HuggingFace推出最大的开放合成数据集Cosmopedia 250亿个tokens
划重点:
- 🌍 Cosmopedia v0.1是由 Mixtral7b 生成的最大开放合成数据集,包含超过3000万个样本,总共约250亿个tokens。
- 💻 数据集汇编了来自网页数据集(如 RefinedWeb 和 RedPajama)的信息,涵盖教科书、博客文章、故事和 WikiHow 文章等各种内容类型。
- 📚 这一初始版本的 Cosmopedia 为合成数据领域的研究奠定了基础,展示了其在各种主题上的潜在应用。
HuggingFace 推出了 Cosmopedia v0.1,这是最大的开放合成数据集,由 Mixtral7b 生成,包含超过3000万个样本,总共约250亿个标记tokens。
数据集旨在通过映射来自网页数据集如 RefinedWeb 和 RedPajama 的信息来汇编全球知识,包括教科书、博客文章、故事和 WikiHow 文章等各种内容类型。该数据集的结构分为八个部分,每个部分都源自不同的种子样本,其中包括 web_samples_v1和 web_samples_v2,占据数据集约75% 的比例,这些样本类似于 RefinedWeb 中的内部网页数据集。
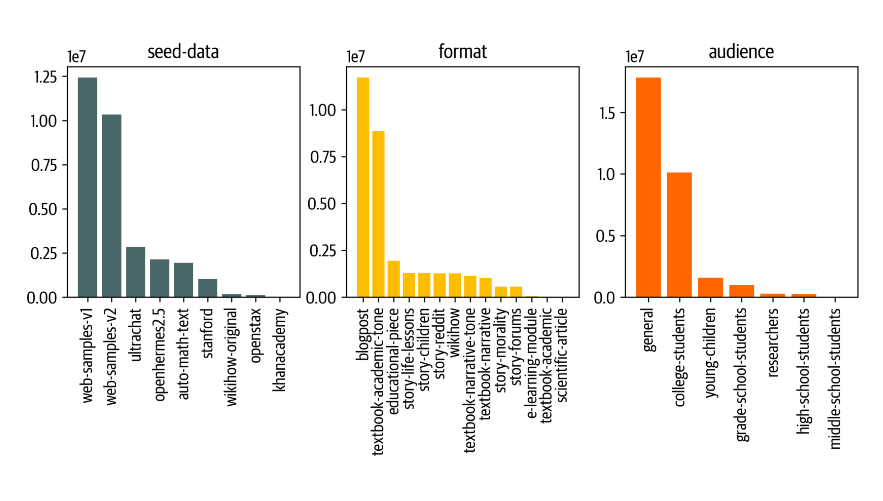
Stanford 分区利用从 stanford.edu 网站上爬取的课程大纲,而故事分区则包含来自 UltraChat 和 OpenHermes2.5的生成故事。此外,WikiHow、OpenStax、KhanAcademy 和 automathtext 分区涉及与其各自来源相关的提示。
为了方便用户访问数据集,用户可以使用提供的代码段加载特定分区。另外,对于寻求缩减数据集的用户,还提供了一个更小的子集 Cosmopedia-100k。此外,还对 Cosmopedia 进行了训练,得到了一个更大的模型 Cosmo-1B,展示了其可扩展性和多功能性。
数据集的创建过程包括为 web 样本使用主题聚类方法、迭代地改进提示以及解决污染问题。其目标是通过量身定制提示风格和受众,最大程度地提高多样性,从而显著减少重复内容。
数据集入口:https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
Gemini 即将开始收费 开发者“白嫖”的好日子到头了
开发者白嫖Gemini的好日子结束了!近日,有开发者称收到了GeminiAPI团队的邮件,邮件通知称,Google将于2024年5月2日起更新GeminiAPI的附加服务条款,并开始对通过云计费账户进行的API请求收费。站长网2024-04-18 14:27:160000今年以来,抖音直播处置户外低俗直播行为帐号27W+个
今日,抖音直播发布了关于整治户外直播乱象的处置公示第四期内容。2023年1月至今共处罚涉及户外低俗直播行为的帐号271,919个。站长网2023-04-16 08:06:440000主播被判赔公会3000万背后:除了违约,还是转型失败的案例?
又一起主播与机构之间的纠纷!近日,据企查查,主播庄某成了失信被执行人,关联司法案件为新沂顺图网络科技有限公司(时光公会的主体公司)与其网络服务合同纠纷。其中,庄某被判向时光公会支付各项费用共计3000万元。据司法公开信息显示,“庄某”全名为庄严。在行业内名极一时的老牌头部主播MC九局(以下称“九局”),据公开资料显示,其真名就是庄严。站长网2023-05-31 09:34:520000nova首款小折叠!华为nova Flip今晚预售:5288元起
快科技8月5日消息,华为novaFlip将于今天20:30开启预售,目前,华为正式公布新机价格,共三款配置,256GB售价5288元、512GB售价5688元、1TB售价6488元。另外,华为还推出了novaFlip迷你包,售价499元,将于8月9日10:08开售。据了解,华为novaFlip是华为nova系列首款小折叠手机,同时也是华为小折叠家族中,首款采用方形外屏的折叠机。站长网2024-08-05 20:37:260000最新!“送礼物”开放超级新入口
如果你此刻更新苹果新版微信,会发现“送礼物”已出现在一个新的入口中:聊天时你想给好友发送图片、打视频或音频电话、发送红包等,都需要点击好友聊天输入框右侧的“”号。现在,“送礼物”也出现在这个区域了。对比过往版本,在这个区域原本有“收藏”,现在,“收藏”被挤到了下一页。资源让位给了“送礼物”。这是截至目前,“送礼物”的最新调整。0000