答案包含错误信息,77% 的答案比人类答案更冗长,78% 的答案与人类答案存在不同程度的不一致”。
该团队还对随机选择的2000个 ChatGPT 答案进行了语言分析,发现这些答案 “更正式和分析性更强”,同时表现出 “更少的负面情绪” —— 这是 AI 倾向于产生的单调而愉快的语气。尤其令人担忧的是,许多人类程序员似乎更喜欢 ChatGPT 的答案。普度大学的研究人员对12名程序员进行了调查,并发现他们以35% 的比例更倾向于选择 ChatGPT,并且在39% 的情况下没有发现 AI 生成的错误。
为什么会发生这种情况呢?这可能只是因为 ChatGPT 比在线人更有礼貌。研究人员写道:“后续的半结构化访谈揭示出,礼貌的语言、文雅而教科书般的回答方式以及全面性是 ChatGPT 答案看起来更具说服力的主要原因之一,因此参与者放低了警惕,忽略了 ChatGPT 答案中的一些错误信息”。
这项研究表明,ChatGPT 仍然存在重大缺陷,但这对于被 Stack Overflow 裁员的人或者不得不纠正 AI 生成的代码错误的程序员来说是一个苦涩的安慰。
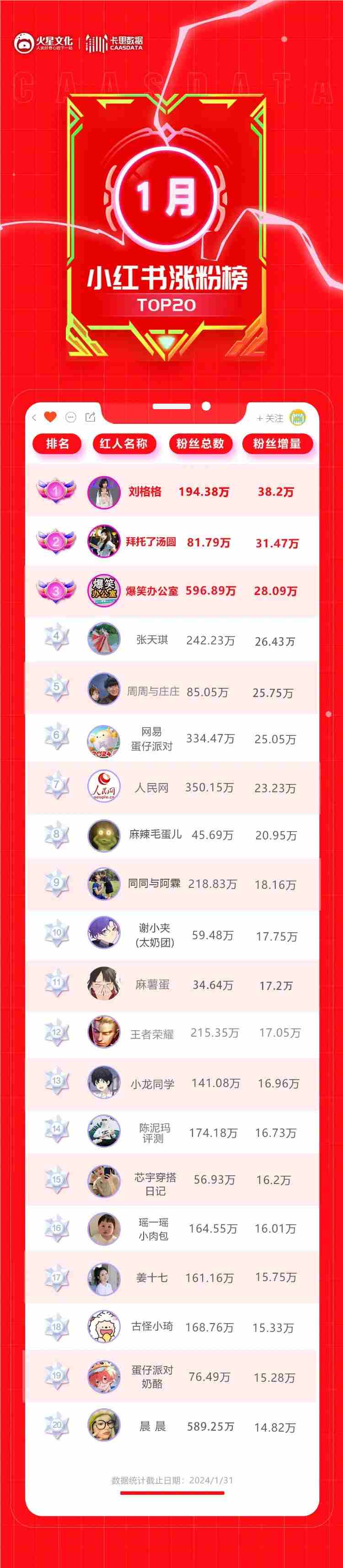
单月涨粉38万,她拿下小红书2024开门红
2024年开年之际,小红书内容生态呈现出了怎样的面貌?让我们一起在春节到来之前,围观下新鲜出炉的一月涨粉榜:本月排名第一的是萌娃账号@刘格格。该账号之所能在本月迅速涨粉,源于格格与剧情博主@晨晨的“网友奔现”。面对漂亮妹妹的热烈欢迎,张典兴奋又害羞的表情令人捧腹;格格撩起刘海cos臻臻后,张典的“痛心疾首”也颇具喜感。奇妙的化学反应下,@刘格格一月涨粉38.2万,在2024年迎来了开门红。站长网2024-02-06 16:22:200000董宇辉“自立门户”后,东方甄选发布了首份财报
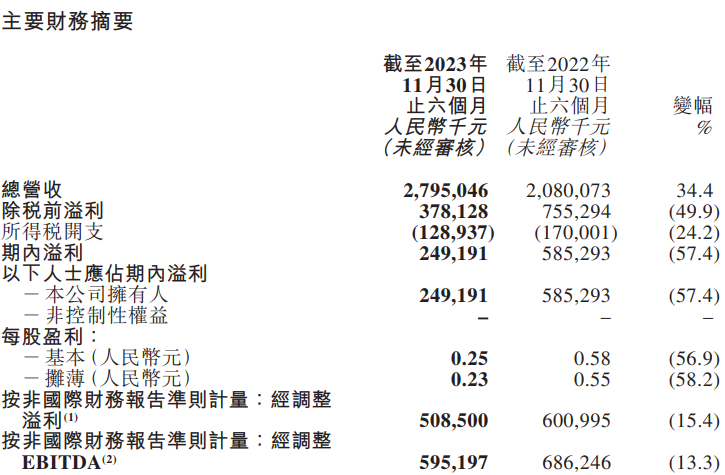
1月24日晚,东方甄选发布了2024财年中期(6月1日—11月30日)业绩财报。这是公司继董宇辉自立门户后,发布的首份财报,发布的时间距离“与辉同行”首播约2周时间。站长网2024-01-26 14:05:020000爆火的“追星神器”:一根赚1分钱,一年卖出5亿根
“一根荧光棒卖140块,简直是‘天价’。”看到五月天演唱会荧光棒爆卖的消息时,30多岁的徐彬苦笑着摇了摇头,“这个产品估计成本10元左右,更多的是IP授权等营销费用。”他经营着一家创办10多年的荧光棒企业——郑州全彩工艺品有限公司。站长网2023-06-08 11:22:430001年终盘点丨直播带货2023:主播、平台,谁才是超级IP?
2023年接近尾声,掀起直播带货行业年末最后一波高潮的东方甄选“小作文”事件也终于告一段落。董宇辉选择继续与东方甄选牵手,前者既守着了读书人的坚持,也成为了新东方教育科技集团董事长文化助理,兼任新东方文旅集团副总裁,后者股价涨幅扩大至20%,市值重回300亿港元,一场纷争最终由双赢的结果定音。站长网2023-12-19 17:16:020000腾讯云与《幻兽帕鲁》开发商 Pocketpair 达成合作
腾讯云与游戏《幻兽帕鲁》开发商Pocketpair达成合作,腾讯云成为该游戏的多人游戏专属服务器官方指定合作伙伴。《幻兽帕鲁》是一款火爆的游戏,玩家数量超过2500万人,Steam在线人数也屡次破纪录,导致官方服务器承载压力过大。因此,官方提供了自建服务器的教程,鼓励玩家自行搭建游戏服务器以改善游戏体验。站长网2024-03-26 10:52:270001