零一万物API开放平台出场!通用Chat多模态通通开放,还有200K超长上下文版本
3月,国内外模型公司动作频频。国产大模型独角兽“五小虎”之一零一万物也有诸多新动作。
这不,前脚刚发布高性能向量数据库,零一万物又立马正式发布了自己的API开放平台,
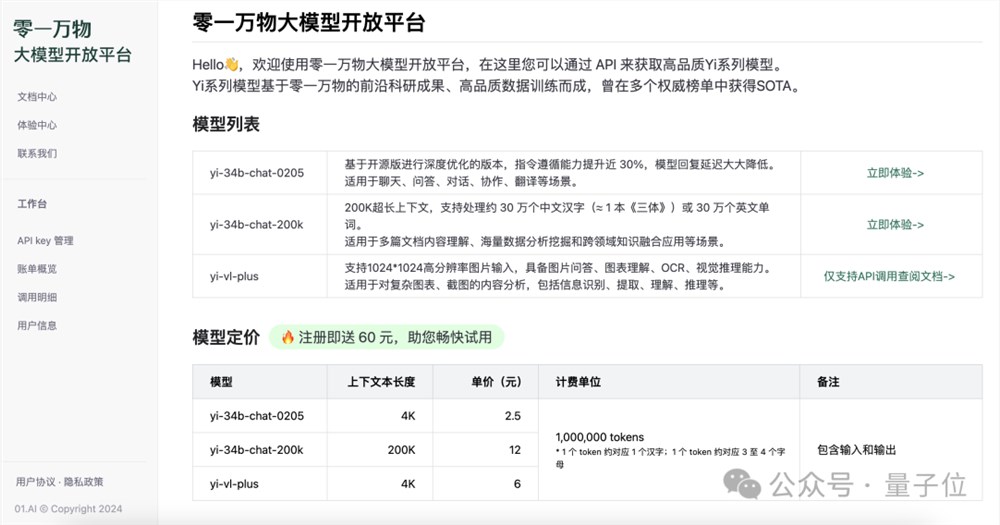
共为开发者提供三个版本的模型:
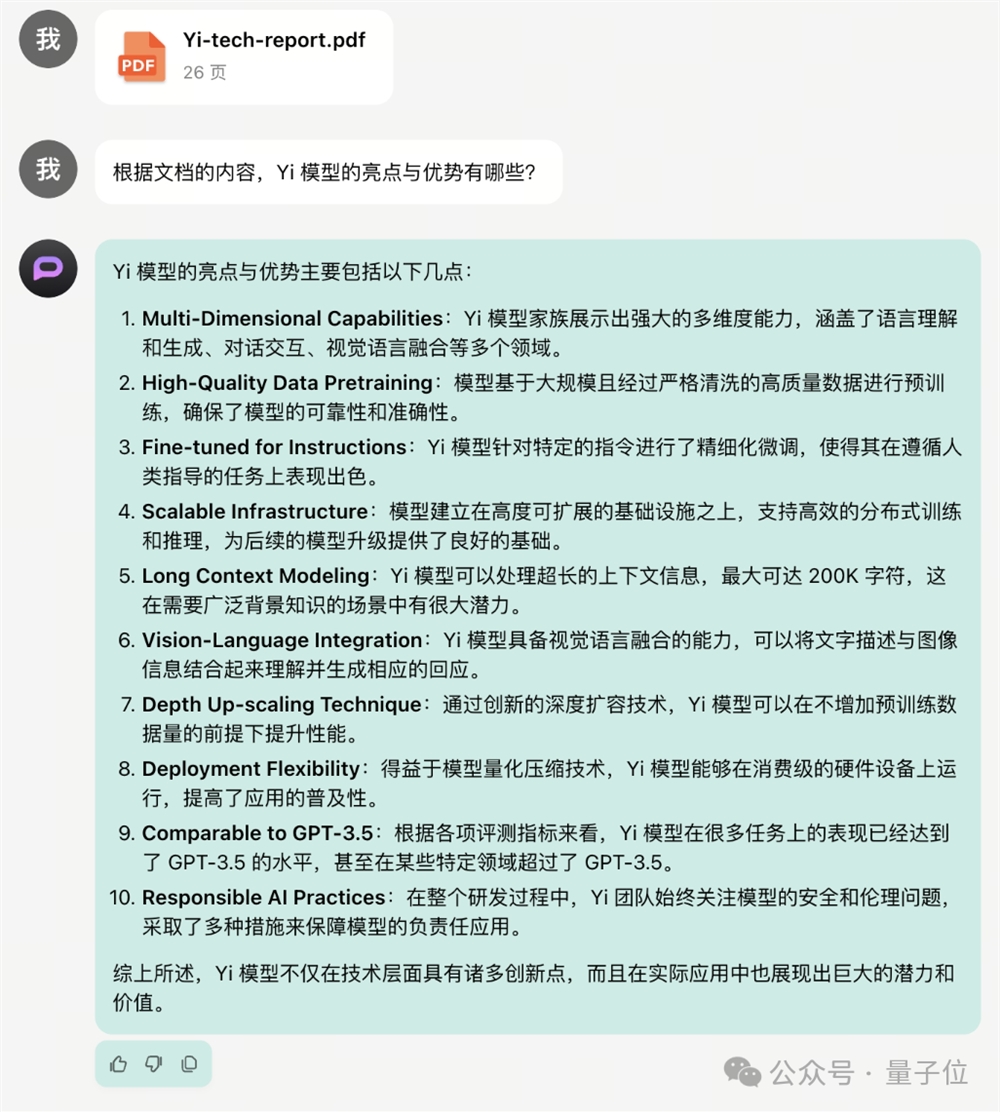
Yi-34B-Chat-0205:支持通用聊天、问答、对话、写作、翻译等功能。
Yi-34B-Chat-200K:200K上下文,多文档阅读理解、超长知识库构建小能手。
Yi-VL-Plus:多模态模型,支持文本、视觉多模态输入,中文图表体验超过GPT-4V。
去年11月,零一万物就正式开源发布了首款预训练大模型Yi-34B,当时的模型已经能处理200K上下文窗口,约等同于20万字文本。这次开放API平台,在Yi-34B的基础上,有什么新亮点?
