Stability AI发布音频模型 Stable Audio2.0:支持生成多种类型音乐 时长达3分钟
站长网2024-04-18 14:54:351阅
划重点:
⭐️ Stability.ai 发布了音频模型 Stable Audio2.0,支持生成多种类型音乐,时长达3分钟。
⭐️ Stable Audio2.0采用 DiT 替换 U-Net 架构,生成效率显著提升。
⭐️ 用户可免费试用 Stable Audio2.0生成音乐,支持商业化使用。
著名开源大模型平台 Stability.ai 在官网正式发布了音频模型 Stable Audio2.0。这一版本支持用户通过文本或音频生成多种类型的高质量音乐,时长可达3分钟44.1kHz。
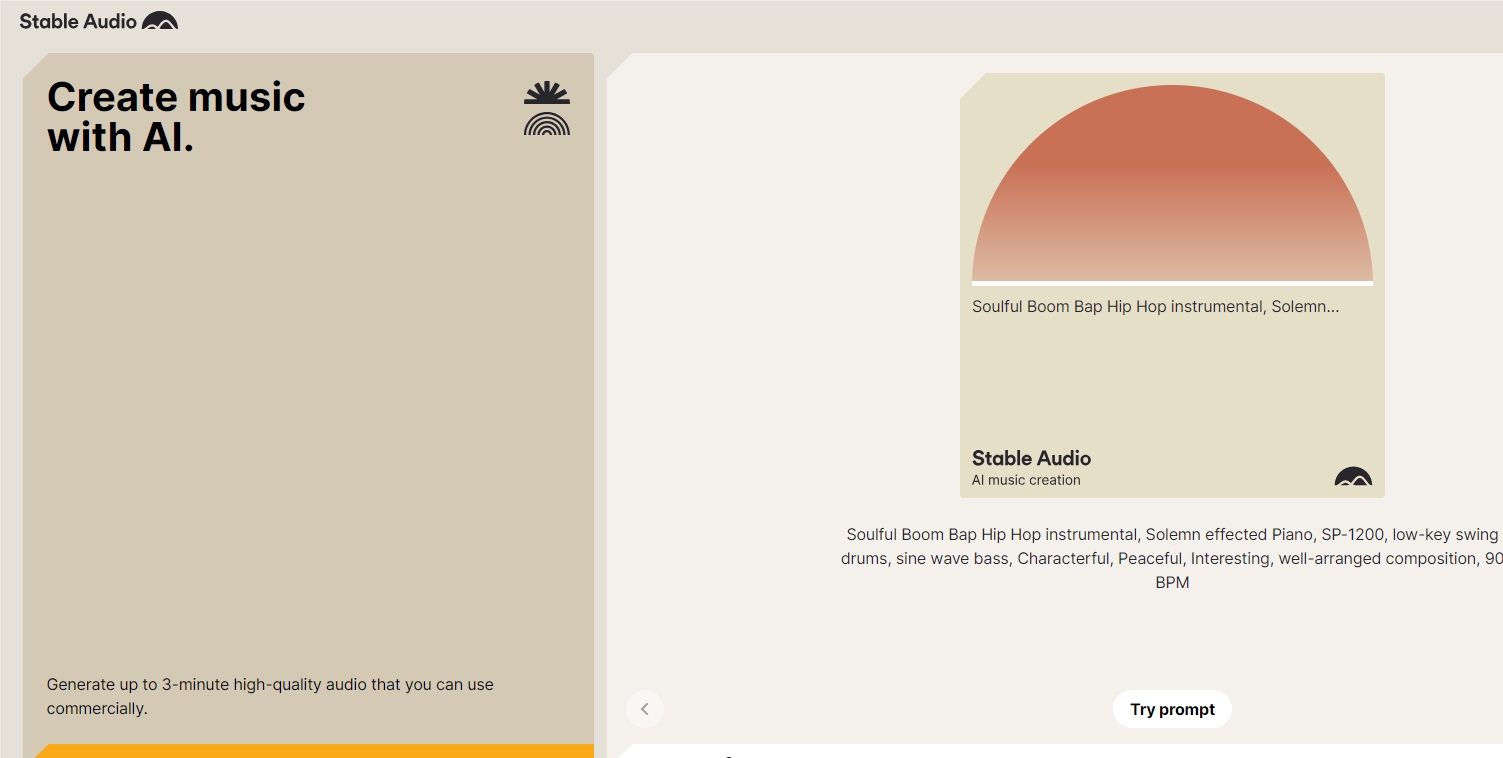
相较于之前的版本,Stable Audio2.0采用了 Diffusion transformer(DiT)替换了 U-Net 架构,使得生成音乐的效率大幅提升。此外,该模型使用了超过80万个音频文件组成的数据集,总计超过1.95万小时的音频,与知名音乐服务商 AudioSparx 合作,生成的音乐可用于商业化。
用户在体验 Stable Audio2.0时,可以通过输入提示词来生成不同类型的音乐,例如冥想背景音乐或体育赛事激情音乐等。生成的音乐可以在网站上在线试听,也可选择下载使用。
对于视频自媒体用户来说,Stable Audio2.0免费赠送20积分,并支持商业化使用,为他们的创作提供了更多可能性。随着 Stability.ai 不断推出新功能和技术,用户可以期待更多高质量、多样化的音乐生成体验。
体验地址:https://stableaudio.com/generate
0001
评论列表
共(0)条相关推荐
微信iOS 8.0.42正式版发布 新增多语言翻译功能
微信iOS版近日推出了8.0.42正式版更新,新版本中加入了一项实用的新功能:多语言翻译。在最新版本的微信中,点击“我”-“设置”-“通用”界面,就能看到新增的“翻译”功能。这项功能支持将文字翻译为多种语言,包括简体中文、繁体中文、英语、韩语等。用户在微信聊天、朋友圈、网页及图片中使用翻译功能时,文字会被翻译成所选语言。站长网2023-09-18 15:44:140000Google 支持的 Tempus AI 在纳斯达克首次亮相,首日交易上涨 9%
站长之家(ChinaZ.com)6月15日消息:TempusAI是一家利用人工智能(AI)解读医疗测试的诊断公司,旨在帮助医生为患者提供更准确的治疗方案。周五,该公司在纳斯达克首次亮相,股票代码为「TEM」,开盘后股价一度上涨了15%。站长网2024-06-16 03:19:380000Meta计划到2026年推出生成式AI模型,为Reels等提供支持
**划重点:**1.📹Meta公司计划通过生成式AI模型推动视频领域,包括Reels和更多内容。2.🔄目标是从为每个产品提供独特AI模型转变为一个整体生态系统,并提高用户推荐的参与度。3.💡Meta正致力于扩大模型规模,以适应硬件和数据需求,并希望通过AI进一步吸引用户,使其平台成为娱乐、连接和信息的一站式服务。站长网2024-03-08 13:36:350000人类考92分的题,GPT-4只能考15分:测试一升级,大模型全都现原形了
AutoGPT的得分也凉凉。GPT-4自诞生以来一直是位「优等生」,在各种考试(基准)中都能得高分。但现在,它在一份新的测试中只拿到了15分,而人类能拿92。站长网2023-11-26 13:25:100000OpenAI计划探索在课堂中使用ChatGPT的潜力,有批评者认为AI会助长作弊
**划重点:**1.OpenAI首席运营官BradLightcap表示,公司计划在明年组建团队,专注于探讨人工智能在教育中的应用。2.尽管一些教育工作者批评ChatGPT助长作弊,OpenAI仍在努力寻找人工智能在教育中的价值,并帮助教师解决相关问题。站长网2023-11-17 16:20:050000