谷歌数学版Gemini破解奥赛难题,堪比人类数学家!
【新智元导读】I/O大会上,谷歌Gemini1.5Pro一系列更新让开发者们再次沸腾。最新技术报告中,最引人注目的一点是,数学专业版1.5Pro性能碾压GPT-4Turbo、Claude3Opus,成为全球最强的数学模型。
四个月的迭代,让Gemini1.5Pro成为了全球最强的LLM(几乎)。
谷歌I/O发布会上,劈柴宣布了Gemini1.5Pro一系列升级,包括支持更长上下文200k,超过35种语言。

与此同时,新成员Gemini1.5Flash推出,设计体积更小,运行更快,还支持100k上下文。

最近,Gemini1.5Pro最新版的技术报告新鲜出炉了。

论文地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
报告显示,升级后的模型Gemini1.5Pro,在所有关键基准测试中,都取得了显著进展。
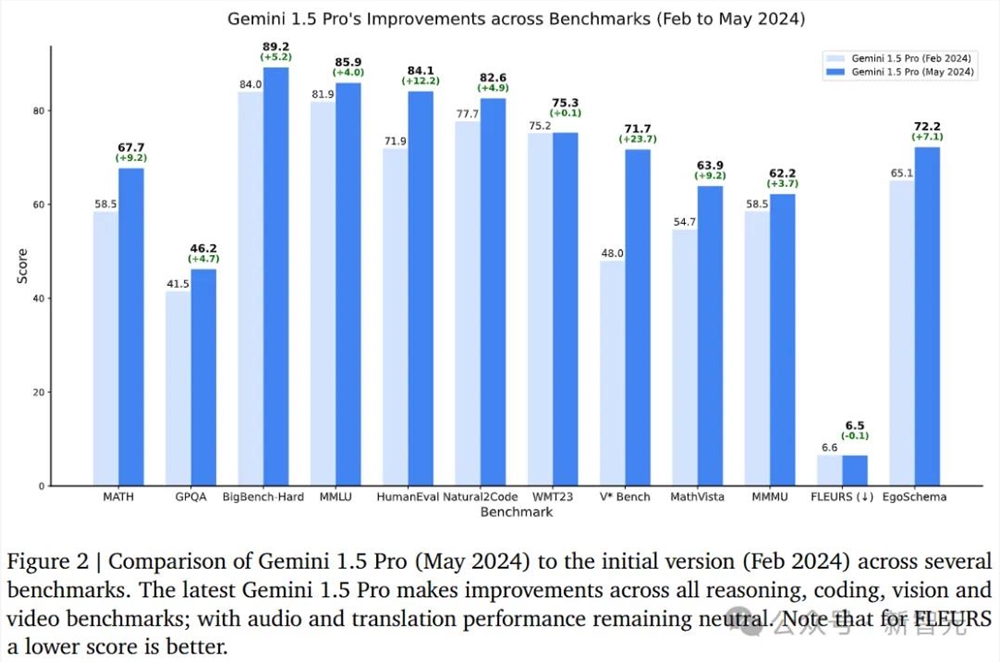
简单来说,1.5Pro的性能超越了「超大杯」1.0Ultra,而1.5Flash(最快的模型)性能则接近1.0Ultra。
甚至,新的Gemini1.5Pro和Gemini1.5Flash在大多数文本和视觉测试中,其性能还优于GPT-4Turbo。
Jeff Dean发文称,Gemini1.5Pro「数学定制版」在基准测试中,取得了破记录91.1%成绩。
而三年前的今天,SOTA仅为6.9%。