要说有什么独特之处,我愿以五个“更”来概括。
分别是覆盖更大的参数量、更强的多模态、更专业的代码/数学推理模型、更快的推理速度、更低的推理成本。
并且!
Yi大模型API开放平台兼容OpenAI的API,可以随心快速丝滑切换。
更多详情,一起来看——
200K上下文窗口 多模态能力
此次API开放,最亮眼的地方一共有两点。
首先是200K的超长上下文窗口,可以一口气处理约30万个中英文字符,相对于读完整本《哈利·波特与魔法石》小说。
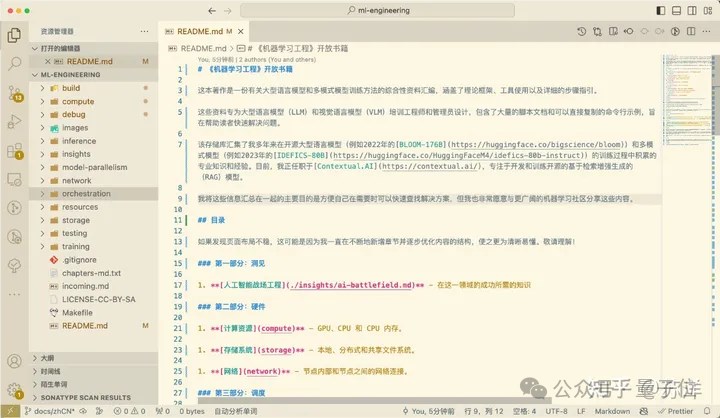
在大海捞针测试中,Yi-34B-Chat-200K取得了几乎全绿的成绩,准确率高达99.8%。
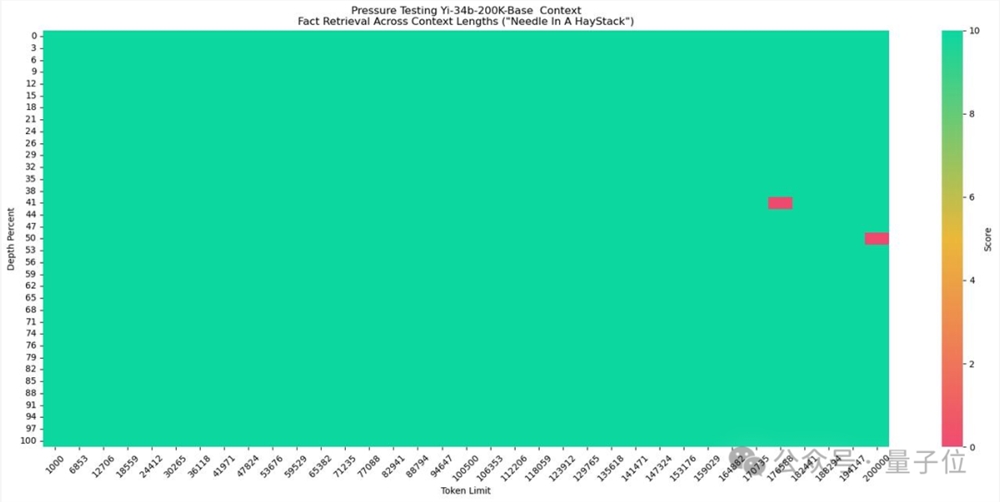
实际测试中,篇幅近两百页、总字数19万的《三体》第一部,Yi很快就能读完并给出总结。

