谷歌更新Transformer架构,更节省计算资源!50%性能提升
谷歌终于更新了Transformer架构。
最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。
它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。
结果显示,在等效计算量和训练时间上,MoD每次向前传播所需的计算量更小,而且后训练采样过程中步进速度提高50%。
这一方法刚刚发布,就马上引发关注。
MoE风头正盛,MoD已经来后浪拍前浪了?

还有人开始“算账”:
听说GPT-4Turbo在Blackwell上提速30倍,再加上这个方法和其他各种加速,下一代生成模型可以走多远?

所以MoD如何实现?
迫使大模型关注真正重要信息
这项研究提出,现在的大模型训练和推理中,有很多计算是没必要的。
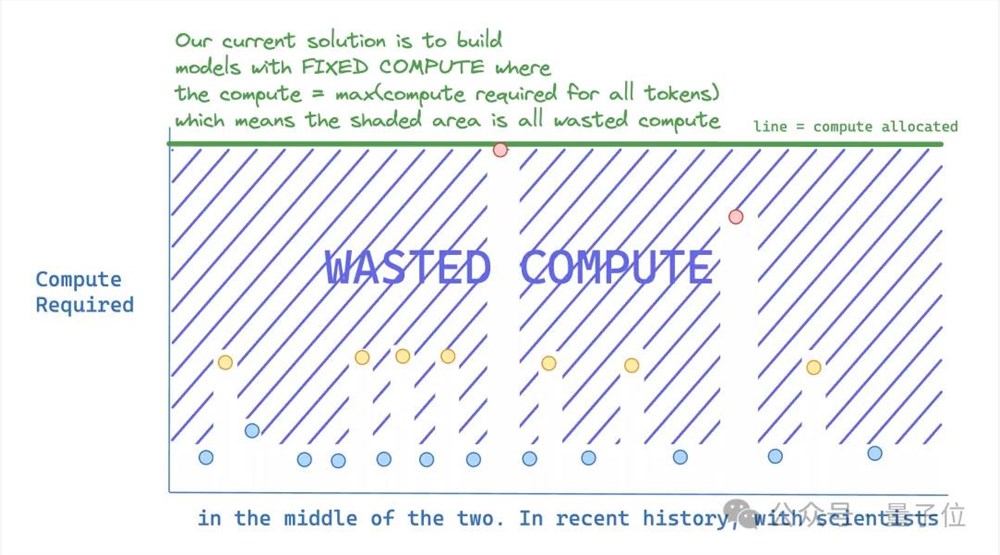
