谷歌推具备空间推理能力的视觉语言模型SpatialVLM
站长网2024-02-18 15:27:180阅
要点:
1、谷歌提出了SpatialVLM,旨在赋予视觉语言模型空间推理能力。
2、研究者利用现实世界数据训练SpatialVLM,弥补了常见数据集对空间信息的限制。
3、通过生成大规模空间VQA数据集,研究者成功使视觉语言模型具备直接空间推理和链式思维能力。
谷歌最新研究提出SpatialVLM,旨在解决视觉语言模型缺乏空间推理能力的问题。过去,视觉语言模型在理解目标在三维空间中位置或关系时存在困难,研究者通过借鉴人类空间推理能力的思路,提出了这一新方法。他们强调,当前模型的限制可能来自训练时使用的数据集的限制,因此他们专注于从现实世界数据中提取空间信息,以提升模型的表现。

项目地址:https://spatial-vlm.github.io/
研究者使用开放词汇检测、深度估计、语义分割等模型提取真实世界数据,训练SpatialVLM以增强空间推理能力。实验证明,这一模型在回答空间问题和定量估计方面表现出色,甚至在有噪声的训练数据下也能可靠工作。SpatialVLM不仅具备了常识知识,还能在复杂的空间推理任务中展现出强大的表现。
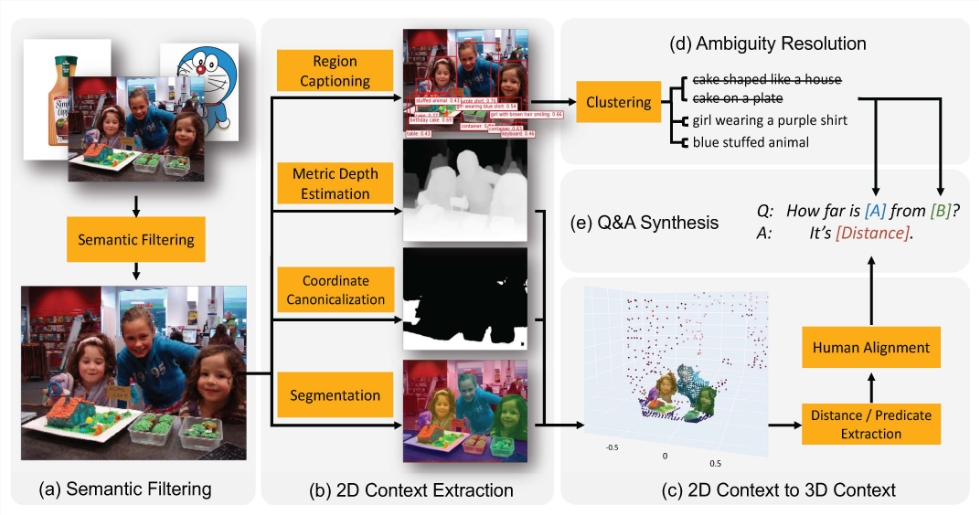
为了让视觉语言模型具备空间推理能力,研究者设计了一个全面的数据生成框架,通过提取实体信息和生成大规模空间VQA数据集来训练模型。他们指定了38种不同类型的空间推理问题,包括定性和定量问题,并创建了包含数亿个问答对的庞大数据集。通过这种方式,他们成功使模型具备了直接空间推理和链式思维的能力,提升了视觉语言模型的整体性能。
总的来说,谷歌的新研究为视觉语言模型的发展带来了新的可能性,通过赋予模型空间推理能力,使其在处理复杂空间任务时表现更为出色。这一研究成果有望推动视觉语言模型在未来的发展方向上取得更大突破,为人工智能领域带来新的进步。
0000
评论列表
共(0)条相关推荐
天猫精灵发布首款大模型多感知学习机Z20
10月18日,天猫精灵发布了首款大模型多感知学习机Z20。这款学习机具备大模型和多模态AI感知能力,可以适应不同年龄段和学科的学习需求。用户可以通过语音或文字与学习机进行对话,并可以个性化设置英文对话的分级、情境和口吻。学习机还提供专业学习法和错题巩固法,并引入了多种权威优质IP内容。站长网2023-10-18 22:04:460001刘保中:短视频有助于建立更平等的代际关系
中国青年网北京5月22日电(记者牟昊琨实习记者李梦雨)“我们在社会学视角下理解青少年,代际比较是很重要的一个分析维度。”5月18日,在由中国社会科学院新闻与传播研究所主办的“短视频与青少年发展”研讨会上,中国社会科学院社会学研究所副研究员刘保中认为,在数字化社会,传统的代际关系模式正在表现出新的特点。0000耗资1.3万,ASU团队揭秘o1推理!碾压所有LLM成本超高,关键还会PUA
【新智元导读】LLM不会规划,大推理模型o1可以吗?ASU团队最新研究发现,o1-preview推理规划能力是所有模型之最,但仍未触及天花板。关键是,推理强,成本超高。LLM依然不会规划,LRM可以吗?OpenAI声称,草莓o1已经突破了自回归LLM常规限制,成为一种新型的「大推理模型」(LRM)。它能够基于强化学习,通过CoT多步推理。并且,这种推理过程的代价,是高昂的。站长网2024-10-06 23:35:010000华为华南首家服务旗舰店开业:智能机器人代替工程师寻找备件
快科技12月3日消息,据华为终端公司”官微消息,日前,华为客户服务中心(广州高志大厦)正式开业,位于广州市天河区黄埔大道120号高志大厦3楼。据介绍,这是华为华南首家服务旗舰店,提供面对面维修、智能备件柜、咖啡吧等全面智能服务体验,最大特色之一是采用全新维修模式。推出了面对面”服务坐席和全透明备件区,消费者可直接与工程师沟通设备情况、面对面观看维修过程。0000MyShell多语言、多口音文本转语音库MeloTTS开源
近日,MyShell公司宣布其多语言、多口音的文本转语音库MeloTTS正式开源。这一消息在开源社区引起了广泛关注。MeloTTS支持的语言包括英语、西班牙语、法语、中文、日语和韩语,为开发人员提供了丰富的选择。试玩地址:https://top.aibase.com/tool/melotts站长网2024-03-08 13:28:270000