写真视频击败Sora?人大自研全新多模态大模型Awaker 1.0震撼登场
站长网2024-04-29 16:59:142阅
在人工智能领域,人大系初创公司智子引擎近日发布了一款名为Awaker1.0的全新多模态大模型,标志着向通用人工智能(AGI)迈出了重要一步。该模型在写真视频效果上超越了Sora,展现了其在视觉生成方面的卓越能力。
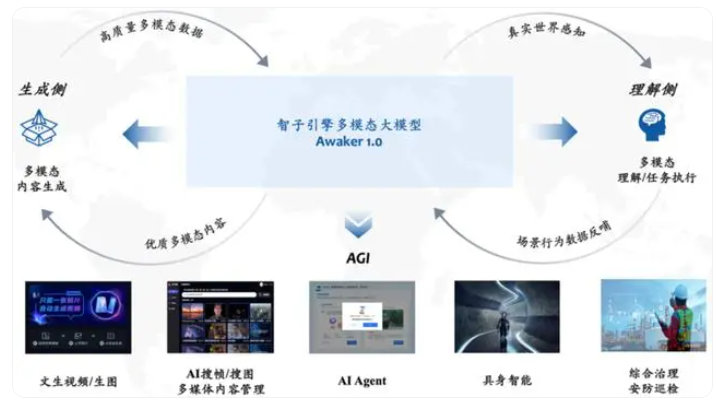
4月27日,在中关村论坛的通用人工智能平行论坛上,智子引擎展示了这款业界首个真正实现自主更新的多模态大模型。Awaker1.0采用了创新的MOE架构,具备自主更新能力,能够生成高质量的多模态内容,模拟现实世界,同时在执行任务中将场景行为数据反哺给模型,实现持续更新与训练。
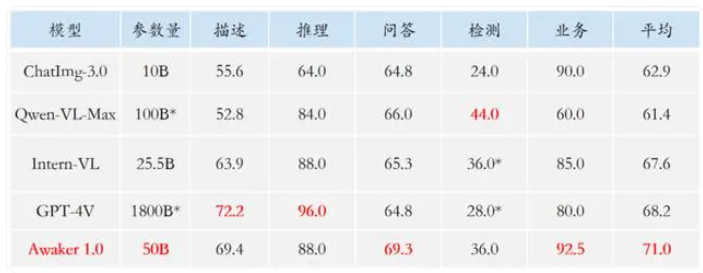
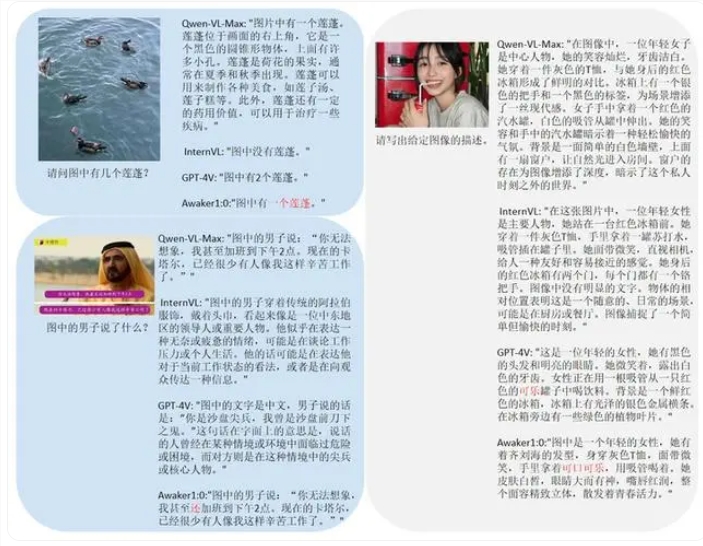
在视觉问答和业务应用任务上,Awaker1.0的基座模型超越了GPT-4V、Qwen-VL-Max和Intern-VL等国内外先进模型。此外,它还在描述、推理和检测任务上达到了次好的效果,证明了多任务MOE架构的有效性。
结合具身智能,Awaker1.0被认为可能成为实现AGI的可行路径。它通过自主探索环境,发现新策略和解决方案,提升具身智能的适应性和创造性。Awaker1.0的自主更新机制包含数据主动生成、模型反思评估和模型连续更新三大关键技术,使其能够实时持续地更新参数。
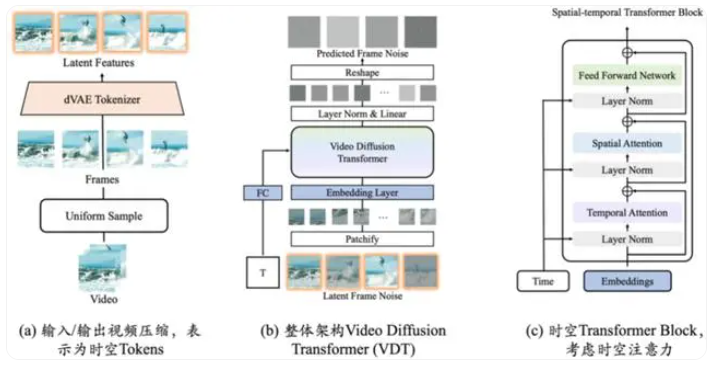
智子引擎自主研发的类Sora视频生成底座VDT,作为现实世界的模拟器,展现了Transformer技术在视频生成领域的潜力。VDT能够处理多种视频生成任务,如无条件生成、视频后续帧预测等,并在写真视频生成任务上取得了比Sora更好的质量。
Awaker1.0的发布是智子引擎团队向实现AGI目标迈进的关键一步。团队认为,AI的自我探索、自我反思等自主学习能力是智能水平的重要评估标准。Awaker1.0在理解侧和生成侧都实现了效果突破,有望加速多模态大模型行业的发展,最终让人类实现AGI。
