图灵巨头现身ICLR,顶会现场疯狂追星LeCun、Bengio!中国团队三大技术趋势引爆AGI新想象
【新智元导读】这几天的维也纳,上演了一场AI圈的狂欢。在ICLR2024上,图灵巨头LeCun、Bengio纷纷现身,直接让现场挤爆,变成追星现场。
这几天,AI届的盛会——ICLR在维也纳举办。
OpenAI、Meta、谷歌、智谱AI等世界前沿AI科技企业齐聚一堂。
现场名流云集,星光耀眼,走几步就能偶遇一位发过颠覆性paper的大咖。
毫无意外地,ICLR2024展厅也变成了追星现场。热闹的气氛,快把屋顶掀翻了。
图灵三巨头中的著名「e人」LeCun,提前就在X上大方公布出自己的行程,满怀期待地等着和粉丝们相见了。

在评论区,不仅有粉丝激动打卡,甚至还有准备现场递简历的。
粉丝们果然不虚此行,在现场,LeCun口若悬河地讲解,热情的观众们在周围形成密实的包围圈。
言归正传,在整个ICLR活动上,Meta团队将分享25余篇论文和两个研讨会。这次,LeCun团队在ICLR上发表了以下两篇论文。

论文地址:https://arxiv.org/abs/2305.19523

论文地址:https://arxiv.org/abs/2311.12983
另一位图灵巨头Yoshua Bengio,也显示了自己的超高人气。
现场观众总结道:「一个人真的需要在他的领域中做到独一无二,才能让他的会议室外排起如此长的队伍!」

此前LeCun和Hinton都对此发表过言辞激烈的意见,Bengio的态度似乎一直比较模糊,迫不及待想知道他对于AGI是什么看法了。在即将到来的5月11日,他就会在一场关于AGI的Workshop中发表演讲。
值得一提的是,Bengio团队也在今年的ICLR上获得了杰出论文荣誉提名。


论文地址:https://openreview.net/pdf?id=Ouj6p4ca60
谷歌Meta隔壁,智谱AI也在
现场,谷歌开源模型Gema、机器人智能体背后框架Robotics Transformers,以及其他开创性的研究一并呈现。
紧挨着Meta和谷歌,展厅中间有一家非常亮眼的公司——智谱AI。
现场的童鞋正为大家介绍GLM-4、ChatGLM等一系列研究成果。
这一系列展示,引起了众多国外学者的围观。
现场的近两千名与会嘉宾和学者,认真听了GLM大模型技术团队的介绍。
介绍内容包括了GLM系列大模型的多项前沿研究成果,涵盖数学、文生图、图像理解、视觉UI理解、Agent智能体等领域。
在现场,大家热烈讨论起了对Scaling Law的看法。而GLM团队,对此也有独到见解——
「相比模型大小或训练计算量,智能涌现和预训练损失有更加紧密的联系。」
比如,著名的OpenAI996研究员Jason Wei,认真读过智谱AI这篇讲预训练损失的论文后,表示十分赞叹。

论文中,团队通过训练30 个不同参数和数据规模LLM,评估了其在12个中英文数据集上的表现。

论文地址:https://arxiv.org/abs/2403.15796
结果观察到,只有当预训练损失低于某个阈值时,LLM会出现涌现能力。
而且,从预训练损失的角度定义「涌现能力」,效果优于仅依赖模型参数或训练量。

智谱AI的此番表现,也让越来越多外国网友意识到——
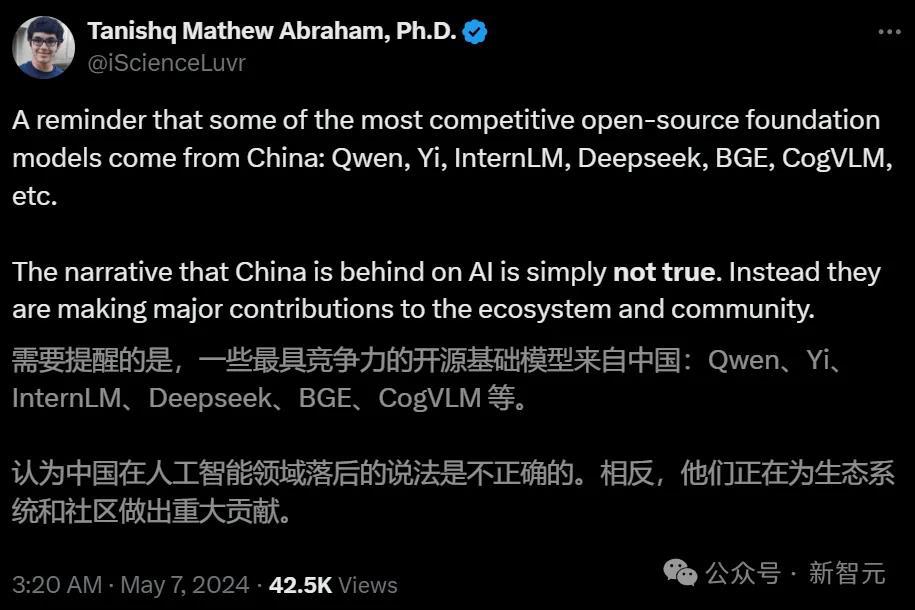
19岁获得博士的Stability AI研究主任Tanishq表示,CogVLM这类最有竞争力、为开源生态做出重大贡献的开源基础模型,就是来自中国。
这位游戏工作室的前CEO,去年就开始用CogVLM和Stable Diffusion做完整的开源版本了。

