StoryDiffusion:保持角色一致,可生成多图漫画和长视频
站长网2024-05-06 20:36:040阅
划重点:
🔮 Consistent self-attention 实现角色连贯图像生成
🎥 Motion predictor 实现长视频生成
🎨支持漫画生成、图像转视频、长短视频等多种内容生成功能
南开大学 HVision 团队开发了 StoryDiffusion,一款能够创造神奇故事的工具。StoryDiffusion可以保持角色一致,生成多图漫画和长视频。

该工具通过实现 Consistent self-attention 和 Motion predictor,能够生成连贯的图像和视频。用户可以提供文本提示来生成角色连贯的图像序列,同时也能实现长视频生成,预测不同条件图像之间的运动,实现更大幅度的运动预测。
StoryDiffusion 的应用范围广泛,可用于漫画生成、图像转视频等多种场景。通过 Consistent self-attention 机制生成的图像,可以顺利过渡为视频,实现两阶段长视频生成方法。此外,结合两个部分,还能生成常长且高质量的 AIGC 视频。

用户可以通过提供一系列用户输入的条件图像,使用 Image-to-Video 模型生成视频。此外,用户可以通过 Jupyter notebook 或本地 adio demo 来生成漫画。目前,该项目发布了生成漫画部分的源码。
产品入口:https://top.aibase.com/tool/storydiffusion
试玩入口:https://huggingface.co/spaces/YupengZhou/StoryDiffusion
0000
评论列表
共(0)条相关推荐
人工智能专家是自由职业市场的热门新职位:生成式 AI 相关职位数量增加近 250%
站长之家(ChinaZ.com)9月11日消息:VladHu曾作为一名软件工程师开始自己的职业生涯,最终创立了自己的软件公司,但在过去的一年里,最大的工作机会是自由职业的人工智能专家项目。站长网2023-09-11 10:09:540001ChatGPT编程时代来啦,GitHub Copilot Enterprise正式发布!
2月28日,全球最大开源平台之一GitHub在官网宣布——GitHubCopilotEnterprise正式全面发布。GitHubCopilotEnterprise核心模块之一GitHubCopilot,是一款基于OpenAI的GPT-4模型,并结合自身积累十多年真实、安全可靠的代码数据开发而成,开发人员通过文本提示就能获取、审核、扩展代码等功能。站长网2024-02-28 09:15:590002不满裁决!马斯克将脑机接口公司注册地迁至内华达州
快科技2月11日消息,据媒体报道,特斯拉CEO埃隆马斯克已将其脑机公司Neuralink注册地迁至内华达州。据了解,此前因特斯拉股东提出质疑,特斯拉CEO埃隆马斯克在特斯拉的550亿美元薪酬计划被美国特拉华州衡平法院首席法官驳回。该法官认为,特斯拉2018年授予马斯克的巨额期权奖励方案有失公平,但马斯克早已拿满所有奖励,总价值超过550亿美元。0000AI合成数据公司“光轮智能”完成天使+轮融资
光轮智能近期完成了天使轮融资。累计融资金额达数千万元人民币,投资方包括SEEFund、变量资本等。据介绍,光轮智能致力于为企业落地AI提供自动化、物理精确可控、真实、可泛化的合成数据解决方案,打造AI时代的数据基础设施。光轮智能开创性的将生成式AI与仿真技术深度融合,提供多模态、高质量、大规模、低成本的合成数据,弥补AI时代的数据缺口。站长网2023-07-25 16:18:390000微软专利:根据你的人体生成虚拟自我
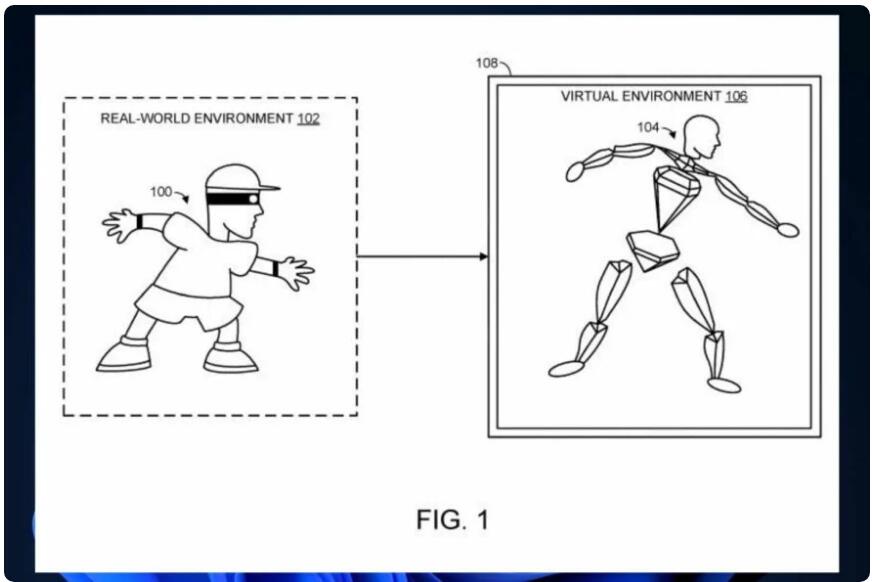
微软最近获得了一项专利,介绍了一种使用传感器数据根据用户真实身体生成虚拟自我的技术。这项技术能够捕捉用户身体的运动和位置信息,然后将其映射到一个虚拟模型上,以创造出一个超逼真的虚拟身体。这种虚拟身体不仅外观真实,而且能够模仿用户的动作和姿态。它通过优化算法和预训练来实现用户运动到虚拟身体运动的准确映射。这种技术的应用前景广阔,包括沉浸式社交平台、虚拟现实体验、运动追踪等。站长网2023-10-20 15:04:470001