而且细节关注到位,能从故事中提取出主要角色信息和他们的事迹,然后直接用表格的形式呈现在我们面前。
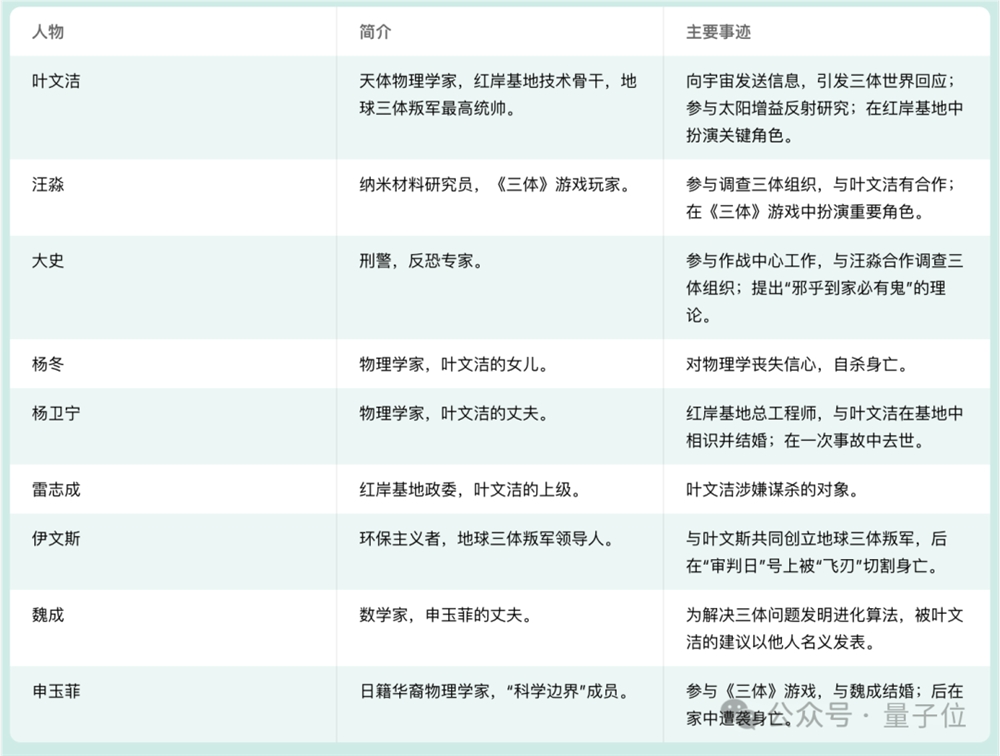
我们又补充追问了十个细节问题,答案分散在整部小说的各个位置,结果Yi全部答对。

另一大亮点,是Yi-VL-Plus强大的多模态能力。
多模态版本中,在保持LLM通用知识、推理等能力的前提下,图片内中文、符号识别能力大幅增强,体验超过了GPT-4V。
而且图片输入分辨率也提高到了1024×1024分辨率,并专门针对图表、截屏等生产力场景进行了优化。
比如下面这张图来自一篇文献综述,列举了课题相关论文中被引量最高的10篇。

Yi-VL-Plus准确地找到了目标文献,并准确识别出了文章标题,遇到“嗪”这种不常见的专业文字也没掉链子。
再看看GPT-4V这边,则是主打一个已读乱回,给出的文章标题不知道来自何处。

而除了识读图表和文字,Yi-VL-Plus还支持学习专业知识并立即用于图像的解读。
