phi-3安装指南:如何在 MacBook Pro 上微调 phi-3
博主Abhishek Thakur在博客中向大家展示了如何在 MacBook Pro 上训练/微调 Microsoft 的最新 phi-3模型!用户需要使用 M1或 M2mac 来执行此操作。之后将使用 AutoTrain Advanced来微调 phi-3。
要安装 AutoTrain Advanced,您可以执行以下操作:
$pipinstallautotrain-advanced
注意:autotrain不安装pytorch、torchvision等,所以需要自己安装。您可以创建 conda 环境并安装这些依赖项:
$condacreate-nautotrainpython=3.10
完成后,您可以在 Mac 计算机上使用 AutoTrain CLI 或 UI!我们将看看两者!
AutoTrain 不仅提供 LLM 微调,还提供许多其他任务,例如文本分类、图像分类、dreambooth lora 等。但在这篇博文中,我们正在研究 LLM 微调。
您可以通过执行以下操作来查看可以调整 llm 微调的所有参数
$autotrainllm--help
下一步是抓取数据。在这篇博客中,我将向您展示如何在 MacBook 上通过 SFT 训练和 ORPO 调整(DPO 的大而小的兄弟)进行训练。
对于 SFT 训练,我们需要一个具有单个文本列的数据集。我们可以使用timdettmers/openassistant-guanaco或 alpaca 之类的数据集。注意:这些数据集已经格式化为带有系统提示、用户指令和辅助消息的文本。如果它们的格式如下:[{"content":"Definition:Inthistask,youneedtocountthenumberofvowels(letters'a','e','i','o','u')/consonants(alllettersotherthanvowels)inthegivensentence.\nInput:Sentence:'abaseballplayerisinhishittingstanceasafewpeoplewatch'.Countthenumberofconsonantsinthegivensentence.\nOutput:","role":"user"},{"content":"32","role":"assistant"}]
您可以使用 AutoTrain 的 chat-template 参数。我们将在本文后面看到它,但用于 ORPO 培训。因此,我们将介绍使用预格式化数据集进行 SFT 训练,并使用聊天模板进行 ORPO 训练。
对于 ORPO 训练,您可以使用argilla/distilabel-capybara-dpo-7k-binarized等数据集。该数据集有很多列,但我们只对chosen&列感兴趣rejected。
使用 AutoTrain,仅创建或查找数据集将是最耗时的部分。现在,当我们拥有数据集时,我们可以使用以下方法进行 SFT 训练:
autotrainllm其中 $HF_TOKEN 是您的拥抱面部写入令牌,以防您希望将经过训练的模型推送到拥抱面部中心以方便部署和共享。您可以在这里找到您的代币。
请注意,我们使用的是 lora,这就是我们有--peft参数的原因。另外,如果text您的数据集中未调用文本列,您可以添加另一个参数--text-column your_datasets_text_column。如果您想使用自己的 CSV/JSON 文件而不是拥抱面部中心数据集,您可以将其命名为 train.csv / train.jsonl 并将其放置在本地文件夹中。训练命令将略有变化:
autotrainllm接下来,我们来进行orpo培训。对于 orpo 训练,我们更改--trainer sft为--trainer orpo.