0002
评论列表
共(0)条相关推荐
安卓 15 新设计!音量调节面板功能大改
在最新的Android15开发者预览版中,谷歌带来了全新的音量调节面板设计。这一设计与之前版本相比有了明显的变化。站长网2024-04-06 14:16:150000免费在线AI工具LeiaPix:一键将图片转3D动画
Leia是一家总部位于美国的领先供应商,专注于裸眼3D显示硬件和软件解决方案。他们旗下的LeiaPixConverter是一款由AI技术驱动的图像处理工具,可以将静态的2D图像转换为动态的3D图像。体验地址:https://convert.leiapix.com/站长网2023-08-14 14:35:5100021Password瘫痪了大约一个小时,导致部分用户无法登录
划重点:1.🔒1Password遭遇故障,导致部分用户无法登录,公司正在调查。2.🛠️1Password在确认问题后的一小时内发布了修复补丁。3.🌐故障影响全球用户,尤其是欧洲、美国、加拿大等地,涉及单点登录、跨设备同步以及密码保存等问题。站长网2024-02-06 09:48:360000“高压锅”除了用来炖肉还能干嘛?
俗话说,人往高处走,水往低处流。自古以来,人们就对高处的地方有着无穷的向往。对于物理学家来说,除了可以攀爬地理上山峰以外,也要不断攀登科学的高峰,这意味着需要不断创造更极限的实验环境。众所周知,生活在平原或者低海拔地区的人在进入高原后,由于气压降低,氧气含量降低,同时可能受紫外线、气温低等因素影响容易出现高原反应。站长网2023-05-24 16:00:260000雷军宣布小米内部精英驾驶培训12月招募:首批开放Ultra用户
快科技11月17日消息,日前,小米CEO雷军宣布,小米内部的精英驾驶培训将逐步向用户开放,首批先开放给Ultra小定用户,12月开始招募。雷军还询问大家希望学哪些驾驶课程?高级驾驶技巧、赛道训练、赛车证培训、漂移等。据了解,雷军曾在发布会和直播中提到,未来将考虑对小米车主朋友们开放小米公司内部的高级驾驶培训、赛道驾驶培训、漂移培训三类课程。站长网2024-11-17 12:45:530000