比如预测下一个句子很难,但是预测句子结束的标点符号很简单。如果给它们分配同样的计算资源,那么后者明显浪费了。
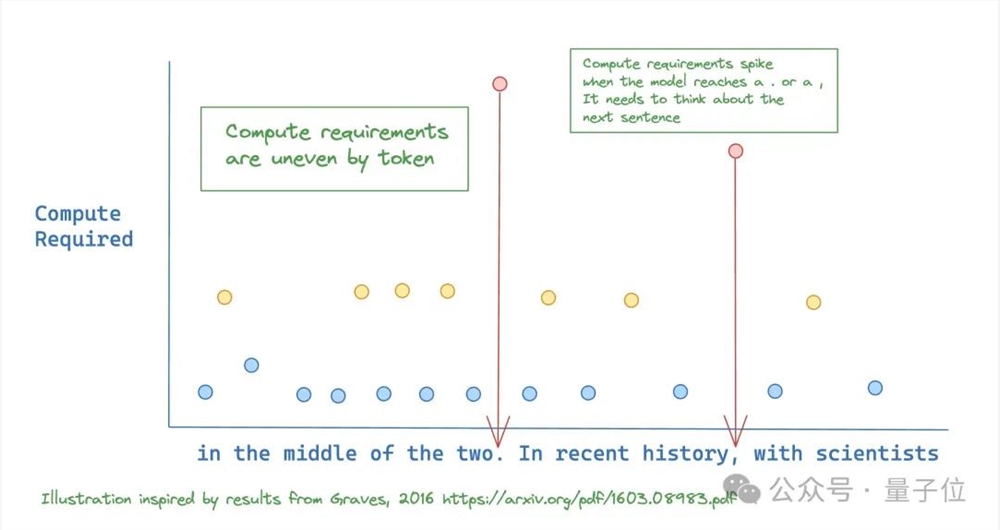
在理想情况下, 模型应该只给需要准确预测的token分配更多计算资源。
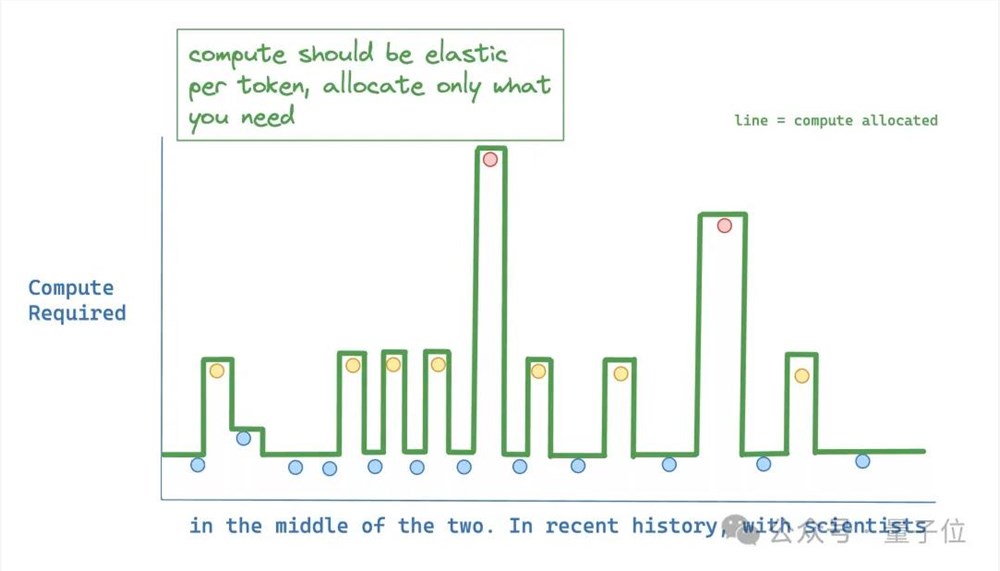
所以研究人员提出了MoD。
它在输入序列中的特定位置动态分配FLOPs(运算次数或计算资源),优化不同层次的模型深度中的分配。
通过限制给定层的自注意力和MLP计算的token数量,迫使神经网络学会主要关注真正重要的信息。
因为token数量是事先定义好的,所以这个过程使用一个已知张量大小的静态计算图,可以在时间和模型深度上动态扩展计算量。
下图右上图中的橙色部分,表示没有使用全部计算资源。
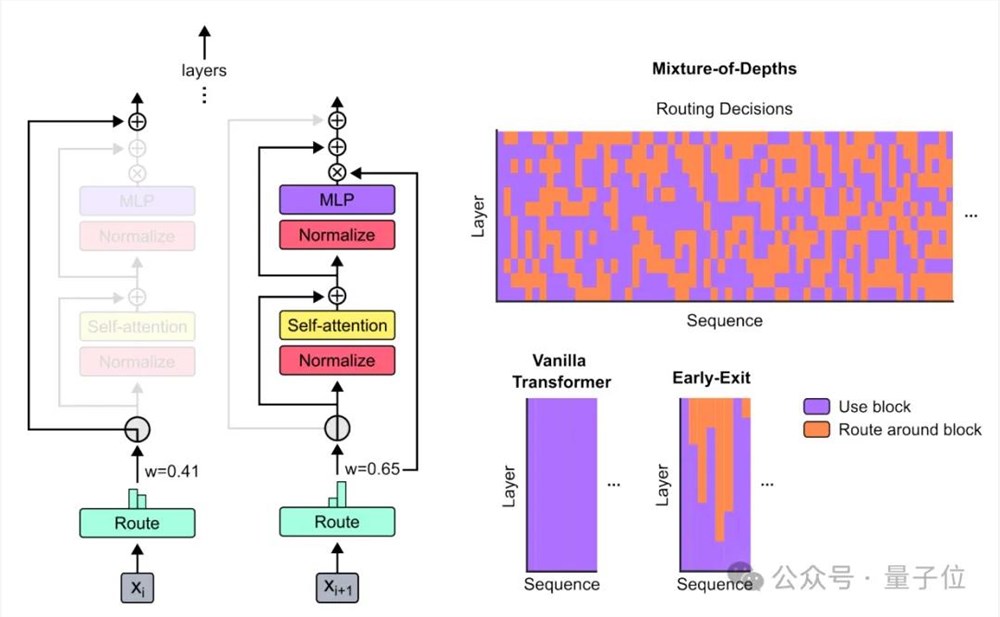
这种方法在节省计算资源的同时,还能提高效率。
