字节跳动推出颠覆性文生视频模型,可自由控制动作!
在Sora引爆文生视频赛道之前,国内的字节跳动也推出了一款颠覆性视频模型——Boximator。
与Gen-2、Pink1.0等模型不同的是,Boximator可以通过文本精准控制生成视频中人物或物体的动作。
例如,下雨天,大风把一位女生的雨伞吹走了。目前,很少有视频模型能精准做到这一点。
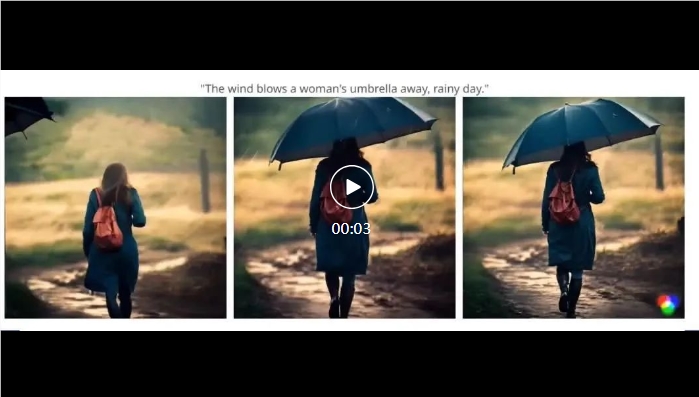
左侧为Boximator生成的视频
论文地址:https://arxiv.org/abs/2402.01566
项目地址:https://boximator.github.io/

Boximator案例赏析
我们先看一下Boximator与Gen-2、Pink1.0,在使用相同的文本提示词、图像生成的视频,所表现出来的不同动作。
为了方便观察,「AIGC开放社区」将对比视频整合在一起,最左边的是Boximator生成的视频。
1),一个可爱的3D男孩站着,然后走路。

在这个案例中,Pika1.0生成的视频男孩只是站着没有走动,Gen-2的视频走动了但不明显,只有Boximator产生了明显的走动动作。
2)一位英俊的男人用他的右手从口袋里拿出一朵玫瑰,并且在看着这朵玫瑰。

这个案例Pika1.0和Gen-2表现的都非常不好,男士没有掏出玫瑰花的动作。Boximator再一次完美理解文本语义并做出了相应的动作。
3)往杯子里加红酒
这个案例主要展示了控制物体动作的能力,Pika1.0和Gen-2都做出了倒酒的动作,但是杯子里的酒没有明显上升的动作。只有Boximator做到了倒酒 上升两个动作。
看了这3个案例,能感受到Boximator对文本语义精准理解,以及对动作控制的强大功能了吧。
Boximator模型介绍
为了实现对视频中物体、人物的动作控制,Boximator使用了“软框”和“硬框”两种约束方法。
硬框:可精确定义目标对象的边界框。用户可以在图片中画出感兴趣的对象,Boximator会将其视为硬框约束,在之后的帧中精准定位该对象的位置。

软框:软框定义一个对象可能存在的区域,形成一个宽松的边界框。对象需要停留在这个区域内,但位置可以有一定变化,实现适度的随机性。
两类框都包含目标对象的ID,用于在不同帧中跟踪同一对象。此外,框还包含坐标、类型等信息的编码。
控制模块和训练策略
控制模块可以将框约束的编码与视频帧的视觉编码结合,用来指导视频的精准动作生成。包含框编码器和自注意力层两大块。
框编码器:将框的坐标、ID、类型等信息,通过Fourier编码和MLP映射为控制向量。

自注意力层:将框的控制向量与视频帧的视觉向量通过自注意力建模其关系,学习将框指导帧生成。
训练策略方面,Boximator主要分为两个阶段:自跟踪阶段,训练模型的同时生成视频内容和对应的框,并简化框与对象的关系学习。

正常训练,训练模型只生成视频内容,框的内在表达已经学会指导对象生成。此外,训练还使用多阶段策略,逐步过渡从硬框到软框的约束,以及适当融合无框数据。
Boximator实验数据
为获得视频训练数据,研究人员从WebVid-10M数据集中,过滤出110万段动态明显的视频片段,并自动为其注释了220万个对象的边界框。并在PixelDance和ModelScope这两个模型上训练了Boximator。

实验数据显示,Boximator在保持原模型视频质量,具有非常强大的动作控制能力。同时可以作为一种插件,帮助现有视频扩散模型提升生成质量。
在MSR-VTT数据集上,无论是视频质量还是框与对象对齐精度方面,Boximator都优于原模型。在人类评估中,Boximator生成的视频也在质量和运动控制上明显超过原模型。

字节跳动的研究人员表示,目前该模型处于研发阶段,预计2-3个月内发布测试网站。让我们期待一下国内挑战Sora的产品诞生吧!
DeepSeek官方推荐:R1要这样设置
家人们,咱们到底该如何部署DeepSeek-R1,才能体验最佳啊?对于这个问题,DeepSeek官方发话了:DeepSeek推荐的设置非常简单,只有四项内容。其中三项,其实在此前相关文档中有所涉及,我们在这里再来回顾一下。首先,是别用系统提示词(Nosystemprompt),所有的指令都应该包含在用户提示词中。至于原因,网友认为是因为R1就是这么被训练而来的。0000曾对华为下死手!死对头思科日子难过:又又又要海量裁员了
快科技8月10日消息,据国外媒体报道称,在接连裁员后,思科计划启动今年新一轮裁员,预估影响4000名员工。根据公司提交的年度文件,截至2023年7月,公司员工总数约为84900人(这一数字不包括2月份的裁员)。作为当今全球网络设备领域两大巨头,从2002年盯”上华为开始,思科曾与华为进行了长达10年的战争”。0000微信:已有4615万用户开启微信“关怀模式”
根据微信派公众号公布数据,到今年5月,已有4615万用户开启了微信“关怀模式”,2295万人打开了“听文字消息”,“听文字消息”每天读出12亿字,累计读出约2531亿字。据介绍,针对不识字的老人,为了让这些用户也能平等地获取信息,微信基础产品团队联合微信AI团队,在“关怀模式”中推出了“听文字消息”功能,开启后,只需轻触“单聊”、“群聊”中的文字消息,就可听到朗读。站长网2023-05-31 21:00:360000每周AI大事件 | 国产大模型热战开启、AI监管规定来了、马斯克入局AIGC大战
欢迎来到站长之家的[每周AI大事件],这里记录了过去一周值得关注的AI领域相关内容,帮助大家更好地了解人工智能领域的动态和发展风向。Part1动态「国内要闻」生成式人工智能服务管理办法发布其中提到利用AI生成内容应当真实准确,采取措施防止生成虚假信息;提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责等。知乎发布"知海图AI"中文大模站长网2023-04-14 09:43:010003消息称红米Redmi K70高配版将搭载骁龙 8 Gen 3
最近有数码博主爆料称,小米旗下品牌Redmi即将推出新一代旗舰机型RedmiK70系列。据称,该系列手机将全系标配无塑料支架,并搭载极窄2K新直屏,高配版本还将搭载高通骁龙8Gen3处理器,内置5120mAh大电池,支持120W有线快充等。站长网2023-07-14 00:35:490000