LLaVA++:为Phi-3和Llama-3模型增加视觉处理能力
站长网2024-04-28 16:57:260阅
LLaVA 项目通过扩展现有的LLaVA模型,成功地为LLaVA 和Llama-3模型赋予了视觉能力。这一改进标志着AI在多模态交互领域的进一步发展。
主要创新点包括:
模型整合: LLaVA 将Phi-3和Llama-3模型进行整合,创建了具备视觉处理能力的Phi-3-V和Llama-3-V版本。
图像理解与生成: 新模型不仅能够理解与图像相关的内容,还能生成视觉内容,扩展了模型的应用范围。
复杂指令执行: 增强的视觉处理能力使得模型能够更准确地理解和执行与视觉内容相关的复杂指令。
学术任务处理: 在需要同时理解图像和文本的学术任务中,LLaVA 展现了更高的准确率和效率,提升了模型的学术研究和教育应用潜力。
LLaVA 的优势:
通过赋予Phi-3和Llama-3视觉能力,LLaVA 项目不仅提升了AI模型的多模态交互能力,还为图像识别、视觉问答、视觉内容创作等领域带来了新的机遇。这种跨模态的能力增强,使得AI模型在执行需要视觉和文本结合的任务时更加得心应手。
LLaVA 的推出,预示着未来AI模型将更加智能和灵活,能够更好地服务于需要视觉与文本结合理解的复杂场景。
项目地址:https://top.aibase.com/tool/llava-
0000
评论列表
共(0)条相关推荐
马斯克称微软使用推特数据非法训练其人工智能 威胁要提起诉讼
微软将在下周将Twitter从其广告平台中删除,这是在Twitter宣布它将开始向其API的用户(包括企业和研究机构)每月收取至少42000美元的费用近两个月后。凭借其2.15万亿美元的市值和去年年底手头约1000亿美元的现金,微软显然有足够的钱向Twitter支付它想要的东西,所以此举似乎有点像一个声明,即使微软拒绝进一步阐述其决定。站长网2023-04-20 09:15:070001英伟达投资与谷歌相关的生成式 AI 初创公司 Cohere:专注于企业市场
专注于企业的生成人工智能初创公司Cohere在C轮风险投资中筹集了2.7亿美元,其中包括AI巨头英伟达作为投资者。站长网2023-06-09 23:45:290000Vectara排行榜:OpenAI的GPT-4在文档摘要中幻觉率最低
**划重点:**1.📊Vectara的排行榜显示,OpenAI的GPT-4在文档摘要中具有最低的幻觉率,准确率为97%。2.🚀GPT-4和GPT-4Turbo表现最佳,GPT-3.5Turbo排名第二,MetaLlama为最高得分的非OpenAI模型,而GooglePalm排名最后。站长网2023-11-22 10:44:140000百度将举办Create AI开发者大会 AI芯片昆仑等多项成果将亮相
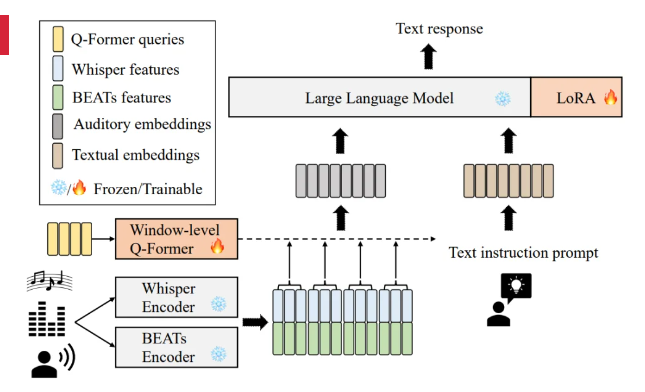
百度宣布百度CreateAI开发者大会已正式定档于2024年4月16日至17日,在深圳国际会展中心(宝安)隆重举办。届时,百度创始人、董事长兼CEO李彦宏将发表主题演讲,展示最新的百度AI技术突破,并分享对未来趋势的独到见解。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-02-05 15:23:420001音频文本多模态LLM SALMONN:可处理语音、音乐等基本音频
**划重点:**1.🤖SALMONN是一个单一的音频-文本多模型大型语言模型框架,旨在使大型语言模型能够直接理解和处理包括语音、音频事件和音乐在内的通用音频输入。2.🎙️该框架通过使用两个听觉编码器(非语音BEATs音频编码器和源自OpenAIWhisper框架的语音编码器)以及窗口级Q-Former等组件,实现了高水平的时间分辨率,用于音频-文本对齐。站长网2023-11-29 11:17:130000