比如早期体验过的开发者教给模型一些心理学知识后,Yi-VL-Plus就能根据孩子的铅笔画展开一些基本的分析。
并且,模型给出的分析获得了专业人士的认可,给出了“较准确”的评价。
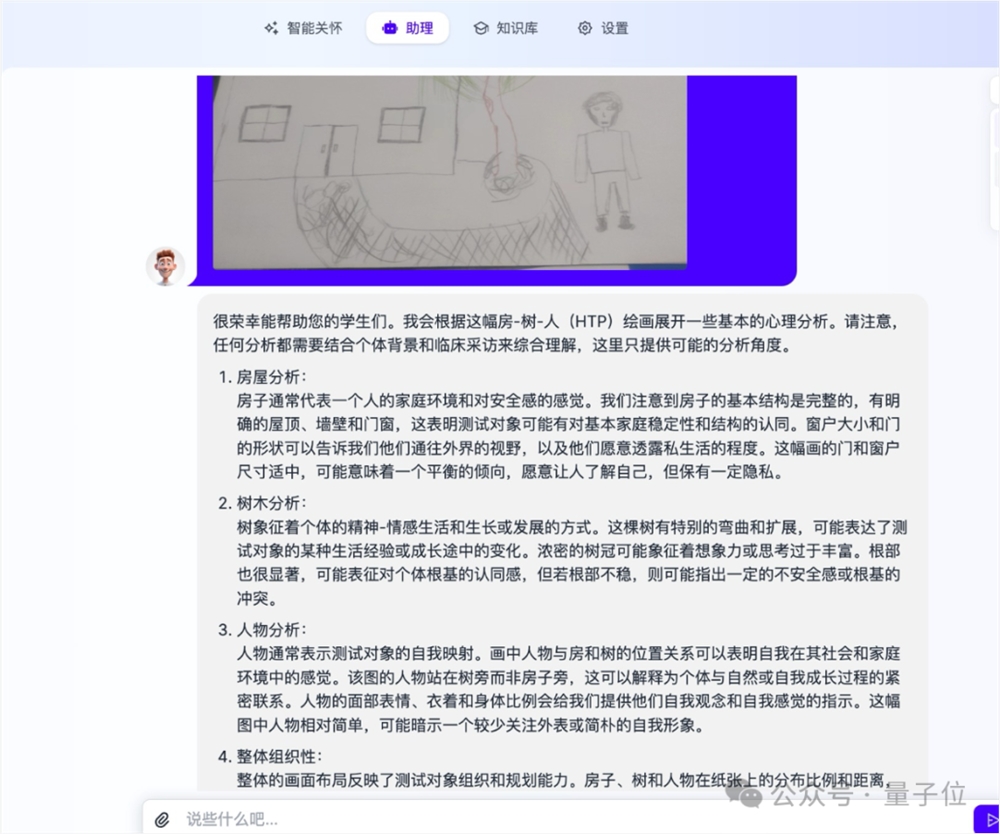
△开发者星云爱店CTO大董提供的测试资料,文图数据均脱敏
总之,凭借强大的长文本和多模态处理能力,无论是在to B还是to C场景,Yi都能构建出高效的大模型应用。
举个例子🌰,在to C场景中,可以用基础或多模态版本构建智能对话助手,进行深层次的对话问答。
而在B端,可以把Yi整合到现有产品,搭建出Copilot类的应用,抑或是利用超长文本能力建立知识库,打造出客服等特定场景的智能助手。
在前期的开发者邀测中,拥有阿里、美团等多家大厂工作经历的知乎大佬@苏洋就利用Yi的API搭建出了一个翻译器应用。