而且,数学专业版的Gemini1.5Pro在数学基准上的成绩,与人类专家的表现不相上下。

数学评测3年暴涨84.2%
对于这个「数学定制版」模型,团队使用了多个由数学竞赛衍生的基准测试评估Gemini的能力,包括MATH、AIME、Math Odyssey和团队内部开发的测试HidemMath、IMO-Bench等。
结果发现,在所有测试中,Gemini1.5Pro「数学定制版」都明显优于Claude3Opus和GPT-4Turbo,并且相比通用版本的1.5Pro有显著改进。
特别是MATH测试中取得了91.1%的突破性成绩,而且不需要使用任何定理证明库或者谷歌搜索等任何外部工具,这与人类专家的水平相当。
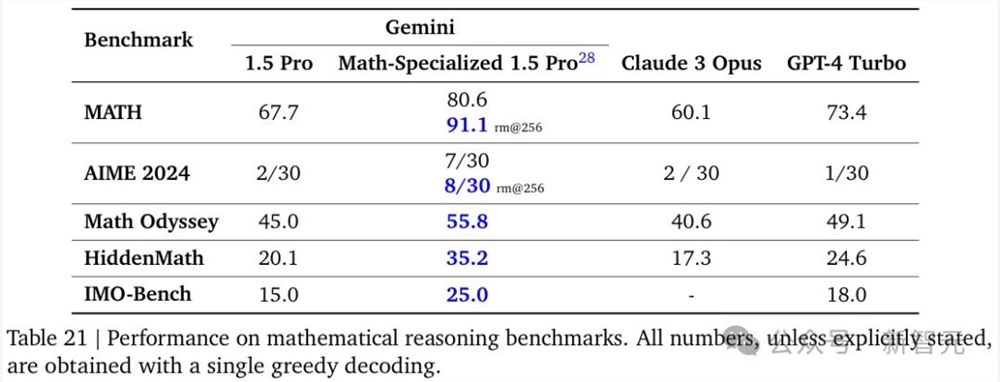
此外,在AIME测试集中,Gemini1.5Pro「数学定制版」能解决的问题数量是其他模型的4倍。
以下是两道曾让之前的模型束手无策的亚太数学奥林匹克竞赛(APMO)题。
其中,上面的这个例子很有代表性,因为它是一道证明题,而不是计算题。
对此,Gemini给出的解法不仅直切要害,而且非常「漂亮」。

Gemini1.5Pro核心性能全面提升
文本评估
除了数学之外,升级后的1.5Pro在推理、编码、多模态多项基准测试中,取得了显著的优势。
甚至就连主打输出速度的1.5Flash,在性能上也不输1.0Ultra。
尤其是,在MMLU通用语言理解基准测试中,Gemini1.5Pro在正常的5个样本设置中得分为85.9%,在多数投票设置中得分为91.7%,超过了GPT-4Turbo。

与2月出版技术报告对比来看,新升级1.5Pro在代码两项基准中,有了非常明显的提升,从71.9%上涨到84.1%(HumanEval),从77.7%上涨到82.6%(Natural2Code)。
在多语种基准测试中,新升级1.5Pro的能力略微下降。
此外,5月报告中,将数学和推理能力分开评测,在数学基准上,新升级1.5Pro有所下降,从91.7%下降到90.8%。
在推理测试中,MMLU上的性能从81.9%提升到85.9%。

