智源开源最强检索排序模型 BGE Re-Ranker v2.0
智源研究院推出了新一代检索排序模型 BGE Re-Ranker v2.0,支持100 种语言,文本长度更长,并在多项评测中达到了 SOTA(state-of-the-art)的结果。该模型是智源团队在 BGE(BAAI General Embedding)系列基础上的新尝试,扩展了向量模型的 “文本 图片” 混合检索能力。
BGE Re-Ranker v2.0采用分层自蒸馏策略优化推理效率,通过不同尺寸的模型基座(如 MiniCPM-2B、Gemma-2B、BGE-M3-0.5B)支持多语言检索能力。此外,该模型还新增了对 “文本 图片” 混合检索功能的支持,通过引入 CLIP 模型生成的 visual token 实现。
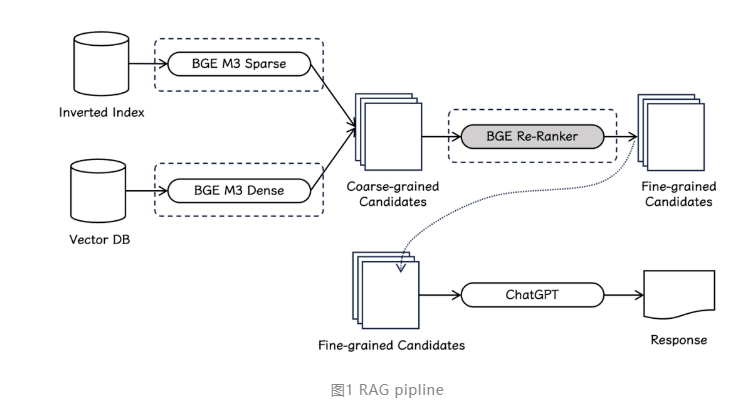
在性能评测方面,BGE Re-Ranker v2.0在英文、中文、多语言主流基准上取得了优秀的检索效果。例如,在 MTEB、C-MTEB、MIRACL、LLaMA-Index 等评测基准中,BGE Re-Ranker v2.0在重排 BGE-v1.5-large 的 top-100候选集时表现优异,提升了检索精度。同时,模型在 RAG 场景下也能够显著提升各种 embedding 模型的召回结果,配合 BGE-M3可以获得最佳的端到端检索质量。
BGE 系列模型的优秀性能和通用性也受到了社区的广泛关注,Vespa、Milvus 等主流向量数据库框架已经集成了 BGE-M3模型,为用户搭建 “三位一体” 的检索流水线提供了便利。
综上所述,智源研究院推出的 BGE Re-Ranker v2.0检索排序模型具有强大的多语言支持、更长文本长度、优秀的检索效果和灵活的 “文本 图片” 混合检索功能,为信息检索领域带来了新的利器。
项目地址:
https://github.com/FlagOpen/FlagEmbedding
https://huggingface.co/BAAI
AI日报:Luma官方亲自下场夸自家“孩子”;日本艺术家用Luma复活妻子看哭网友;苹果AI可能要放大家“鸽子”;北大快手联合推视频生成框架VideoTetris
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、Luma官方发视频介绍DreamMachine模型特点站长网2024-06-17 19:05:540001预计到2031年,合成数据生成市场规模将达到 35 亿美元
本文概要:1.全球合成数据生成市场预计在2031年达到35.8%的复合年增长率,市值将达到35亿美元。2.合成数据生成市场的增长受到数字化转型和人工智能等先进技术的推动,以及对物联网和连接设备的需求增加的影响。3.合成数据生成技术可以满足数据隐私和安全的需求,并提供一种可扩展的方法来生成各种数据集。站长网2023-08-14 16:39:150000打通谷歌办公软件 Bard与ChatGPT走差异化道路
时隔半年,曾被ChatGPT吊打的Bard发布重磅更新,打通了Gmail、Docs等谷歌办公应用全家桶的数据,支持一键转存AIGC内容至谷歌系的邮箱、文档、表格等应用程序中,还在对话页面加入“Googleit”自核实功能,避免对话机器人的幻觉Bug。事实上,Bard上线后一直在迭代,几乎每个月都有新版本发布,不断增加功能,比如语音输入,比如按用户文本指令直接给出过去需要搜索引擎才能找到的图片。站长网2023-09-25 09:30:310001字节跳动左转砍游戏 右转追AI
字节跳动裁员消息不径而走,旗下游戏业务朝夕光年将进行大规模业务收缩并逐步关停。而在不到半个月前,字节跳动传出有意以50亿美元作价出售旗下另一游戏工作室沐瞳科技。字节跳动CEO梁汝波曾在2023年初的年会上强调,新一年的目标是“聚焦”和“务实”,对于游戏、教育、PICO等新兴业务则要有想象力,保持平常心。站长网2023-11-29 11:58:270000ambientGPT:开源多模态MacOS基础模型操作界面 可调用GPT-4o API
划重点:⭐AmbientGPT可以运行GPT-4和本地基础模型,并直接了解屏幕环境,使基础模型不再局限于浏览器。⭐使用AmbientGPT,屏幕上下文将直接作为查询的一部分进行推断,无需再次显式上传上下文。⭐若要运行本地模型,需要使用ARM64MacBook,并使用兼容的OpenAIAPI密钥。站长网2024-05-24 10:21:030000