据作者本人介绍,他是看到GitHub上的一份开源的机器学习书籍之后萌生了翻译的想法,然后开始搭建这个应用的。
而之所以选择Yi作为承担这一工作的大模型,就是看中了它超出的上下文窗口,能够将作者每一章的全文都扔到模型里,而不用切分章节或做一些递归式的章节摘要等麻烦事。
另一方面,Yi和OpenAI的兼容性,也让作者直接利用LLM平台的OpenAI兼容API模块,就快速完成了模型的接入。
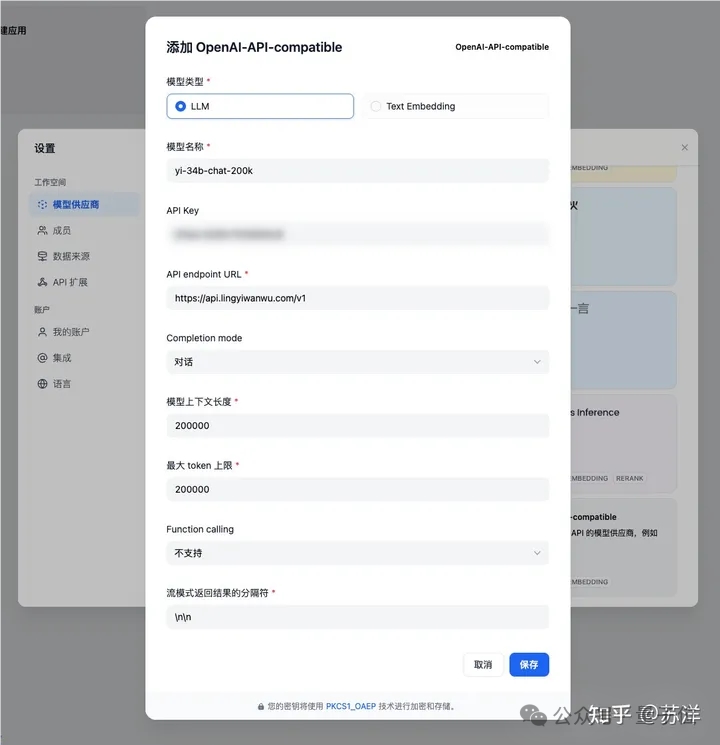
接入完模型之后就是几乎可以一键完成的模型搭建了,这里需要做的只是点选应用的类型,然后起个名字,并适当调节一些参数。
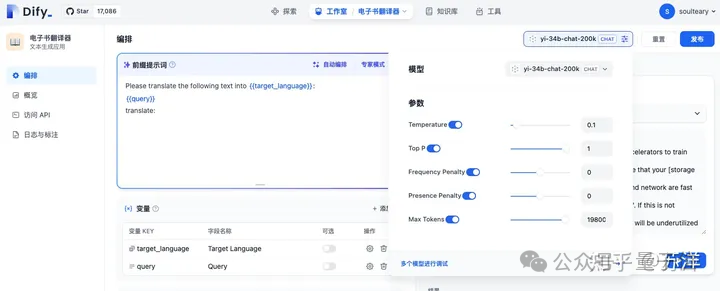
在此基础之上,作者又用golang对模型调用程序进行了编译,进一步提升了整个流程的自动化程度。
最终,一个全自动的翻译工具就大功告成了。
如果不看最后的进阶部分,利用Yi的API快速构建一款AI应用,简直不要太简单!