2月版
针对函数调用,1.5Pro在多项任务中,除了多项函数,都拿下了最高分。1.5Flash在多项函数任务中,取得了领先优势。

在指令调优上,1.5Pro面对更长指令1326提示时,回应准确率最高。而406更短指令,1.0Ultra的表现更优秀。

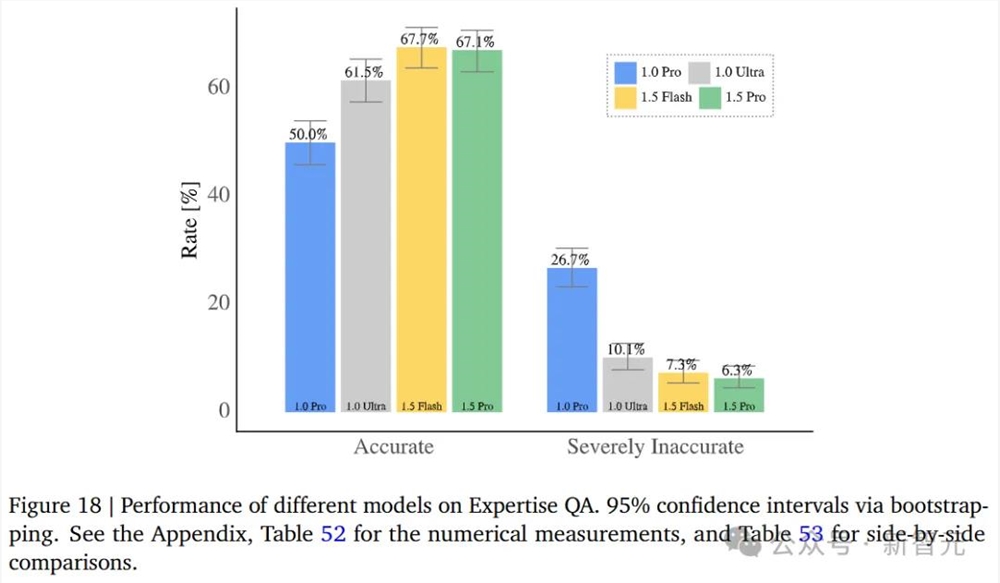
涉及到更专业的知识问答时,1.5Pro准确率几乎与1.5Flah持平,仅差0.6%,但都显著优于1.0Pro和1.0Ultra。
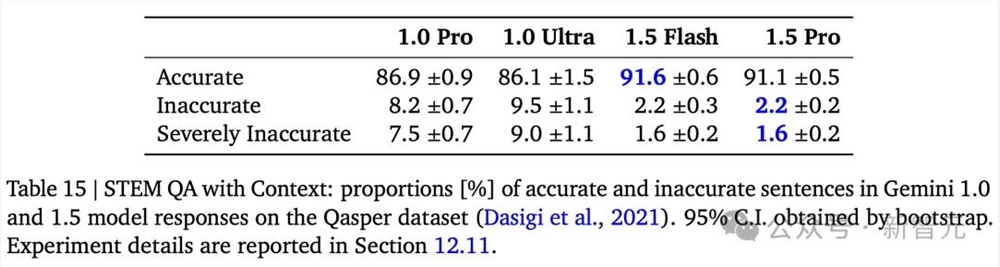
针对STEM上下文问答任务中,在Qasper数据集上,Gemini1.0和1.5准确率提升,与此同时不准确率显著下降。
再来看偏好结果,针对不同提示,与1.0Pro比起来,1.5Pro和1.5Flash相对得分更高。

多模态评估
针对多模态性能,技术报告中涉及了众多基准测试,包括多模态推理、图表与文档、自然图像以及视频理解四个方面,共15个图像理解任务以及6个视频理解任务。
总体来看,除了一项测试之外,1.5Pro的表现均能超过或者与1.0Ultra相当,且轻量的1.5Flash在几乎所有测试中都超过了1.0Pro。

可以看到1.5Pro在多模态推理的4个基准测试上都有所提高。
在公认较为困难的MMMU测试中,1.5Pro实现了从47.9%到62.2%的提升,在研究生水平的Ai2D测试上甚至达到了94.4%,1.5Flash也有91.7%的高分。
对于多模态大模型,图表和文档的理解比较有挑战性,因为需要对图像信息进行准确的解析和推理。
Gemini1.5Pro在ChartQA取得了87.2%的SOTA结果。
在TAT-DQA测试上,分数从1.0Pro的9.9%升至37.8%,1.5Flash相比1.0Ultra也有将近10%的提高。
此外,团队创建了BetterQA等9个互不相交的能力测试。结果显示,相比上一代的1.0Pro,1.5Pro总体达到了20%以上的提升。
自然图像理解方面的测试,重点关注模型的对物理世界的理解以及空间推理能力。
在专门的V*测试中,1.5Pro和测试提出者所发表的模型SEAL几乎表现相当。
在人类擅长而模型不擅长的Blink测试中,1.5Pro实现了从45.1%(1.0Pro)到61.4%的提升,Flash分数相近(56.5%),依旧高于1.0Ultra(51.7%)。
除了「大海捞针」,团队也为Gemini1.5Pro进行了其他视频理解方面的基准测试,但提升不如前三个方面那样显著。
在VATEX英文和中文的两个测试中,对比2月份发布的Gemini1.5Pro的技术报告,三个月训练后的提升不超过2分。
在YouCook2测试中,1.5Pro似乎始终不能达到1.0Ultra的135.4分,而且相比2月技术报告中的134.2下降到了最新的106.5。
有趣的是,在OpenEQA的零样本测试上,1.5Flash得分63.1,甚至超过了1.5Pro的57.9。技术报告中解释,这是由于1.5Pro拒绝回答某些问题造成的。


