被误解的「中文版Sora」背后,字节跳动有哪些技术?
2024开年,OpenAI 就在生成式 AI 领域扔下了重磅炸弹:Sora。
这几年,视频生成领域的技术迭代持续加速,很多科技公司也公布了相关技术进展和落地成果。在此之前,Pika、Runway 都曾推出过类似产品,但 Sora 放出的 Demo,显然以一己之力抬高了视频生成领域的标准。
在今后的这场竞争中,哪家公司将率先打造出超越 Sora 的产品,仍是未知数。
国内这边,目光聚集于一众科技大厂。
此前有消息称,字节跳动在 Sora 发布之前就研发出了一款名为 Boximator 的视频生成模型。
Boximator 提供了一种能够精确控制视频中物体的生成方法。用户无需编写复杂的文本提示,可以直接在参考图像中通过在物体周围画方框来选择目标,然后添加一些方框和线条来定义目标的结束位置或跨帧的整个运动路径,如下图所示:

对此,字节跳动保持了低调的态度:相关人士回复媒体,Boximator 是视频生成领域控制对象运动的技术方法研究项目。目前还无法作为完善的产品落地,距离国外领先的视频生成模型在画面质量、保真率、视频时长等方面还有很大差距。
在对应的技术论文介绍(https://arxiv.org/abs/2402.01566)中,我们也能看到,Boximator 是以插件的形式运行,可与现有的视频生成模型无缝集成,在保持视频质量的同时,增加运动控制功能。
视频生成背后的技术涉及多个细分方向,与图像 / 视频理解、图像生成、超分辨率等技术都有关系。深挖之后,我们发现在众多分支领域,字节跳动已公开发表了一些研究成果。
这篇文章将介绍来自字节跳动智能创作团队的9项研究,涉及文生图、文生视频、图生视频、视频理解等多项最新成果。我们不妨从这些研究中,追踪探索视觉生成类模型的技术进展。
关于视频生成,字节有哪些成果?
在今年1月上旬,字节跳动就发布过一个视频生成模型 MagicVideo-V2,一度引发社区热议。

论文标题:MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
论文链接:https://arxiv.org/abs/2401.04468
项目地址:https://magicvideov2.github.io/
MagicVideo-V2的创新在于将文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块集成到端到端视频生成 pipeline 中。得益于这一架构设计,MagicVideo-V2在「审美」上能够保持着稳定的高水平表现,不仅生成美观的高分辨率视频,还兼具比较好的保真度和流畅度。
具体而言,研究者首先使用 T2I 模块创建一个1024×1024的图像,封装所描述的场景。随后,I2V 模块对该静态图像进行动画处理,生成600×600×32的帧序列,之前的潜在噪声确保了初始帧的连续性。V2V 模块将这些帧增强到1048×1048分辨率,同时完善视频内容。最后,插值模块将序列扩展到94个帧,得到1048×1048分辨率的视频,所生成视频具有较高的美学质量和时间平滑性。
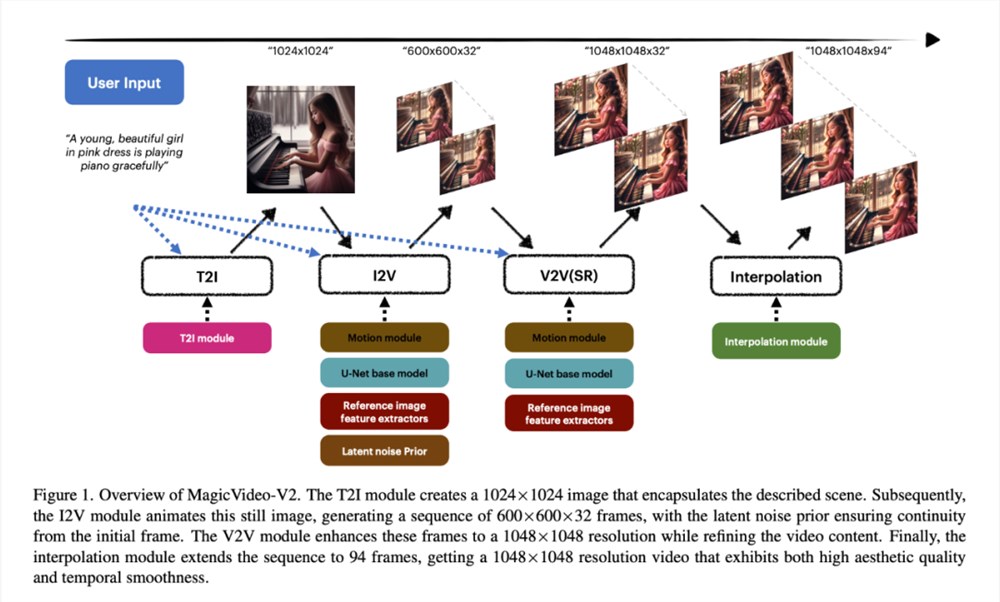
研究者进行的大规模用户评估证明:MagicVideo-V2比一些知名的 T2V 方法更受青睐(绿色、灰色和粉色条分别代表 MagicVideo-V2被评为较好、相当或较差)。