这些模型在等效的FLOPS和训练时间上与基线性能相匹配,但每次前向传播所需的FLOP更少,并且在训练后采样时提速50%。
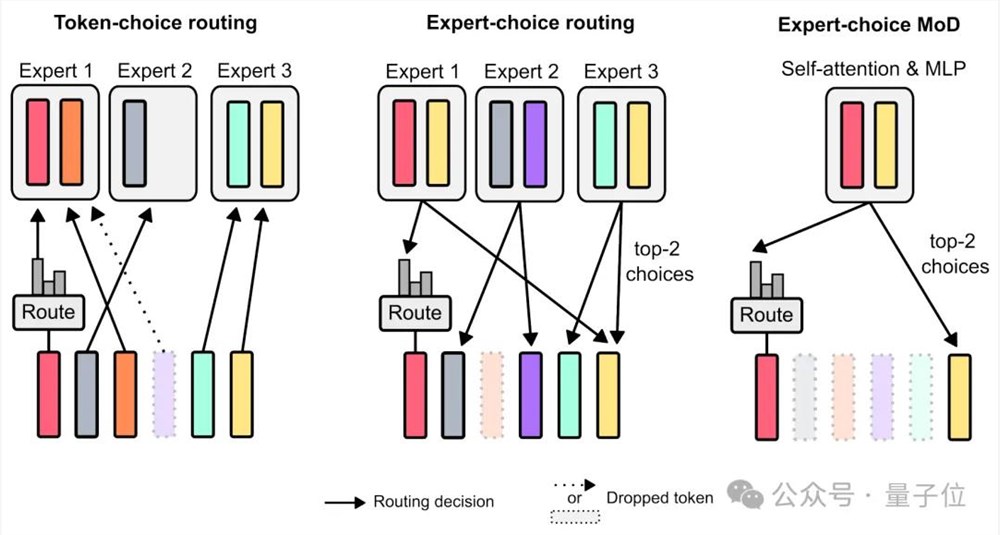
对比来看,如果为每一个token生成一个概率分布,每个token根据最高概率被送去对应的“专家”,可能会导致负载不平衡。
如果反过来,这能保障负载平衡,但是可能导致某些token被过度处理或处理不足。
最后来看论文中使用的Expert-choice MoD,router输出的权重被用于确定哪些token将使用transformer亏啊计算。权重较大的token将参与计算,权重较小的token将通过残差连接绕过计算,从而解决每次向前传播的FLOPs。
最后,研究团队展示了MoD在不同实验中的性能表现。
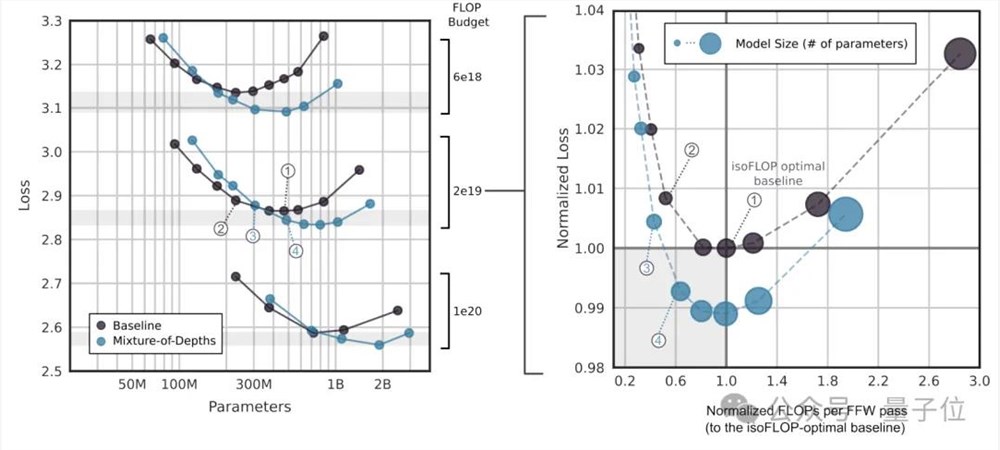
首先,他们使用相对较小的FLOP预算(6e18),以确定最佳超参数配置。