2月版
对比GPT-4、Claude3优势明显
接下来,再看看横向对比,新升级的1.5Pro与GPT-4、Claude模型相较下的性能如何。
模型诊断能力改进
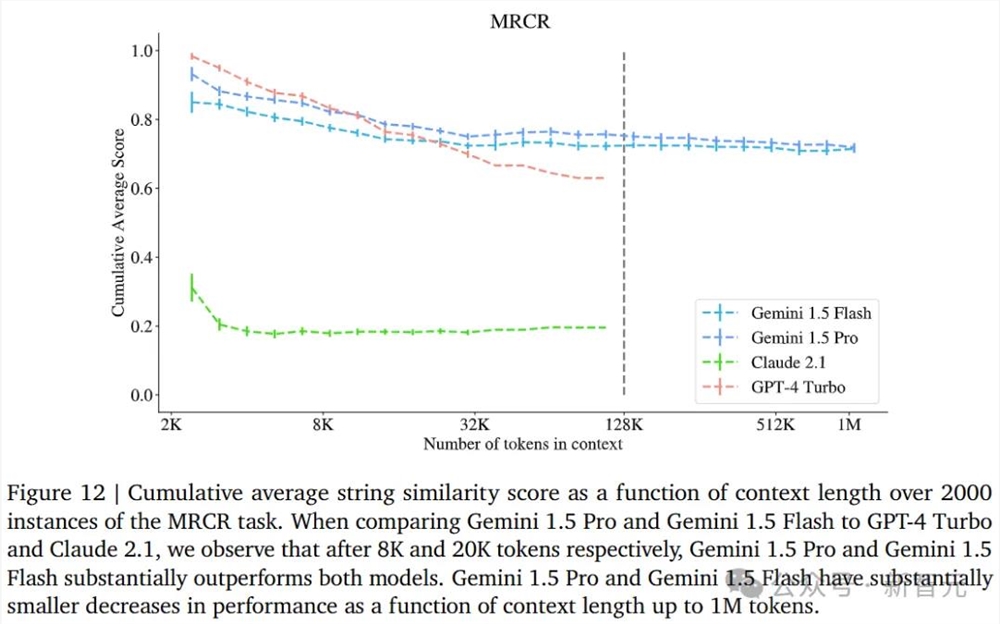
如下展示的是,在2000个MRCR任务实例中,字符串相似度累积平均得分与上下文长度的函数关系。
在与GPT-4Turbo和Claude2.1进行比较时,研究人员发现分别在8K和20K个词组之后,1.5Pro和1.5Flash的性能大大优于这两个模型。
随着上下文长度的增加,1.5Pro和1.5Flash的性能下降幅度大大缩小,最高可达100万个token。
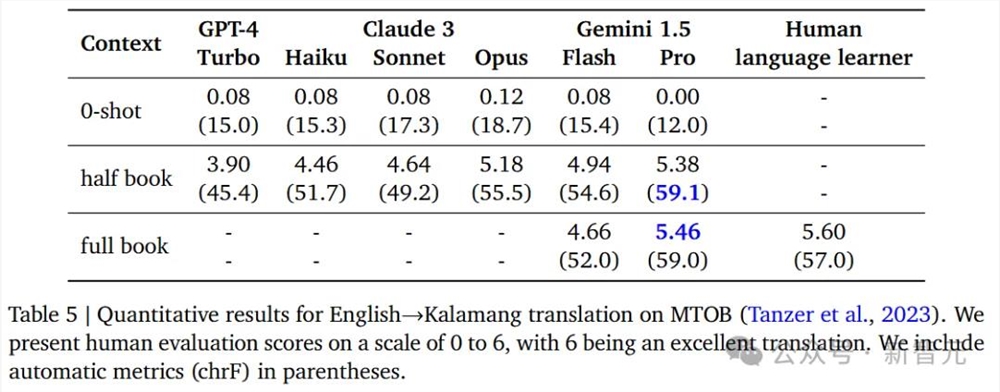
在将小语种Kalamang翻译成英语的量化结果如下所示。
新升级的1.5Pro在喂了半本书,甚至全本书的数据之后,性能得到大幅提升,并优于GPT-4Turbo和Claude3的表现。