而除了这些应用上肉眼可见的优势,Yi系列API在技术层面的亮点同样可圈可点。
丝滑切换OpenAI API
在Yi优异表现的背后,无论是API还是模型本身,都必然有强大的技术作为支撑——在技术上,Yi有哪些特色?
首先,Yi与OpenAI API完全兼容。
这意味着开发者只需修改少量代码,就能完成从OpenAI到Yi的平滑迁移,实现了替换成本的最小化。
同时,为了提升API性能,零一万物在API侧进行了专门的推理优化。不仅推理速度更快,用户体验的流畅性和响应速度也都相应提高。
而针对模型自身的其他亮点,我们充分利用了Yi的长文本分析能力,从它的技术报告中进行了提炼。
当然,除了专门针对API做的优化之外,基础模型的能力同样不可或缺。
为了实现模型能力的提升,研究团队从保证训练数据质量、在tokenization中运用独特设计、微调阶段积累经验等多个角度进行了攻关,增强了模型的优势并在API段充分发挥。
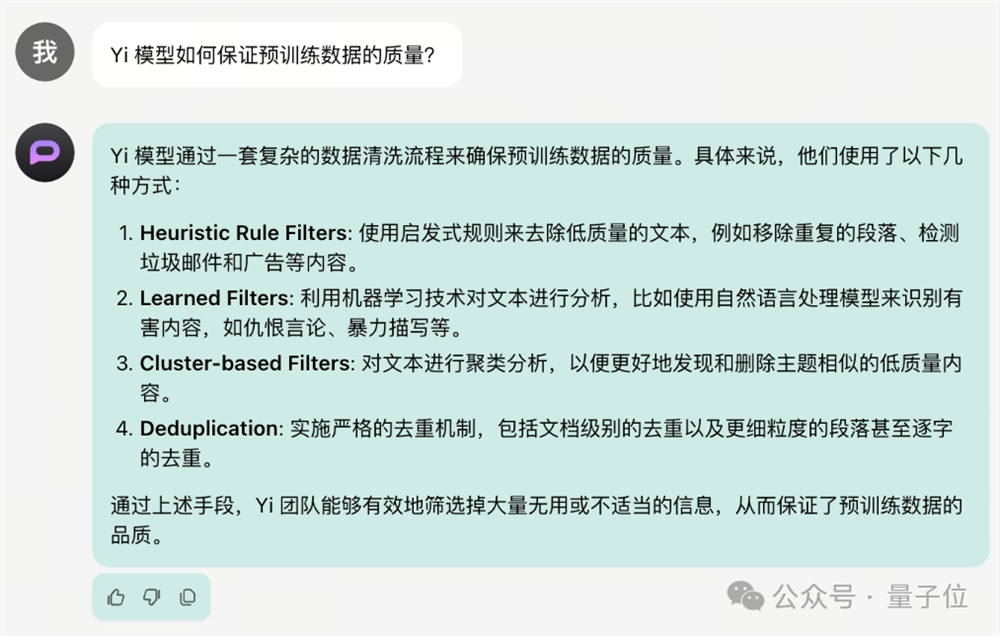
比如从训练阶段开始,研究团队就对数据进行了精心挑选,引入了启发式规则去除低质量文本,并利用机器学习方式识别有害内容。
同时研发人员还对训练数据中的文本进行聚类分析,并实施严格的去重机制,最大程度保证训练数据的质量。
而tokenization阶段,同样体现着研发人员的独到设计。
Yi使用字节对编码进行分词和词汇表的构建,减少了词汇表的大小并提高了编码效率。
同时最大程度保留原始符号,避免变换过程中造成的信息丢失。
针对数字,Yi还采用了拆分成单个token的方式来提高模型理解力;甚至对于特殊和无法识别的字符,也有专门的应对策略。

到了微调环节,Yi从技术报告总结出的关键经验就更多了。
比如“数据质量高于数量”的重要思想,从训练阶段开始就贯穿始终。
此外还有迭代过程、标签系统、结构化格式等诸多策略,这里就不再一一赘述了。

食用指南
看到这里,旁友们应该对Yi API的能力已经有一定了解了。
那么,Yi大模型API到底该如何食用?
