VSP-LLM:可通过观察视频中人的嘴型来识别唇语
VSP-LLM是一种通过观察视频中人的嘴型来理解和翻译说话内容的技术,也就是识别唇语。该技术能够将视频中的唇动转化为文本(视觉语音识别),并将这些唇动直接翻译成目标语言的文本(视觉语音翻译)。不仅如此,VSP-LLM还能智能识别和去除视频中不必要的重复信息,使处理过程更加快速和准确。
VSP-LLM的开发基于AV-HuBERT模型代码,后者是Facebook开发的一个自监督的视觉语音模型。AV-HuBERT能够从视频中学习语音表示,尤其是从人的唇动中识别语音信息。因此,VSP-LLM利用了AV-HuBERT在视觉语音识别方面的先进技术,作为其视觉语音处理组件的基础。

项目地址:https://top.aibase.com/tool/vsp-llm
该技术结合了视觉语音处理和大语言模型(LLMs)的新型框架,旨在利用LLMs的上下文理解能力来提高视觉语音识别和翻译的准确性和效率。
VSP-LLM的工作原理包括自监督学习、去除输入帧中的冗余信息、利用大语言模型进行上下文建模、多任务执行和低秩适配器(LoRA)。
首先,通过自监督学习的方式,VSP-LLM训练一个视觉语音模型来理解和识别视频中提取的唇动作。自监督学习使得模型能够在没有明确标注的数据情况下,通过自我生成的反馈来学习和提取有用的信息。
其次,为了提高处理效率,VSP-LLM设计了一种去重方法,通过识别视觉语音单元减少输入帧中的冗余信息,进而减少模型需要处理的数据量。
然后,通过将自监督视觉语音模型提取的信息映射到LLMs的输入空间中,VSP-LLM能够实现视觉到文本的映射,进而利用LLMs的上下文建模能力来理解和翻译视频中的唇动作。
此外,VSP-LLM能够执行多任务,包括将视频中的唇动作识别为具体文本(视觉语音识别)或直接翻译这些唇动作成目标语言的文本(视觉语音翻译)。
最后,为了进一步提升训练的计算效率,VSP-LLM采用了低秩适配器(LoRA)技术,这种优化训练过程的方法能够减少计算资源的需求。
小米13系列发布澎湃OS正式版内测升级:抖音更流畅 新增出行助手
快科技7月21日消息,日前,小米宣布小米13、小米13Pro、小米13Ultra发布最新澎湃OS正式版内测尝鲜升级。三款机型升级包版本如下:小米13:OS1.0.10.0.UMCCNXM小米13Pro:OS1.0.8.0.UMBCNXM小米13Ultra:OS1.0.12.0.UMACNXM上述机型正式版内测用户可点击设置-我的设备-系统版本进行OTA更新。站长网2024-07-21 14:12:070000可怕!安卓恶意软件曝光 50个品牌890万部手机被感染
【手机中国新闻】5月22日,手机中国从外媒了解到,全球有890万部安卓手机被一个名为柠檬集团(LemonGroup)的网络犯罪组织预先感染,成为他们进行恶意活动的工具。这些手机不仅会被用来窃取和出售短信、社交媒体和在线通讯账户,还会被用来显示不必要的广告和进行点击欺诈,给用户带来巨大的损失和麻烦。安卓站长网2023-05-24 14:45:340000英伟达发布2024财年第一财季财报 净利润同比增长26%
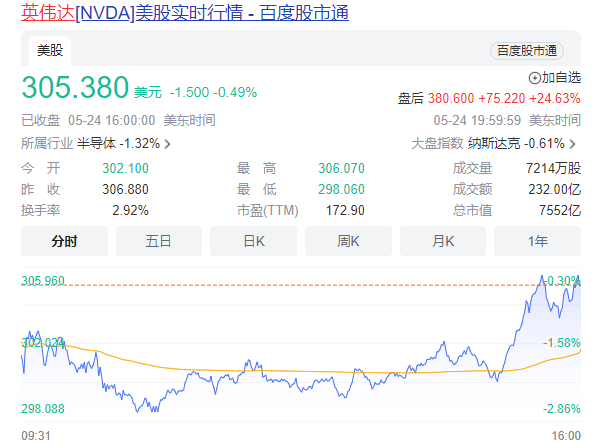
今日早间,英伟达发布2024财年第一财季财报称,第一财季营收为71.92亿美元,同比下降13%,环比增长19%。净利润为20.43亿美元,同比增长26%。环比增长44%。站长网2023-05-25 10:27:190000这么多年终于等来了!即日起12306试行上线选铺服务:自选上下铺
快科技6月10日消息,以往很多年,只有在代售点或线下窗口购买卧铺火车票才能选铺,12306购买卧铺票只能被系统自动分配。这让很多乘车人非常难受,只能被迫退票后,重新下单,而在节假日时间段很可能退票后就无票可买了。从网友反馈来看,很多年轻人比较偏爱上铺,因为上车就能与世隔绝”的休息了,而在下铺比较吵闹且会被别人坐上来,一般是腿脚不方便的老年人会比较偏爱。站长网2023-06-11 22:38:2600005分钟5000元,五一挤到天上了
“五一出行,怎么才能避开人山人海?”陈琳很早就开始琢磨。她最终决定,“飞到天上”躲一躲。但没想到,一连预约了几家高空跳伞基地,得到的回复都是,“对不起,没有位置了”。今年五一,不但地上挤,天上也开始挤了。从数千米的高空纵身一跃,经历几十秒的高速自由落体后,当伞包打开,就可以像鸟儿一样,在碧海蓝天间翱翔了……站长网2023-05-04 15:29:380000