而在将英语翻译成Kalamang语言的量化结果中,1.5Pro的胜率也是最高的。
低资源机器翻译的长上下文扩展
再来看,在「低资源」机器翻译中,模型的上下文学习扩展(Scaling)表现。
随着样本数量不断增加,1.5Pro的翻译性能越来越好,大幅超越了GPT-4Turbo。

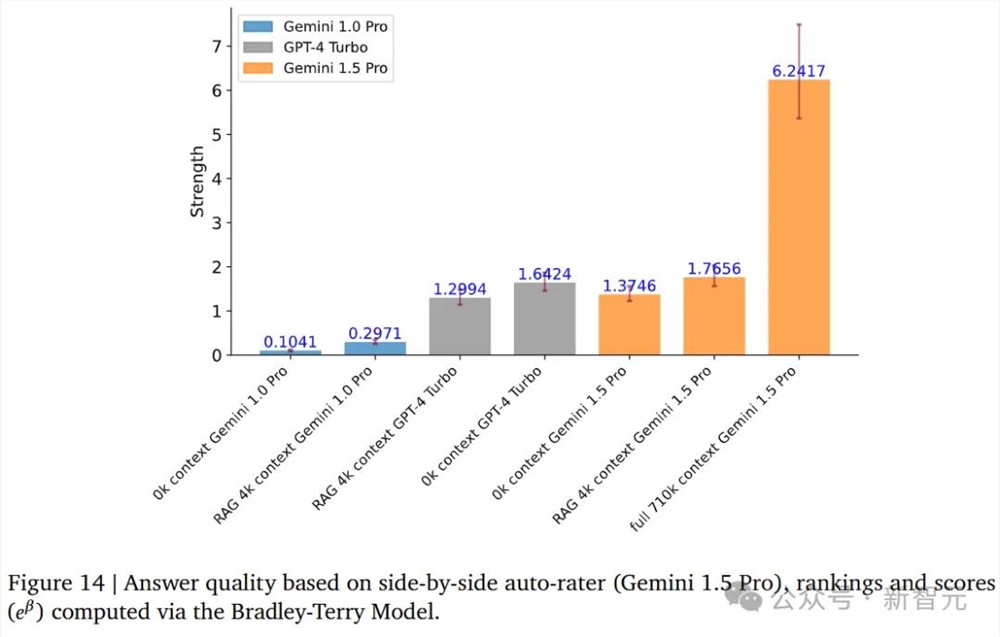
长上下文文本QA
针对长文本的问答,1.5Pro在710k上下文文中,表现显著优于GPT-4Turbo。并且,超越了没有上下文,以及在RAG加持下,支持4k上下文的1.5Pro。
长上下文音频
在音频长上下文的测试中,每个模型的单词错误率表现又如何?
可以看到,1.5Pro仅有5.5%,而OpenAI的Whisper模型的错误率高达12.5%。
但与2月版的报告相比,1.5Pro的音频长下文单词错误率还是有所下降。
2月版
长上下文视频QA
针对1个小时的视频问答任务,1.5Pro在不同基准上准确率实现与3分钟视频任务准确率,基本持平一致。
再来看去年2月版的对比,1.5Pro在1小时任务中的准确率有了很大提升,从最高0.643上涨到0.722。还有在3分钟视频QA任务中,从0.636上涨到0.727。
2月版
在1H-VideoQA测试中,团队在时长1小时的视频中每秒取1帧画面,最终线性下采样至16帧或150帧,分别输入给GPT-4V与Gemini1.5进行问答。
无论帧数多少,Gemini1.5Pro的表现均强于GPT-4V,其中在16帧测试的优势最为明显(36.5% vs.45.2%)。
在观看整个视频后进行回答时,Gemini1.5Pro从2月的64.3%提升至72.2%。
2月版
长上下文规划
「推理」和「规划」技能对解决问题都很重要,虽然LLM在推理上进展显著,但规划依旧很难。
这篇报告专门呈现了Gemini1.5的规划能力测试,涉及到移动积木、安排物流路线、室内导航、规划日程和旅行路线等任务场景。
测试中,模型必须根据给定任务,一次性地快速生成解决方案,类似于人类的「头脑风暴」过程。
总体上,Gemini1.5Pro在绝大多数情况下的表现优于GPT4Turbo,不仅能在少样本时较好进行规划,还能更有效地利用额外的上下文信息。
更轻量的Gemini1.5Flash表现始终不敌Gemini1.5Pro,但在几乎一半的情况下可以与GPT-4Turbo的表现相当。
GPT-4Turbo的在BlocksWorld中的零样本表现接近于零,而Gemini1.5Pro和Flash分别达到了35%和26%。
Calendar Scheduling也是如此,GPT的1-shot准确率低于10%,而1.5Pro达到33%。
随着样本数量逐渐增多,1.5Pro的表现基本持续提升,但GPT-4Turbo在样本增加到一定程度时会出现下降趋势,在Logistics中甚至持续下降。
比如Calendar Scheduling中,当样本数量逐渐增加至80-shot时,GPT-4Turbo和1.5Flash只有38%的准确率,比Gemini1.5Pro低了32%。
之后增加至400-shot时,1.5Pro达到了77%的准确率,GPT却依旧徘徊在50%左右。
非结构化多模态数据分析任务
