亚马逊发布其有史以来最大的文本转语音模型 BASE TTS
划重点:
⭐️ 亚马逊 AGI 团队发布了有史以来最大的文本转语音模型,具有最多的参数和最大的训练数据集。
⭐️ 新模型名为 BASE TTS,拥有980亿参数,使用了10万小时的录音数据进行训练,主要是英语。
⭐️ 该团队计划将 BASE TTS 用作学习应用,以改进文本转语音应用的人类声音质量。
亚马逊 AGI 的人工智能研究团队宣布开发了他们所描述的有史以来最大的文本转语音模型。所谓最大,是指拥有最多参数并使用最大训练数据集。他们在 arXiv 预印服务器上发布了一篇论文,描述了该模型的开发和训练过程。
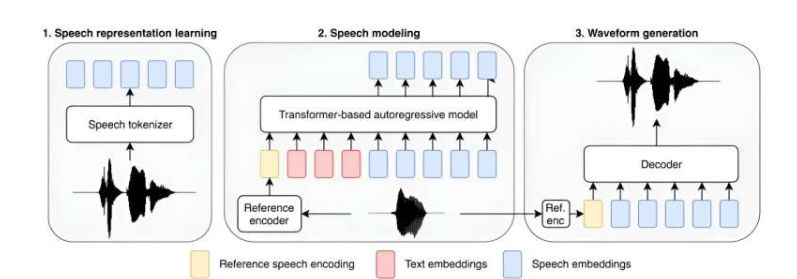
与 ChatGPT 等大型语言模型(LLMs)因其人类化的智能回答问题和创建高水平文档的能力而备受关注不同,人工智能正在逐步应用于其他主流应用。在这一新尝试中,研究人员试图通过增加模型参数的数量和扩充训练基础来改进文本转语音应用的能力。
这一新模型被称为 Big Adaptive Streamable TTS with Emergent abilities(简称为 BASE TTS),拥有98亿参数,并使用了10万小时的录音数据进行训练,其中大部分是英语。该团队还为其提供了其他语言中已知短语的口语单词和短语示例,以使模型在遇到这些短语时能够正确发音,比如 “au contraire” 或 “adios, amigo”。
亚马逊团队还在较小的数据集上对模型进行了测试,希望了解模型何时会出现所谓的新兴特性,即人工智能应用,无论是 LLM 还是文本转语音应用,突然似乎突破到更高层次的智能。他们发现,对于他们的应用程序来说,新兴特性出现在拥有1.5亿参数时。
他们还指出,这种飞跃涉及一系列语言属性,例如使用复合名词,表达情感,使用外语词汇,应用语音附加语和标点,以及在句子中将重点放在正确的单词上提出问题。
该团队表示,他们不会向公众发布 BASE TTS,因为他们担心它可能被不道德地使用,而是计划将其用作学习应用。他们希望应用他们迄今为止所学到的知识,以改进文本转语音应用程序的人类声音质量。
论文网址:https://dx.doi.org/10.48550/arxiv.2402.08093
AI 虚拟代理将取代搜索引擎 专家:到2026年搜索量将下降25%
据权威机构Gartner公司预测,到2026年,传统搜索引擎的数量将会下降25%,而AI聊天机器人和其他虚拟代理将夺走搜索营销的市场份额。Gartner公司的副总裁分析师AlanAntin指出,自然搜索和付费搜索一直是技术营销人员重要的渠道,但随着生成式人工智能(GenAI)解决方案的崛起,这一局面即将发生改变。站长网2024-02-20 10:03:090000猫晚再造猫晚
11月10日晚,天猫双11惊喜夜(简称“猫晚”)重磅回归,双11的快乐又回来了。这一次,天猫依然请来了半个娱乐圈的明星,前有大张伟演唱《万物盛开法则》,开篇即高潮;又有华晨宇带来《点燃银河镜头的篝火》,梦幻又神秘;最后易烊千玺用一首《羞答答的玫瑰静悄悄地开》又一次制造出晚会的心动名场面。70组艺人,直接将双11惊喜夜躁成了“春晚”。站长网2023-11-12 10:34:060001字节商业化:曾经步子迈得既快又大
前段时间,一则「抖音电商去年GMV为2万多亿元,而广告收入高达4000亿元」的消息引起广泛关注。随着名创优品创始人叶国富的引用和点评(最后该朋友圈被删除),外界关于抖音电商广告收入的猜测达到顶峰。之后,字节跳动副总裁李亮站出来发声:「抖音广告收入中,只有一部分来自电商业务,更大部分来自非电商信息流。不好直接与电商公司对比,这样混淆,很容易引发误解和对立情绪。」0000刘强东内部狼性训话流出:拼搏者留 懒散者去
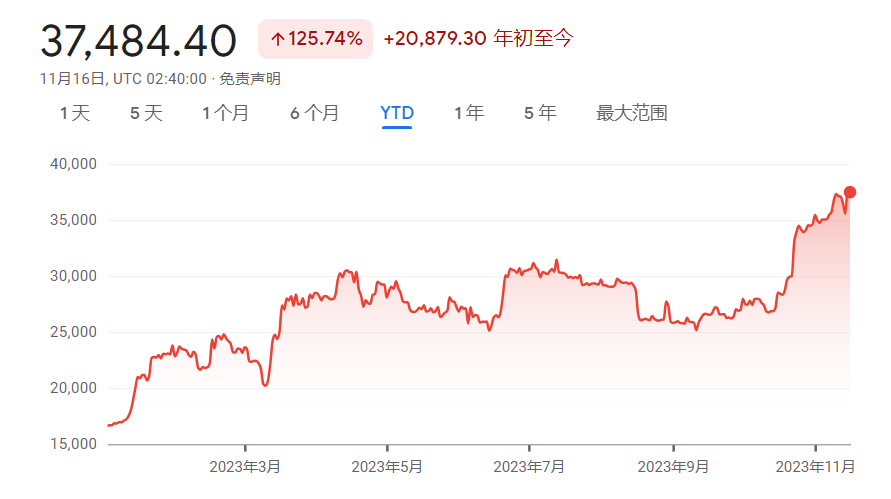
站长之家(ChinaZ.com)5月27日消息:在5月24日的线上讲话中,刘强东不仅宣布了为全体采销人员涨薪20%至100%的重大决定,更进行了一场深入的“狼性训话”。他强调,京东的快速发展和卓越业绩,并非建立在员工“躺着睡大觉”的基础上。站长网2024-05-27 15:07:230000比特币价格飙升至近一年新高:近3.8万美元,但远未达到2021年最高水平
**划重点:**1.🚀最新数据显示比特币价格接近38,000美元,为近一年最高,过去一个月涨幅超过38%。2.📈增长原因可能包括联邦利率放缓,FTX创始人SamBankman-Fried的定罪,以及美国证券交易委员会批准比特币交易所交易基金(ETF)。站长网2023-11-16 11:06:470000