autotrainllm以上有4处变化。只有列映射发生了变化,训练器,当然还有数据集。另一项主要变化是--chat-template设置为 的参数的使用chatml。对于--chat-template,选项有:zephyr、chatml或tokenizer无。如果您已经像我们在 SFT 训练中那样自行正确格式化了数据,则不会使用任何内容。
现在,如果 CLI 对您来说太难了,您还可以使用 UI!这更容易,并且还允许您上传文件。
要使用用户界面:
$exportHF_TOKEN=your_huggingface_write_token
然后在浏览器中访问https://127.0.0.1:10000并享受AutoTrain UI! 🚀 与上面 ORPO 训练具有相同参数的屏幕截图如下所示:
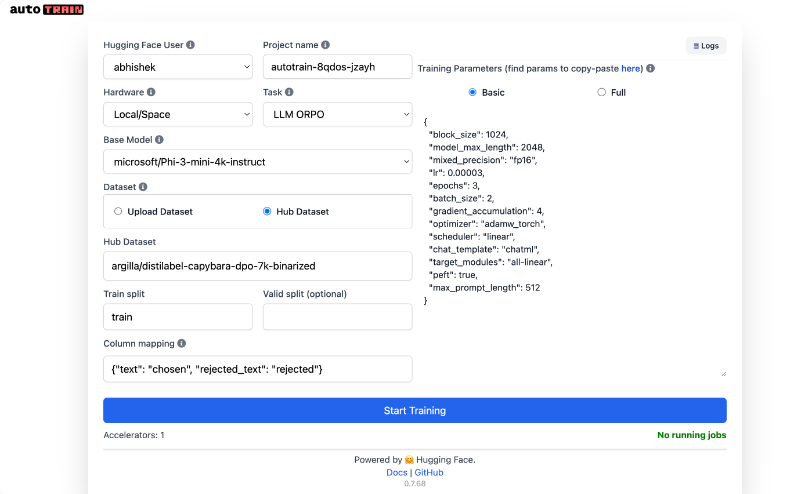
如果您无法在模型下拉列表中找到 phi3,您可以使用以下 URL:https://127.0.0.1:7860/?custom_models=microsoft/Phi-3-mini-4k-instruct。注意:我已添加 phi-3作为自定义模型。您可以对 Hub 中的任何其他兼容型号执行相同的操作。 ;)
SFT 和 ORPO 训练均在 M2Max MacBook Pro 上成功进行了测试。
详细文档点此查看:https://huggingface.co/docs/autotrain/index
“东北雨姐”虚假宣传被罚165万元:红薯粉条样品未含红薯成分
近日,本溪县市场监督管理局对外宣布,针对本溪雨姐传媒有限公司(以下简称"雨姐传媒")在直播带货中涉嫌虚假宣传的问题,已完成调查并依法作出处罚决定。0000FF:已做好扩大产能准备 三季度累计交付三辆FF 91
昨日晚间,FaradayFuture发布致全体股东的一封信称,大规模高质量的交付仍然是公司当前最重要的战略目标。在获得额外融资的同时,公司计划在今年为塔尖用户交付更多的FF912.0FuturistAlliance车辆,并在未来提升生产能力和销量。公司还将专注于系统建设,根据资源可用性和战略需求分阶段实施。我们的目标是建立一个灵活、高效、自主运营和自我进化的AI管理系统。站长网2023-09-28 08:37:150000烧钱!OpenAI的ChatGPT每天维护成本高达70万美元
根据研究公司SemiAnalysis的数据,ChatGPT的巨大知名度和强大功能使其维护成本高得惊人,TheInformation报道称,维护OpenAI的ChatGPT等对话式人工智能引擎每天的开销高达70万美元。。站长网2023-04-24 09:51:200000AI独角兽月之暗面创始人杨植麟套现数千万美金 官方回应
据界面报道,月之暗面创始人杨植麟在最近的融资轮后通过个人股份销售获得了数千万美元,引起了广泛关注。据悉,月之暗面成立仅一年时间就迅速崛起。根据天眼查App显示,杨植麟持有“北京月之暗面科技有限公司”约78.968%的股份,是公司最大的股东。今年2月,月之暗面完成了一轮10亿美元的新融资,由阿里巴巴领投,其他机构包括红杉资本中国、小红书和美团等跟投,导致投后估值超过25亿美元。0001看完这场震惊所有人的“虚拟人”对话,我觉得元宇宙可能真要来了…
元宇宙这个概念,自从2021年被扎克伯格带火后,给人们的感觉一直就像个“最熟悉的陌生人”,总是若即若离,忽远忽近的。说直白点儿,就是大家都觉得它存在感不够强,没有想象的那么厉害。因为提起元宇宙,网友们脑海中的印象还是这样的:扎克伯格曾遭到“群嘲”的著名HorizonWorlds虚拟形象自拍,图片来自Facebook站长网2023-10-01 21:53:320000