通过这些实验,作者发现MoD方法能够“拉低并向右推移”isoFLOP基线曲线,这意味着最优的MoD方法在更低的损失水平上拥有更多的参数。
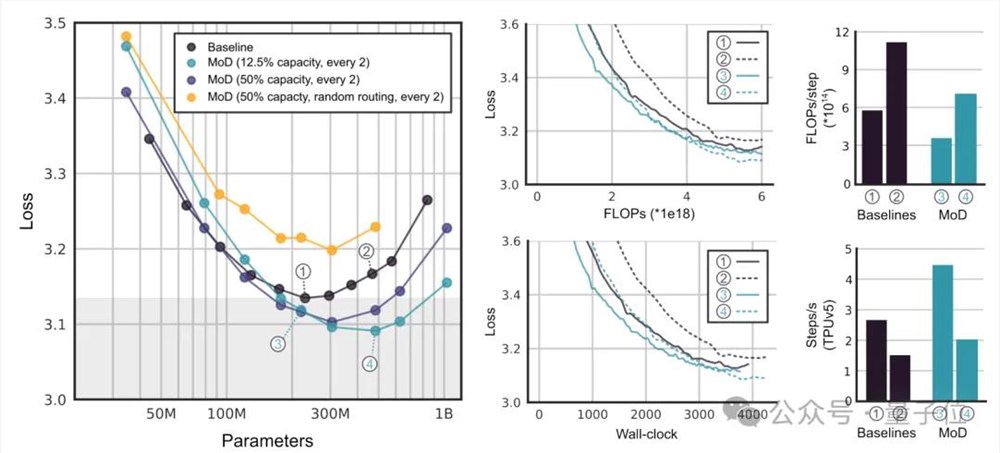
通过isoFLOP分析,比较6e18、2e19和1e20FLOPs的总计算预算下的模型性能。
结果显示,在更多FLOP预算下,FLOP最优的MoD仍然比基线模型有更多的参数。
存在一些MoD变体,在步骤速度上比isoFLOP最优基线模型更快,同时实现更低的损失。这表明在训练之外,MoD的计算节省仍然有效。
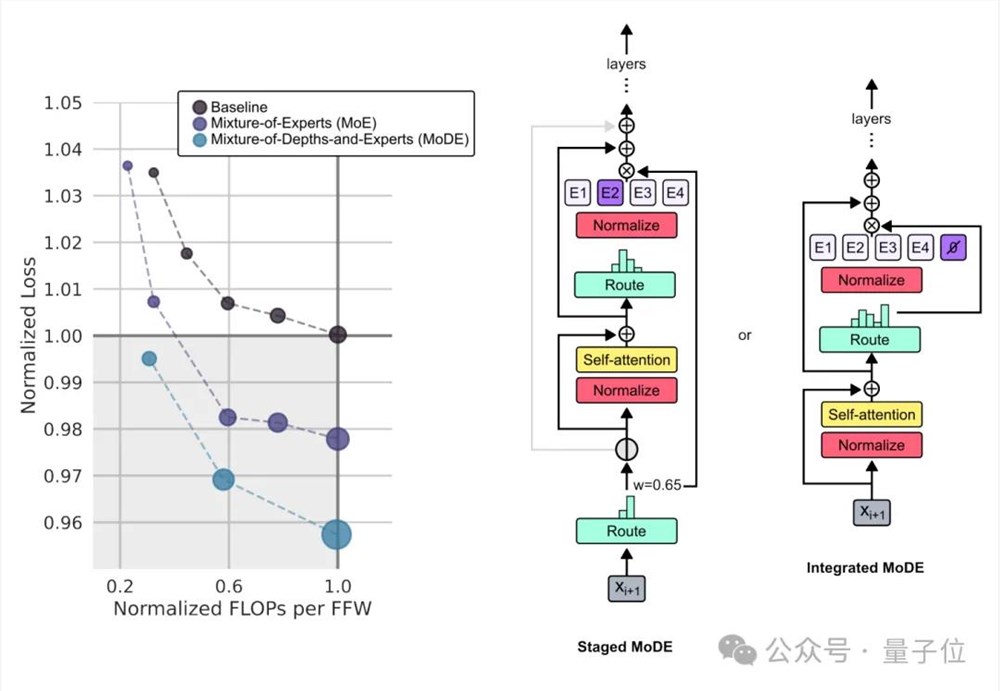
同时,研究团队还探讨了MoD和MoE结合的可能性——MoDE。
结果表明而这结合能提供更好的性能和更快的推理速度。
网友:联想到了ResNet
MoD推出后马上引发了不小关注。
有人感慨,MoE还没有弄清楚呢,MoD都已经来了!