高质量视频生成背后
统一视觉和语言学习的研究范式
从 MagicVideo-V2的论文中,我们可以看出,视频生成技术的进展,离不开文生图、图生视频等 AIGC 技术的铺路。而生成高审美水准内容的基础在于理解,特别是模型对于视觉和语言两种模态学习、融合能力的进步。
近年来,大语言模型的可扩展性和通用能力,催生出了统一视觉和语言学习的研究范式。为了跨越「视觉」和「语言」两种模态之间的天然鸿沟,研究者们将预训练好的大语言模型和视觉模型的表征连接起来,提取跨模态特性,完成如视觉问题解答、图像字幕、视觉知识推理和对话等任务。
在这些方向上,字节跳动也有相关探索。
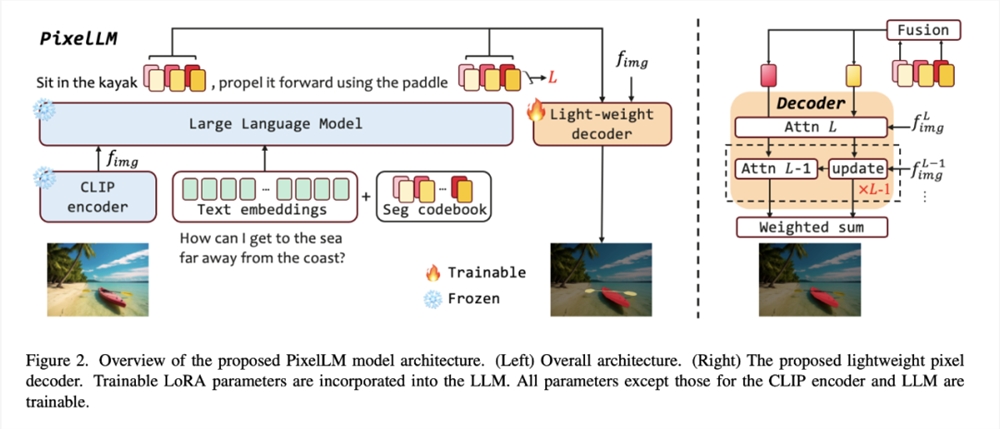
比如,针对开放世界视觉任务中的多目标推理分割挑战,字节跳动联合北京交通大学、北京科技大学的研究者提出了高效像素级推理大模型 PixelLM,并将其开源。

论文标题:PixelLM:Pixel Reasoning with Large Multimodal Model
论文链接:https://arxiv.org/pdf/2312.02228.pdf
项目地址:https://pixellm.github.io/
PixelLM 能够熟练地处理具有任意数量的开放集目标和不同推理复杂性的任务,下图展示了 PixelLM 在各种分割任务中生成高质量目标掩码的能力。