此前,Yi大模型API已经在小范围开放内测。
“为了邀请更多的开发者并肩作战”,今天起,Yi大模型API名额开启了限量开放。
而且新用户还赠送60元(千万token)。
谁看了不说一句真香呢??!指路这篇文章的评论区置顶,可获得申请直通车连接~
开放API平台后,零一万物下一步会又什么新动作?
零一万物技术副总裁及模型训练AI Alignment、开放平台负责人俞涛对此做出了答复,称近期将会为开发者提供更多更强模型和AI开发框架。
未来计划具体围绕以下三个方面展开:
第一,支持更快的推理速度,显著降低推理成本。
第二,突破更长的上下文,目标由目前的20万tokens拓展到100万tokens。
第三,基于模型具备的超长上下文能力,构建向量数据库、RAG、Agent架构在内的全新开发者AI框架。
看来,零一万物的下一步棋,就是推理更快、窗口更长,同时提供更加丰富和灵活的开发工具,以适应不同开发者需求下的多样化应用场景。
具体推出的节奏,零一万物此次没有透露。但是——
三款模型的API,大家可以用起来了!先到先得,记得在评论区找到申请地址哟~
—完—
世界上第一个人工智能DJ亮相波特兰广播电台
据外媒报道,世界首个由人工智能驱动的电台DJ于六月在波特兰的一家电台亮相。据了解,波特兰一家名为Live95.5的电台让模仿了该电台的中午主持人AshleyElzinga的角色,创建了虚拟AIDJ的身份和声音。合成的声音与真人相似,AIDJ自我介绍为AIAshley,以让听众知道是由人工智能发声。AIAshley每天上午10点至下午3点会向听众广播。站长网2023-07-04 00:15:450000WPS官方宣布将正式关闭第三方商业广告
WPS官方于2023年12月20日发布公告,宣布将正式关闭第三方商业广告。该公告指出,WPS一直在减少广告,并在去年下定决心立下了“2023年底正式关闭第三方商业广告”的目标。公告还表示,WPS深知今天取得的每一份成绩,都离不开用户的支持和陪伴。WPS将秉持“简单创作、轻松表达、实现价值的连接”的公司使命,为广大用户提供优质的产品服务体验。站长网2023-12-20 10:04:250000StreamingLLM:让AI模型无限期平稳运行的一种方法
要点:1.Meta、麻省理工学院(MIT)和卡内基梅隆大学(CMU)的研究人员介绍了一项名为StreamingLLM的技术,旨在解决大型语言模型(LLMs)在长时间对话中性能下降的问题。2.StreamingLLM利用“attentionsinks”(关注点汇)的概念,通过在对话的不同阶段重新引入初始标记,使LLMs能够在无限长度的文本上保持高性能。站长网2023-10-08 09:42:270000云闪付没大面积推广原因揭秘
云闪付作为一款智能支付产品,自2017年推出以来一直备受关注。相较于其他支付方式,它有着更加便捷快速的使用体验和更加安全可靠的支付方式。但是,尽管云闪付在一些地区和领域内得到了广泛的应用,但是在大面积推广方面仍然存在一些困难。站长网2023-05-24 06:17:400000特斯拉FSD 12 Alpha即将上线 马斯克:激动人心
快科技7月28日消息,近日,特斯拉CEO埃隆马斯克在其个人社交账号上表示:他正在FSD12Alpha版本进行测试,并称其激动人心”。据悉,FSD是目前特斯拉提供的测试版最高水平的自动驾驶系统。该系统不再依赖于传统的高精地图和导航数据,而是完全依靠车载摄像头和神经网络来识别道路和交通情况,并做出相应的决策。站长网2023-07-29 09:45:150000