这么高效的方法,让人马上联想到了ResNet。

不过和ResNet不同,MoD跳过连接是完全绕过层的。

还有人表示,希望这种方法是完全动态的,而不是每个层固定百分比。

这项研究由DeepMind和麦吉尔大学共同带来。
主要贡献者是David Raposo和Adam Santoro。
他们二人都是DeepMind的研究科学家。此前共同带来了神作《Relational inductive biases, deep learning, and graph networks》。
这篇论文目前被引次数超过3500次,论文核心定义了Inductive bias(归纳偏置)概念。
论文地址:
https://arxiv.org/abs/2404.02258
参考链接:
[1]https://twitter.com/TheSeaMouse/status/1775782800362242157
[2]https://twitter.com/_akhaliq/status/1775740222120087847
—完—
咖啡价格战打到3元一杯,你敢喝吗?
库迪咖啡的价格战“你们这里的咖啡最近有活动吗?”“优惠活动一直都有的,今天小程序领券8块8任饮,如果您是新用户还能1元喝。”公司楼下的库迪咖啡,在这周一又发了一波8.8元任饮券。库迪咖啡的员工说着与往日一贯的话术,上次来他们说的还是抖音领券能喝9.9元的咖啡,但与之前不同的是,他们店里的员工从4人减少到了2人,而那个刚刚问有没有活动的顾客,却被同伴拉去了库迪对面的星巴克。站长网2023-06-30 01:35:050000北京出台机器人新政 支持开发机器人强化AI大模型支撑
6月28日,北京市人民政府办公厅印发《北京市机器人产业创新发展行动方案(2023—2025年)》,对人形机器人等细分产业的发展制定了目标和行动细则。站长网2023-06-30 23:54:070001报告:到 2030 年,AI将使美国经济 30% 工作时间实现自动化
人工智能(AI)将在不久的将来取代无数工作岗位的威胁已成为近来的全球热点问题。一份新的报告揭示了人工智能如何影响美国的就业市场以及它的负面影响。根据一份新报告,到2030年,生成式人工智能可能占美国经济工作时间的30%。麦肯锡全球研究所题为《生成式人工智能与美国工作的未来》的研究称,人工智能有潜力大大加速经济自动化。站长网2023-07-31 11:46:220000Perplexity将推出图像生成服务 可根据用户搜索内容和结果生成图片
Perplexity现在可以根据用户的搜索内容和结果生成图片了。CEO表示他们即将推出图像生成服务。有用户表示已经试用了一下,并且发现这个功能确实已经上线了。这样一来,用户在搜索完内容后可以整理出一张生成的图片作为头图,然后直接发布。站长网2023-12-15 16:52:280001春晚观众中60万大奖 屏蔽客服电话 京东:华为全家桶不要了?
今年春节,京东荣幸地成为中央广播电视总台《2024年春节联欢晚会》的独家互动合作平台。为了增添节日的喜庆气氛,京东特意准备了价值高达60万元的春晚互动大奖,奖品包括华为全场景旗舰产品及问界M9。站长网2024-02-20 08:25:270000