PixelLM 的核心是一个新颖的像素解码器和一个分割 codebook:codebook 包含了可学习的 token,这些 token 编码了与不同视觉尺度目标参考相关的上下文和知识,像素解码器根据 codebook token 的隐藏嵌入和图像特征生成目标掩码。在保持 LMM 基本结构的同时,PixelLM 可以在没有额外的、昂贵的视觉分割模型的情况下生成高质量的掩码,从而提高了效率和向不同应用程序的可迁移性。
值得关注的是,研究者构建了一个全面的多目标推理分割数据集 MUSE。他们从 LVIS 数据集中选取了共910k 个高质量实例分割掩码以及基于图像内容的详细文本描述,利用这些构建了246k 个问题 - 答案对。
相比于图像,如果涉及视频内容,模型遭遇的挑战难度就又增加了不少。因为视频不仅包含丰富多变的视觉信息,还涉及时间序列的动态变化。
现有的多模态大模型在处理视频内容时,通常将视频帧转化为一系列的视觉 token,并与语言 token 结合以生成文本。但随着生成文本长度的增加,视频内容的影响会逐渐减弱,导致生成的文本越来越多地偏离原视频内容,产生所谓的「幻觉」。
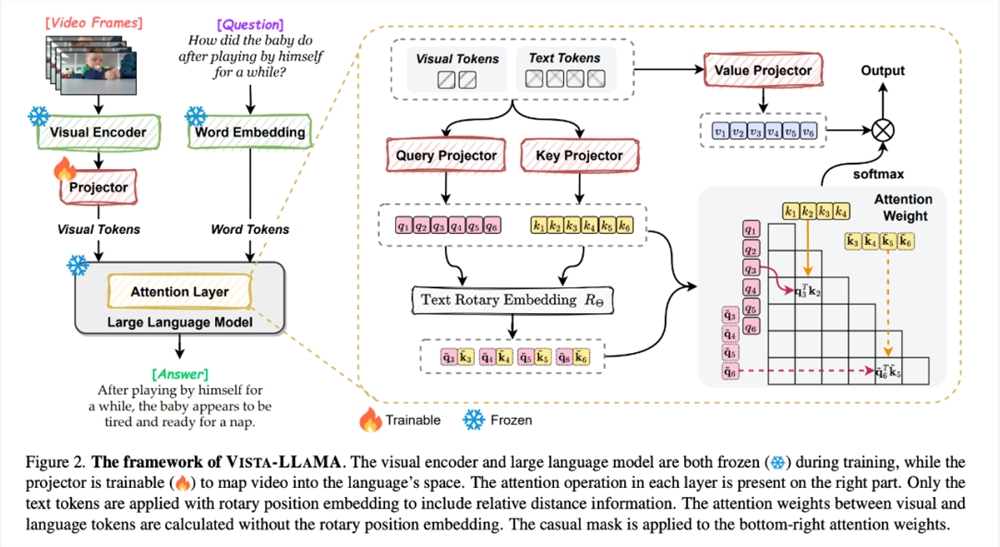
面对这一问题,字节跳动联合浙江大学提出了专门针对视频内容的复杂性设计的多模态大模型 Vista-LLaMA。

论文标题:Vista-LLaMA:Reliable Video Narrator via Equal Distance to Visual Tokens
论文链接:https://arxiv.org/pdf/2312.08870.pdf
项目地址:https://jinxxian.github.io/Vista-LLaMA/
Vista-LLaMA 采用了一种改良的注意力机制 —— 视觉等距离 token 注意力(EDVT),在处理视觉与文本 token 时去除了传统的相对位置编码,同时保留了文本与文本之间的相对位置编码。这种方法大幅提高了语言模型对视频内容的理解深度和准确性。
特别是,Vista-LLaMA 引入的序列化视觉投影器为视频中的时间序列分析问题提供了新的视角,它通过线性投影层编码视觉 token 的时间上下文,增强了模型对视频动态变化的理解能力。
在最近被 ICLR2024接收的一项研究中,字节跳动的研究者还探讨了一种提升模型对视频内容学习能力的预训练方法。
由于视频 - 文本训练语料的规模和质量有限,大多数视觉语言基础模型都采用图像 - 文本数据集进行预训练,并主要关注视觉语义表征建模,而忽略了时间语义表征和相关性。
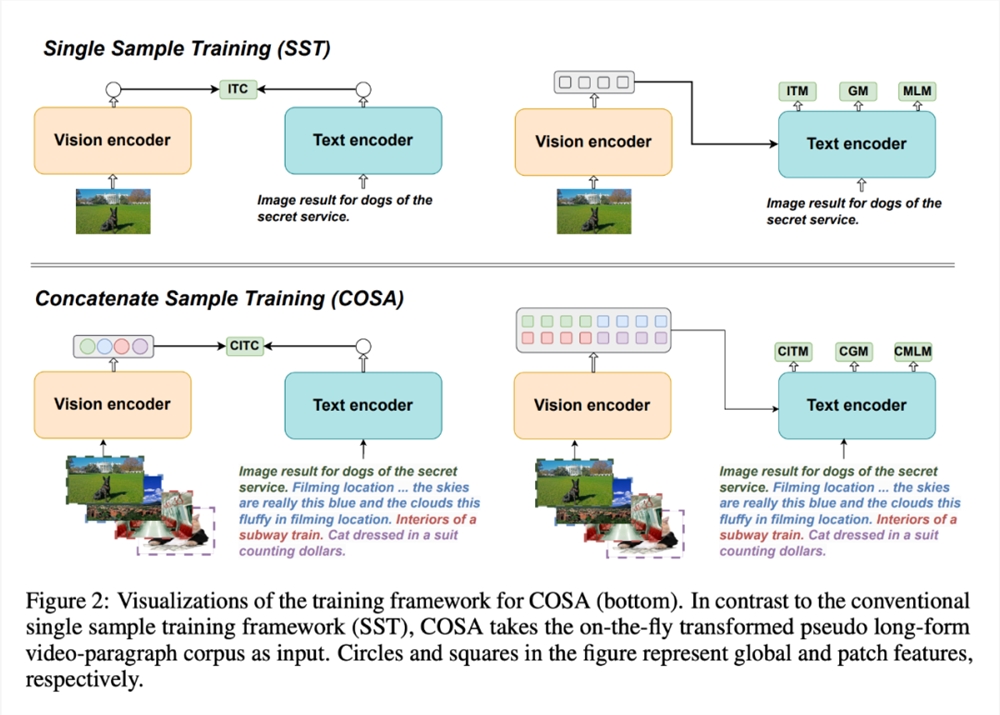
为了解决这个问题,他们提出了 COSA,一种串联样本预训练视觉语言基础模型。