是的,自CogVLM自发布之后,其强大的能力便引起了外国网友的惊呼。


在今年1月的LLM排行榜中,也有人发现——
当时Gemini和GPT-4V远远领先于任何开源LLM,唯一一个例外,就是CogVLM。

可见,这波国产大模型出海,智谱AI已经闷声不响地在国外建立了自己的巨大影响力。
特邀演讲
展厅精彩演示之外,今年的ICLR,共邀请了七位特邀演讲嘉宾,分享他们对AI的见解。
有来自谷歌DeepMind的研究科学家Raia Hadsell,佐治亚理工学院副教授&FAIR首席科学家Devi Parik,有来自马克斯·普朗克计算机科学研究所(MPI-SWS)的主任Moritz Hardt,唯一一家中国团队是智谱AI 的GLM 大模型技术团队。
Raia Hadsell
谷歌DeepMind科学家Raia Hadsell的演讲题目是——「在人工智能发展的起伏过程中学习:通向AGI道路上的意外真理」。

经过数十年的稳定发展和偶尔的挫折后,AI正处在一个关键的拐点。
AI产品已经爆炸式地进入主流市场,我们还未触及到scaling红利的天花板,因此整个社区都在探讨下一步的方向。
在这次的演讲中,基于20多年在AI领域的经验,Raia探讨了我们对AGI发展之路的假设,如何随时间发展而变化。
与此同时,她还揭示了,在这个探索的过程中,我们得到的意外发现。
从强化学习到分布式架构,再到神经网络,已经在科学领域发挥着潜在的革命性作用。
Raia认为,通过汲取过去的经验教训,可以为AI未来的研究方向提供重要的洞见。
Devi Parikh
另一边,FAIR首席科学家Devi Parik给所有人讲述了,自己生活中的故事。

从演讲题目可见略知,Parik的分享内容,非比寻常。
在ICLR大会上,在解释为什么技术环境是现在这个样子时,大家会重点针对互联网、大数据和算力的发展,展开讨论。
然鹅,鲜有人关注那些微小,但重要的个人故事。
其实,每个人的故事,都可以汇聚成为推动技术进步的重要力量。
通过这种方式,我们可以彼此学习,相互激励。这让我们在追求目标时,更加坚韧和高效。
Moritz Hardt
德国MPI-SWS主任Moritz Hardt带来了「新兴的科学基准」的演讲。

显然,基准测试成为机器学习领域的「核心支柱」。
自20世纪80年代以来,虽然人类在这个研究范式下取得了诸多成就,但对其深层次的理解仍然有限。
在此次演讲中,Hardt通过一系列选定的实证研究和理论分析,探索基准测试作为一门新兴科学的基本原理。
他具体讨论了标注错误对数据质量的影响、模型排名的外部验证性,以及多任务基准测试的前景。
与此同时,Hard还展示了许多案例研究。
这些挑战了我们的传统看法,还突显了发展科学基准测试的重要性和益处。
GLM Team
中国这边,智谱AI的GLM大模型技术团队,也带来了「ChatGLM通往AGI之路」的精彩演讲。
值得一提的是,这也是国内「首次」在国际顶级会议上展示大模型相关的主题演讲。

这次演讲,首先从中国的角度,介绍AI在过去几十年的发展历程。
同时,他们以ChatGLM为例,阐述自身在实践过程中获得的理解和洞见。
2024AGI前瞻:GLM4.5、 GLM-OS、 GLM-zero
在ICLR上,GLM大模型团队介绍了面向AGI的GLM三大技术趋势。
通往AGI的必经之路在哪里?
业界对此意见不一。有人认为是智能体,有人认为是多模态,有人说,Scaling Law是通往AGI的必要非充分条件。
而LeCun坚持认为,LLM是通往AGI的一条歧路,靠LLM带不来AGI。
对此,团队也提出了自己的独特观点。