现实世界中的大多数数据,比如图像和对话,仍然是非结构化的。
研究人员向LLM展示了一组1024张图像,目的是将图像中包含的信息提取到结构化数据表中。
图17展示了从图像中提取不同类型信息的准确性结果。
Gemini1.5Pro在所有属性提取上的准确性提高了9%(绝对值)。同时,相较于GPT-4Turbo,1.5Pro提升了27%。
然而,在评估时,Claude3API无法分析超过20张图像,因此Claude3Opus的结果被限制了。
此外,结果显示,1.5Pro在处理更多的图像时会带来持续更好的结果。这表明该模型可以有效利用额外和更长的上下文。
而对于GPT-4Turbo来说,随着提供的图像增多,其准确性反而下降
更多细节参见最新技术报告。
参考资料:
https://the-decoder.com/gemini-1-5-pro-is-now-the-most-capable-llm-on-the-market-according-to-googles-benchmarks/
苹果今年下半年及明年年初有望推出超过15款新品
6月27日消息,据外媒报道,在本月6日凌晨的全球开发者大会上推出15英寸MacBookAir、MacStudio、MacPro、VisionPro之后,外界对苹果的关注重点,就将转向秋季将推出的iPhone15、AppleWatchSeries9等新品上。而从外媒最新的报道来看,苹果目前在研发多款新品,今年下半年和明年年初,他们有望推出超过15款新品。0000苹果发布 iOS 15.7.5.、macOS 11.7.6 和 macOS 12.6.5 安全更新
苹果公司今天推送了新的iOS15.7.5.macOSBIGSur11.7.6和macOSMonterey12.6.5更新,新软件为那些运行旧版Mac、iPad和iPhone的用户引入了安全改进,这些软件无法更新到iOS16.iPadOS16和macOSVentura。站长网2023-04-12 12:38:4100002024过半,AI卷到哪儿了?
AI创业者陈冉,发现行业里有一些“怪现象”。很多客户向他反馈,自己很困惑。一方面,大模型更新速度太快,搞不清楚到底哪个好用;同时,自己也不知道大模型怎么跟业务结合;另外,自己的数据集究竟能不能精调出一个好用的大模型,心里也没谱。最后的结果就是,愿意投入大模型,但不知如何下手,即便下定决心了,也抠抠搜搜拿不出太多预算来。0000雷军:小米15 Ultra、SU7 Ultra是小米创业十五年来最高端产品
站长之家(ChinaZ.com)2月24日消息:小米公司今日正式宣布,小米15Ultra与SU7Ultra发布会将于2月27日晚7点举行。这一消息由小米创始人雷军亲自揭晓,他透露,这两款新品代表了小米创业十五年以来最顶尖的技术与设计水平。0000报告:生成式AI将帮助 60% 的亚洲顶尖企业提高员工保留率
一份新报告显示,到2025年,大约60%的亚洲顶级公司将升级硬件和软件技术,通过个性化工作体验和加强协作来提高员工保留率生成式人工智能作为组织进步的游戏规则改变者而出现,在三个关键领域编织了个无缝的挂毯:智能文档处理(IDP)、生成自动化和知识共享。站长网2024-01-16 16:56:550000