论文标题:COSA: Concatenated Sample Pretrained Vision-Language Foundation Model
论文链接:https://arxiv.org/pdf/2306.09085.pdf
项目主页:https://github.com/TXH-mercury/COSA
COSA 仅使用图像 - 文本语料库对视觉内容和事件级时间线索进行联合建模。研究者将多个图像 - 文本对按顺序串联起来,作为预训练的输入。这种转换能有效地将现有的图像 - 文本语料库转换成伪长格式视频 - 段落语料库,从而实现更丰富的场景转换和明确的事件 - 描述对应关系。实验证明,COSA 能够持续提高各种下游任务的性能,包括长 / 短视频 - 文本任务和图像 - 文本任务(如检索、字幕和问题解答)。

从图像到视频
被重新认识的「扩散模型」
在视觉 - 语言模型之外,扩散模型同样是大部分视频生成模型采用的技术。
通过在大量图像 - 文本配对数据集上进行严格训练,扩散模型能够完全根据文本信息生成细节丰富的图像。除了图片生成,扩散模型还可用于音频生成、时间序列生成、3D 点云生成等等。
比如在一些短视频应用中,用户只需要提供一张图片,就能生成一段以假乱真的动作视频。
数百年来保持神秘微笑的蒙娜丽莎,都能马上跑起来:

这项有趣应用背后的技术,是新加坡国立大学和字节跳动的研究者联合推出的「MagicAnimate」。
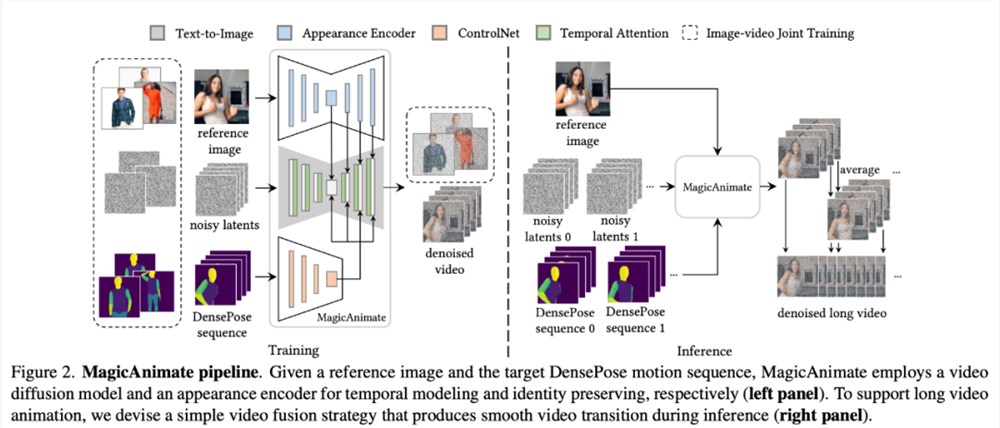
MagicAnimate 是一个基于扩散的人类图像动画框架,在根据特定的运动序列生成视频的任务中,能够很好地保证整个动画的时间一致性并提升动画保真度。而且,MagicAnimate 项目是开源的。

