宣称超过XTTS!VoiceCraft:一个支持克隆语音及修改原始音频文本的语音模型
站长网2024-03-25 13:36:442阅
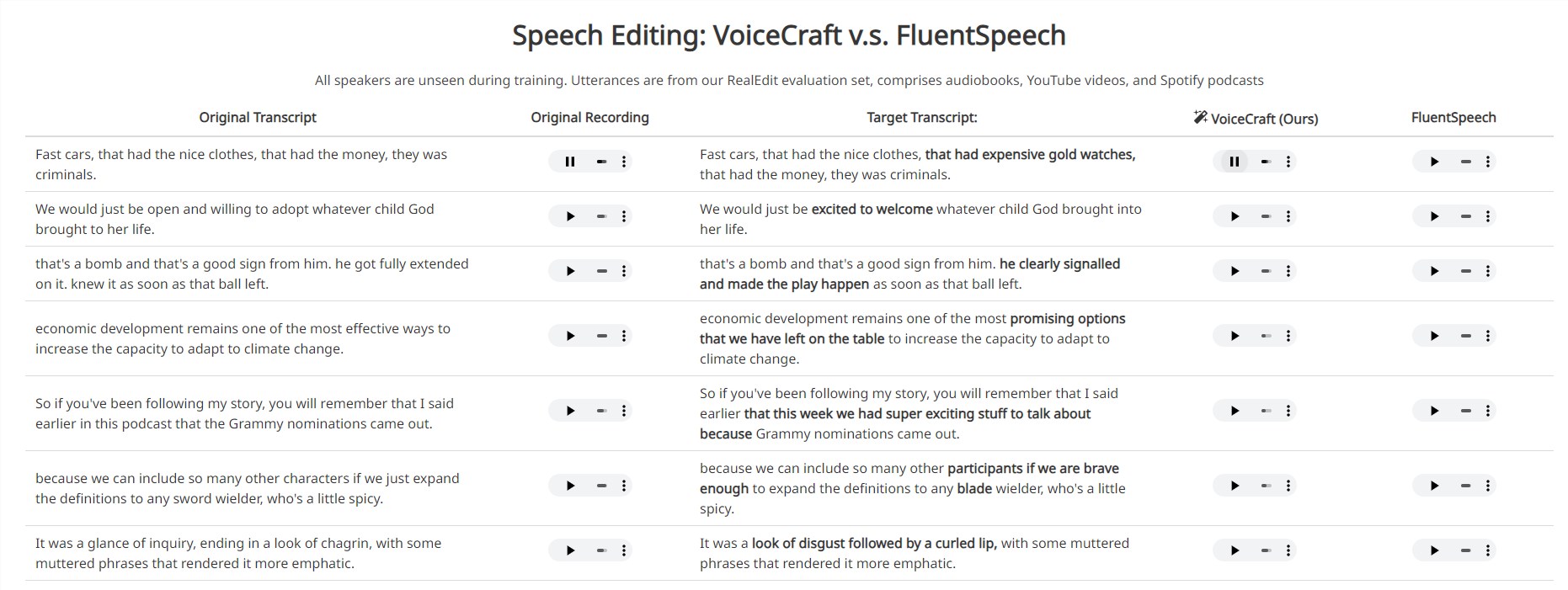
近日,一款名为VoiceCraft的语音模型引起了业界的广泛关注。据官方宣称,该模型的性能已经超过了XTTS,这无疑为AI音频处理领域带来了新的突破。
演示页面:https://top.aibase.com/tool/voicecraft
项目地址:https://github.com/jasonppy/VoiceCraft
VoiceCraft的最大亮点在于其强大的音频克隆能力。用户只需提供一段原始音频,VoiceCraft就能通过深度学习技术,复制出与原音频声音极为相似的新音频,这种“克隆”效果在演示中表现得非常出色。
除了音频克隆,VoiceCraft还支持通过修改原始音频的文本来编辑音频。这意味着,用户可以通过简单地修改文本,就能改变音频的内容,这对于音频制作和编辑来说,无疑大大提高了效率。
虽然目前还没有详细的试用报告出炉,但从已经公开的演示效果来看,VoiceCraft的表现确实令人印象深刻,显示出了巨大的潜力。
0002
评论列表
共(0)条相关推荐
席卷外网!99美元的DeepSeek教程,“收割”老外
“DeepSeek是目前最强大的AI工具,但99%的人都用错了!”海外社交平台“X(推特)”上,一位海外博主信誓旦旦表示,绝大多数人并不会使用DeepSeek,而自己将免费提供使用教程。老道的语气,一度让人直接幻视中国各个社交平台上的“AI大师”们。他们一边喊着打工人“学不会AI迟早被淘汰”,一边在自己的博文或者评论区里表示可以教学——通过收取学费的方式,顺手还能给自己的私域导流。0000马斯克谈人工智能安全和发展:我是 OpenAI 存在的原因
马斯克当在地时间周二的股东大会后接受CNBCDavidFaber的采访时称,他是「OpenAI存在的原因」,并引用了他过去对该公司的投资,以及微软对该人工智能公司的控制权,这一说法遭到微软首席执行官萨提亚·纳德拉的强烈否认。马斯克告诉DavidFaber说:「是我想出了这个名字。」他还表示,他在招募该公司的关键科学家和工程师方面发挥了重要作用。站长网2023-05-17 09:33:500000妙鸭相机B端工作站将上线 已开启内测
据新浪科技消息,妙鸭相机方面透露称,妙鸭相机B端工作站明日即将上线,目前已经邀请到一些摄像师、设计人员来做内测,同时也欢迎更多的人参与内测。“妙鸭相机”是一款AI写真应用,通过AI学习消费者上传的照片来构建人脸模型,只要上传完照片,就能产生无数风格的写真。据了解,此前妙鸭相机已上线了APP以及小程序版本。站长网2023-08-03 15:28:100000宇树发布“踢足球”机器人 网友:太好了 国足有救了
快科技1月22日消息,近日,宇树科技推出了G1人形机器人首个应用方案UnitreeG1-Comp,其被称作为赛事打造的足球巨星”。根据宇树官网资料显示,G1-Comp能在足球场地上做出奔跑、转身、转圈等基础动作。据视频画面显示,G1-Comp能通过头部摄像头精准锁定目标足球,完成一次标准的推射空门。站长网2025-01-22 20:20:370001