Reddit通过与AI公司合作的数据授权收入达2. 03 亿美元
**划重点:**
1. 💰 Reddit在IPO招股书中透露,通过与AI公司签订数据授权协议,已实现合计2.03亿美元的收入。
2. 🤖 Reddit强调与AI供应商的关系,尤其是与OpenAI等公司的合作对其上市前景产生积极影响。
3. 🌐 Reddit数据对AI模型培训的重要性,以及AI公司如何通过授权协议获取这些数据,成为文章关注焦点。
Reddit公司在其拟议的首次公开募股(IPO)招股书中透露,通过与多家人工智能(AI)公司签订的数据授权协议,已实现合计2.03亿美元的收入。这些合同的期限为两到三年,其中预计在2024年底前将实现最低6,640万美元的收入。
在招股书中,Reddit特别强调了与AI模型培训公司的关系,这些公司使用Reddit上超过10亿篇帖子和超过160亿条评论的数据进行模型培训。尽管招股书未具体透露与哪些AI供应商签署了数据授权协议,但早些时候的报道提到一家“大型未透露的AI公司”可能是Google,其年度许可协议价值约为6000万美元。

图源备注:图片由AI生成,图片授权服务商Midjourney
OpenAI也被提及作为潜在的合作伙伴。OpenAI的首席执行官Sam Altman持有Reddit8.7%的股份,是第三大股东,曾担任过Reddit董事会成员。
Reddit数据之所以具有价值,是因为AI模型通过“学习”这些数据中的例子,可以生成文章、代码、电子邮件等。OpenAI等供应商从互联网上搜集数以亿计的这些例子用于模型训练。Reddit的数据包含大量的对话性数据和知识,对于训练和改进大型语言模型起到了关键作用。
在过去,Reddit并未对其数据进行人工智能培训目的的访问限制。然而,去年,Reddit改变了策略,认为其数据不应该免费提供给全球最大的公司。公司首席执行官Steve Huffman表示,他们的数据API能够提供对时事、电影、新闻、时尚等不断更新和动态主题的实时访问。
最近,随着聊天机器人(如OpenAI的ChatGPT和Google的Gemini)威胁到流量,从股票媒体库到新闻出版商等内容制作者越来越倾向于与AI供应商签订数据授权协议。这也是供应商主动追求许可协议的原因之一,因为他们面临着诉讼潮,指控他们在没有许可或支付的情况下对数据进行模型培训。最近,《纽约时报》指责OpenAI通过其作品有效地建立了新闻发布商的竞争对手,损害了其业务。
OpenAI已与图库Shutterstock以及出版商Axel Springer(Politico和Business Insider的所有者)达成协议,尽管这些许可协议金额相对较小,最高每年不超过500万美元。
Reddit通过数据授权实现的巨额收入凸显了数据在人工智能领域的关键作用,以及AI公司为获取高质量数据所付出的努力。这也进一步推动了AI公司与数据持有者之间的合作关系,为双方带来了可观的经济利益。
研究称:AI可能很快就能预测你是否能坚持减肥饮食计划
一项由澳大利亚国家科学机构CSIRO进行的世界首创研究发现,人工智能可能能够预测一个人何时会退出在线减肥计划。研究发现,通过使用“机器学习”方法,科学家们可以准确地预测“用户何时会放弃”他们的计划。该技术可能在澳大利亚肥胖率不断上升的背景下尤其有益。据统计,澳大利亚有67%的人超重或肥胖,其中有8%的疾病部分与肥胖有关。研究表明,机器学习在长期对抗肥胖方面可能具有巨大价值。站长网2023-07-21 16:46:420000开源鸿蒙又一里程碑!OpenHarmony 4.0正式发布:代码行数已破亿
快科技11月5日消息,第二届开放原子开源基金会OpenHarmony技术大会在北京圆满落幕,本次大会由OpenHarmony项目群技术指导委员会主办,由华为、润开鸿、九联开鸿、软通动力、深开鸿合作支持。开幕式上,开放原子开源基金会理事长孙文龙发表了致辞,宣布OpenHarmony4.0版本正式发布,并强调了OpenHarmony在推动千行百业数字化转型中的重要作用。站长网2023-11-05 09:42:2300006999元起卖爆!荣耀Magic V3系列打破近一年大折叠屏首销纪录
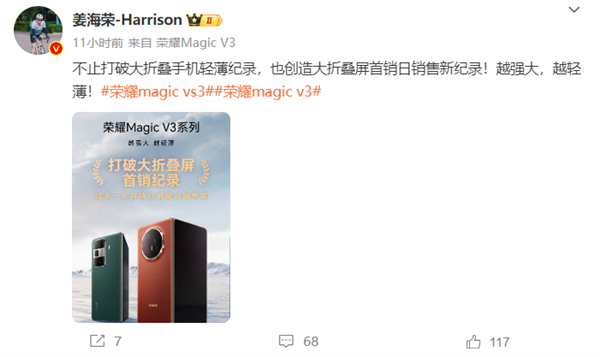
快科技7月21日消息,荣耀MagicV3、荣耀MagicVs3两款折叠屏旗舰于7月19日全渠道开售,售价6999元起。根据荣耀终端有限公司中国区CMO姜海荣发布的首销战报,荣耀MagicV3系列打破了过去一年大折叠屏首销日销量及销售额纪录。海报显示,对比对象为2023年7月20日至2024年7月19日上市的所有大折叠屏手机。站长网2024-07-21 14:12:060000SpaceX“星舰”获得发射许可 即将实施首次轨道试飞
凤凰网科技讯北京时间4月15日消息,SpaceX的“星际飞船”已经获得了美国联邦航空管理局(FAA)的发射许可,这意味着该火箭最快下周一就可以执行首次轨道试飞。SpaceX周五发布推文称,该公司的目标是最快于4月17日(下周一)在得州星舰基地执行“星际飞船”和超重型火箭完整堆叠后的首次试飞。借助超重型火箭,“星际飞船”要将人类和货物运送到地球轨道、月球和火星。SpaceX最快下周一试飞站长网2023-04-15 09:18:240000Dropbox宣布裁员16%,发力AI
DoNews4月28日消息,云存储服务商Dropbox当地时间27日宣布将裁员500人,占其员工总数的16%,这是该公司为了应对经济困境和业务转型而采取的重组措施。站长网2023-05-12 20:36:010000