论文标题:MagicAnimate:Temporally Consistent Human Image Animation using Diffusion Model
论文链接:https://arxiv.org/pdf/2311.16498.pdf
项目地址:https://showlab.github.io/magicanimate/
为了解决生成动画普遍存在的「闪烁」问题,研究者通过将时间注意力(temporal attention)块合并到扩散主干网络中,来构建用于时间建模的视频扩散模型。
MagicAnimate 将整个视频分解为重叠的片段,并简单地对重叠帧的预测进行平均。最后,研究者还引入图像 - 视频联合训练策略,以进一步增强参考图像保留能力和单帧保真度。虽然仅接受了真实人类数据的训练,MagicAnimate 却展现出了泛化到各种应用场景的能力,包括对未见过的领域数据进行动画处理、与文本 - 图像扩散模型的集成以及多人动画等。
另一项基于扩散模型思想的研究「DREAM-Talk」,则解决了从单张肖像图像生成会说话的情绪化人脸的任务。

论文标题:DREAM-Talk:Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation
论文链接:https://arxiv.org/pdf/2312.13578.pdf
项目地址:https://dreamtalkemo.github.io/
我们知道,在这项任务中,很难同时实现富有表现力的情感对话和准确的唇语同步,通常为了保证唇语同步的准确性,表现力往往会大打折扣。
「DREAM-Talk」是一个基于扩散的音频驱动框架,分为两个阶段:首先,研究者提出了一个新颖的扩散模块 EmoDiff,可根据音频和参考情绪风格生成多种高度动态的情绪表情和头部姿势。鉴于唇部动作与音频之间的强相关性,研究者随后利用音频特征和情感风格对动态进行了改进,从而提高了唇部同步的准确性,此外还部署了一个视频到视频渲染模块,实现了将表情和唇部动作转移到任意肖像。
从效果上看,DREAM-Talk 在表现力、唇部同步准确性和感知质量方面的确不错。
但不管是图像生成还是视频生成,当前基于扩散模型路线的研究都还有一些基础挑战需要解决。
比如很多人关心生成内容的质量问题(对应 SAG、DREAM-Talk),这可能与扩散模型的生成过程中的一些步骤有关,比如引导采样。
扩散模型中的引导采样大致可分为两类:需要训练的和无需训练的。免训练引导采样是利用现成的预训练网络(如美学评估模型)来引导生成过程,旨在以更少的步骤和更高的精度从预训练的模型中获取知识。当前的训练无指导采样算法基于对干净图像的一步估计来获得指导能量函数。然而,由于预训练网络是针对干净图像进行训练的,因此干净图像的一步估计过程可能不准确,尤其是在扩散模型的早期阶段,导致早期时间步骤的指导不准确。
针对该问题,字节跳动和新加坡国立大学的研究者共同提出了 Symplectic Adjoint Guidance (SAG)。

论文标题:Towards Accurate Guided Diffusion Sampling through Symplectic Adjoint Method
论文链接:https://arxiv.org/pdf/2312.12030.pdf
SAG 通过两个内阶段计算梯度引导:首先,SAG 通过 n 个函数调用估计干净图像,其中 n 作为一个灵活的参数,可以根据特定的图像质量要求进行调整。其次,SAG 使用对称偶方法精确高效地获得关于内存需求的梯度。这种方法可支持各种图像和视频生成任务,包括风格引导图像生成、美学改进和视频风格化,并有效提升了生成内容的质量。
最近入选 ICLR2024的一篇论文,则着重讨论了「扩散概率模型梯度反向传播的临界灵敏度方法」。

论文标题:Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models
论文链接:https://arxiv.org/pdf/2307.10711.pdf
由于扩散概率模型的采样过程涉及对去噪 U-Net 的递归调用,因此 naïve 梯度反向传播需要存储所有迭代的中间状态,从而导致极高的内存消耗。
在这篇论文中,研究者提出的 AdjointDPM 首先通过求解相应的概率流 ODE 从扩散模型中生成新样本。然后,通过求解另一个增强的 ODE,使用邻接灵敏度方法反向传播模型参数(包括调节信号、网络权重和初始噪声)损失的梯度。为了减少前向生成和梯度反向传播过程中的数值误差,研究者使用指数积分进一步将概率流 ODE 和增强型 ODE 重新参数化为简单的非刚性 ODE。
研究者指出,AdjointDPM 在三个任务中极具价值:将视觉效果转换为识别文本嵌入、针对特定类型的风格化对扩散概率模型进行微调,以及优化初始噪声以生成用于安全审计的对抗样本,以减少优化工作中的成本。
对于视觉类的感知任务,采用文本到图像的扩散模型作为特征提取器的方法也受到越来越多的关注。在这一方向上,字节跳动的研究者在论文中提出了一种简单而有效的方案。