首先,他们讲到了GLM-4的后续升级版本,即GLM-4.5及其升级模型。
GLM-4的后续升级版,将基于超级认知(SuperIntelligence)和超级对齐(SuperAlignment)技术,同时在原生多模态领域和AI安全领域有长足进步。
GLM大模型团队认为,在通往AGI的路上,文本是最关键的基础。
而下一步,则应该把文本、图像、视频、音频等多种模态混合在一起训练,变成一个真正的「原生多模态模型」。
同时,为了解决更加复杂的问题,他们还引入了GLM-OS概念,即以大模型为中心的通用计算系统。
这一观点,与Karpathy此前提出的大模型操作系统的观点,不谋而合。
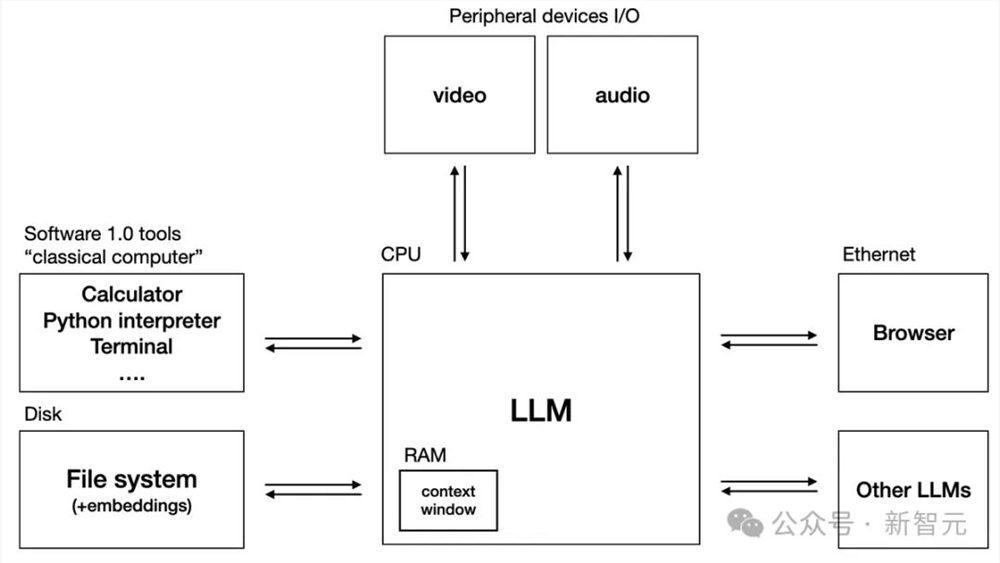
在ICLR现场,GLM大模型团队详细介绍了GLM-OS的实现方式:
基于已有的All-Tools能力,再加上内存记忆(memory)和自我反馈(self-reflection)能力,GLM-OS有望成功模仿人类的PDCA机制,即Plan-Do-Check-Act循环。
具体来说就是,首先做出计划,然后试一试形成反馈,调整规划然后再行动以期达到更好的效果。
依靠PDCA循环机制,LLM便可以自我反馈和自主进化——恰如人类自己所做的一样。
此外,GLM大模型团队还透露,自2019年以来,团队就一直在研究名为GLM-zero的技术,旨在研究人类的「无意识」学习机制。
「当人在睡觉的时候,大脑依然在无意识地学习。」
GLM大模型团队表示,「无意识」学习机制是人类认知能力的重要组成部分,包括自我学习、自我反思和自我批评。
人脑中存在着「反馈」和「决策」两个系统,分别对应着LLM大模型和内存记忆两部分。
因此,GLM-zero的相关研究将进一步拓展人类对意识、知识、学习行为的理解。
尽管还处于非常早期的研究阶段,但GLM-zero可以视为通向AGI的必经之路。
而这,也是GLM大模型团队首次向外界公开这一技术趋势。
国内顶流技术团队
2020年底,GLM大模型技术团队研发了GLM预训练架构。
2021年训练完成百亿参数模型GLM-10B,同年利用MoE架构成功训练出收敛的万亿稀疏模型。
2022年还合作研发了中英双语千亿级超大规模预训练模型GLM-130B并开源。
而过去一年里,团队几乎每3-4个月,就完成一次基座大模型的升级,目前已经更新到了GLM-4版本。
不仅如此,作为国内最早入局LLM公司,智谱AI曾在2023年就设立了一个雄心勃勃的目标——全线对标OpenAI。
GLM大模型技术团队构建了基于AGI愿景的完整大模型产品矩阵。
在GLM系列之外,还有CogView文生图模型、CodeGeeX代码模型,多模态理解模型CogVLM,再到GLM-4V多模态大模型和All-Tools功能以及AI助手智谱清言。

与此同时,GLM大模型技术团队的研究人员,在业界有着极高的影响力。
比如,圈里爆火的李飞飞主讲斯坦福大学CS25课程,每次都会邀请Transformer研究前沿的专家,分享自己的最新突破。
而目前已经确定,CS25课程的嘉宾中,就有来自智谱AI的研究员。

CogVLM
团队开发的开源视觉语言模型CogVLM,一经发布就引发了业界关注。
3月Stability AI公布的一篇论文就显示,因性能太出色,CogVLM直接被Stable Diffufion3拿来做图像标注了。

论文地址:https://arxiv.org/abs/2403.03206

CogAgent
在此基础之上,基于CogVLM改进的开源视觉语言模型CogAgent,主要针对的是用户图形界面GUI的理解。
而CogAgent的相关论文,已经被国际计算机视觉领域级别最高的学术会议CVPR2024收录。
要知道,CVPR以录取严格著称,今年论文录取率只有约2.8%。
论文地址:https://arxiv.org/abs/2312.08914
ChatGLM-Math
针对LLM解决数学问题,GLM大模型团队提出了「Self-Critique」的迭代训练方法。
即通过自我反馈机制,帮助LLM同时提升语言和数学的能力。

论文地址:https://arxiv.org/abs/2404.02893
这一方法,包含了两个关键步骤:
首先训练一个从LLM本身生成「Math-Critique」模型,以评估模型生成数学问题答案,并提供反馈信号。
其次,通过拒绝采样微调和DPO,利用新模型对LLM自身的生成进行监督。

GLM大模型团队还设计了MATHUSEREVAL基准测试集,以评估新模型数学能力,结果如下:
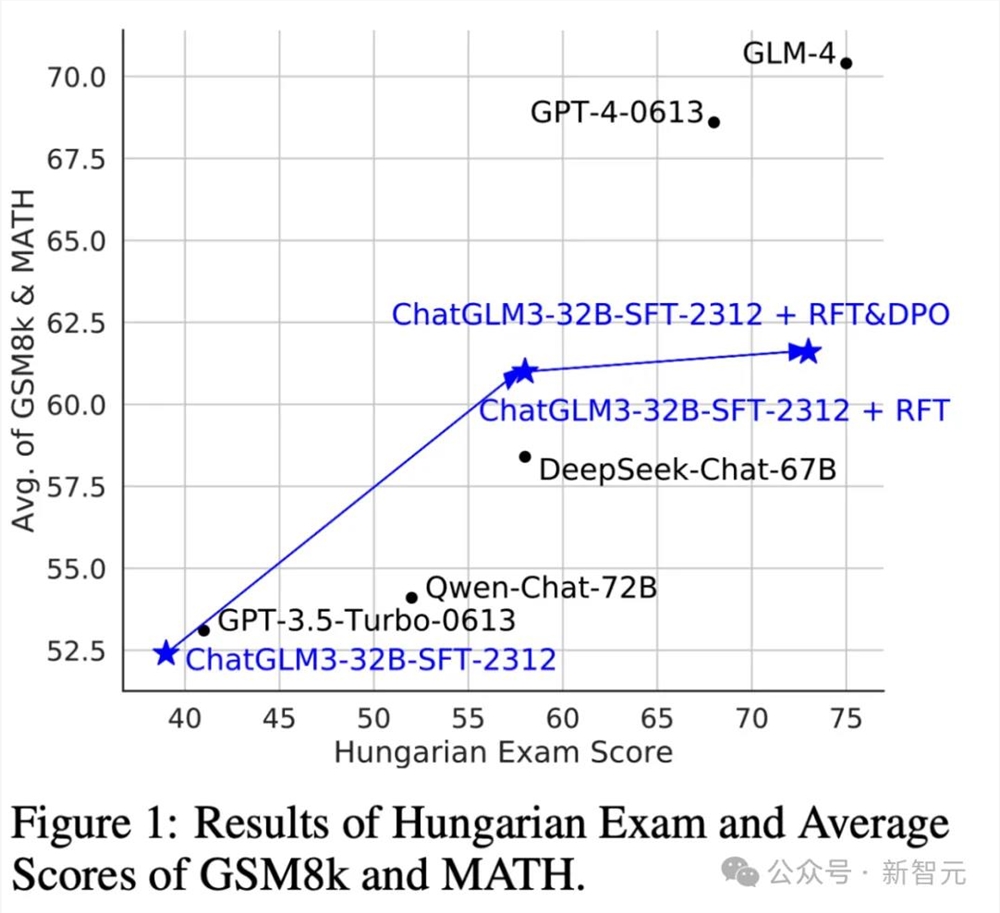
显而易见,新方法显著提升了LLM的数学问题解决能力,同时仍能提升其语言能力。重要的是,它在某些情况下优于参数量增加两倍的大模型。
GLM-4跻身全球第一梯队
在OpenCompass2.0基准测试中,智谱AI新一代基座大模型的实力不容小觑。
在总榜排名中,GLM-4位列第三,位居国内榜首。
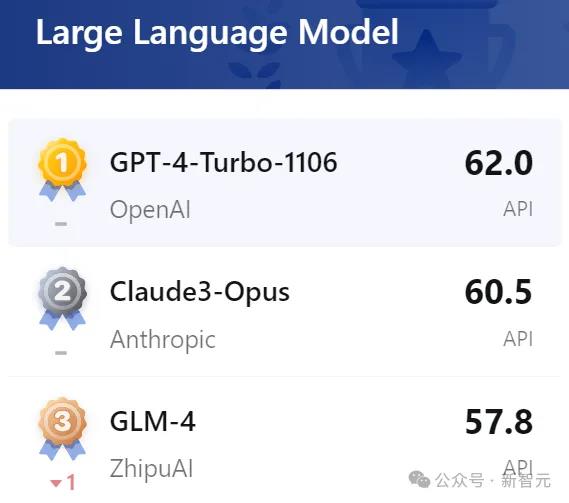
在不久前SuperBench团队发布的《SuperBench大模型综合能力评测报告》中,GLM-4也跻身全球第一梯队。
特别是在最关键的语义理解,智能体能力上,GLM-4更是国内第一,力压一众竞争对手。