论文标题;Harnessing Diffusion Models for Visual Perception with Meta Prompts
论文链接:https://arxiv.org/pdf/2312.14733.pdf
这篇论文的核心创新是在预训练的扩散模型中引入可学习的嵌入(元提示)以提取感知特征,不依赖额外的多模态模型来生成图像标题,也不使用数据集中的类别标签。
元提示有两方面的作用:首先,作为 T2I 模型中文本嵌入的直接替代物,它可以在特征提取过程中激活与任务相关的特征;其次,它将用于重新排列提取的特征,以确保模型专注于与手头任务最相关的特征。此外,研究者还设计了一种循环细化训练策略,充分利用扩散模型的特性,从而获得更强的视觉特征。
「中文版 Sora」诞生之前
还有多远的路要走?
在这几篇新论文中,我们已经了解到字节跳动这样的国内科技公司,在视频生成技术上的一系列积极的探索。
但是与 Sora 相比,无论是字节跳动,还是 AI 视频生成领域的一众明星公司,都存在肉眼可见的差距。Sora 的优势建立在对 Scaling Law 的信仰和突破性的技术创新上:通过 patchs 统一视频数据,依托 Diffusion Transformer 等技术架构和 DALL・E3的语义理解能力,真正做到了「遥遥领先」。
从2022年文生图的大爆发,到2024年 Sora 的横空出世,人工智能领域的技术迭代速度,已经超过了大家的想象。2024年,相信这一领域还会出现更多的「爆款」。
字节显然也在加紧投入技术研发。近期,谷歌 VideoPoet 项目负责人蒋路,开源多模态大模型 LLaVA 团队成员之一、前微软研究院首席研究员 Chunyuan Li 均被曝出已加入字节跳动智能创作团队。该团队还在大力招聘,官网上已放出多个大模型算法相关岗位。
不仅仅是字节,BAT 等老牌巨头也放出众多令人瞩目的视频生成研究成果,一众大模型创业公司更是极具冲劲。文生视频技术又将出现哪些新的突破?我们拭目以待。
马斯克的新玩具“星舰火炬”结束预售 预计11月交付
马斯克的SpaceX公司推出的一款以Starship星舰为外形设计的打火机,引起了广泛的关注。这款打火机售价为175美元(约合人民币1254元),预售已经结束,目前正在加紧生产,将从11月初开始交付。站长网2023-07-18 18:29:350000妇女节特辑丨每一款字体都有“她”力量 字体超市100%正版可商用
恰逢妇女节将至,如何选择一款适合妇女节海报的字体,想必这也是大多数各设计师苦恼的问题。一款好的妇女节字体不仅要能传达出节日的氛围,还要能够反映出女性的特点和力量。为此,字体超市为大家精选一波优雅大方且有力的字体,欢迎大家一起来围观!上首松羽体站长网2024-02-27 10:28:220000何小鹏回应小米汽车致敬:欢迎加入 一定大卖
小米汽车即将举办首场技术发布会,这场发布会的主讲人将是小米创始人雷军。据称,这场发布会的时间长度很可能会达到3个小时。在发布会之前,小米汽车和雷军本人都已经在微博上进行了预热,表达了对中国新能源汽车行业先行者的敬意。0000小米SU7计划5月初推送首次OTA:无线CarPlay将上线!iPhone用户最优选
快科技4月25日消息,雷军在今天上午的小米汽车北京车展发布会上透露,小米SU7计划5月进行发布后的首次OTA1.1。届时,将上线大家期待已久的无线CarPlay功能、端到端代客泊车等智驾体验。无线CarPlay对于iPhone用户将会是绝杀”功能,可以让iPhone用户获得更好的车机互联体验,而且是完全无感的操作。除了无线CarPlay之外,SU7还支持AirPlay、iPad后排扩展屏等。站长网2024-04-25 21:41:040000FF:将于本周末举行FF 91 2.0 Futurist Alliance首个交车仪式
FF(FaradayFuture)宣布,将于本周末在“PrivateCollectionMotors”总部举行FF首个交车仪式,并于8月15日播放交车仪式实况,为开发者共创节拉开序幕。未来公司将为其他首批购车用户举办个性化的交车仪式。站长网2023-08-10 15:46:000000