刚刚过去的大模型元年,热闹非凡的百模大战打了一年。
2024年,若想化身为AGI元年,全世界大模型团队还有很长的路要走。
参考资料:
https://iclr.cc/virtual/2024/invited-talk/21802
GitHub热榜登顶:开源版GPT-4代码解释器,可安装任意Python库,本地终端运行
ChatGPT的代码解释器,用自己的电脑也能运行了。刚刚有位大神在GitHub上发布了本地版的代码解释器,很快就凭借3k星标并登顶GitHub热榜。不仅GPT-4本来有的功能它都有,关键是还可以联网。ChatGPT“断网”的消息传出后引起了一片哗然,而且一关就是几个月。这几个月间联网功能一直杳无音讯,现在可算是有解决的办法了。站长网2023-09-06 17:47:470000IP流量化的时代,迪士尼如何继续做百年老店
有超过3600名合作伙伴出席了9月10日在上海世博馆举办的华特迪士尼有限公司大中华区2025消费品部启动大会。庞大的与会人数是行业对这家国际IP巨头期待值和迫切需求感的一种具象。这来自于迪士尼授权业务在过去一年的精彩表现,过去一年,以620亿美金的零售表现,迪士尼继续领跑全球授权业;中国公司及其合作伙伴则先后获得2项亚洲授权业卓越大奖及3项中国授权业大奖。0000幻方量化回应管理规模缩水:正常的规模变动
据近日消息,针对传闻中幻方量化管理规模大幅缩水的说法,该公司市场部人员做出回应,称公司管理规模已超过200亿元。对于规模变动原因,其表示为正常波动。幻方量化作为国内知名量化机构,成立于2015年,发展迅速,旗下拥有九章资产和宁波幻方量化两家百亿级平台。0000AI音乐创作助手Soundful 提供各种风格的音乐模板
Soundful是一个一站式音乐创作助手,让你只需轻点按钮就能创作出专业水准的原创音乐。Soundful提供各种风格的音乐模板,涵盖流行、电子、嘻哈等多种流派。你可以根据风格、心情或喜好的艺人,快速找到适合你创作风格的模板。随机预览模板,一目了然Soundful为你提供的无限可能。体验地址:https://my.soundful.com/站长网2023-09-18 09:55:330000腾讯绝艺AI登顶日本麻将平台 AI决策能力提升
站长网2023-07-12 16:23:470000