语音生成的「智能涌现」:10万小时数据训练,亚马逊祭出10亿参数BASE TTS
伴随着生成式深度学习模型的飞速发展,自然语言处理(NLP)和计算机视觉(CV)已经经历了根本性的转变,从有监督训练的专门模型,转变为只需有限的明确指令就能完成各种任务的通用模型。
在语音处理和文本到语音(TTS)领域,这样的转变也正在发生,模型能够利用数千小时的数据,使合成结果越来越接近类人语音。
在最近的一项研究中,亚马逊正式推出了 BASE TTS,将 TTS 模型的参数规模提升到了前所未有的10亿级别。

论文标题:BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on100K hours of data
论文链接:https://arxiv.org/pdf/2402.08093.pdf
BASE TTS 是一个多语言、多说话人的大型 TTS(LTTS)系统,在约10万小时的公共领域语音数据上进行了训练,比此前的训练数据量最高者 VALL-E 翻了一番。受 LLM 成功经验的启发,BASE TTS 将 TTS 视为下一个 token 预测的问题。这种方法通常与大量训练数据结合使用,以实现强大的多语言和多说话人能力。
本文的主要贡献概述如下:
1、提出了 BASE TTS,这是迄今为止最大的 TTS 模型,具有10亿参数,并在由10万小时公共领域语音数据组成的数据集上进行了训练。在主观评估中,BASE TTS 的表现优于公开的 LTTS 基线模型。
2、展示了如何将 BASE TTS 扩展到更大的数据集和模型规模,以提高其为复杂文本呈现适当韵律的能力。为此,研究者开发并提供了一个「涌现能力」测试集,可作为大规模 TTS 模型文本理解和渲染的主观评估基准。本文报告了 BASE TTS 的不同变体在该基准上的表现,结果显示,随着数据集规模和参数量的增加,质量也在单调提升。
3、提出了建立在 WavLM SSL 模型之上的新型离散语音表示法,旨在只捕捉语音信号的音位和韵律信息。这些表示法优于基准量化方法,尽管压缩水平很高(仅400比特 / 秒),但仍能通过简单、快速和流式解码器将其解码为高质量的波形。
接下来,让我们看看论文细节。
BASE TTS 模型
与近期的语音建模工作类似,研究者采用了基于 LLM 的方法来处理 TTS 任务。文本被输入到基于 Transformer 的自回归模型,该模型可预测离散音频表示(称为语音编码),再通过由线性层和卷积层组成的单独训练的解码器将它们解码为波形。
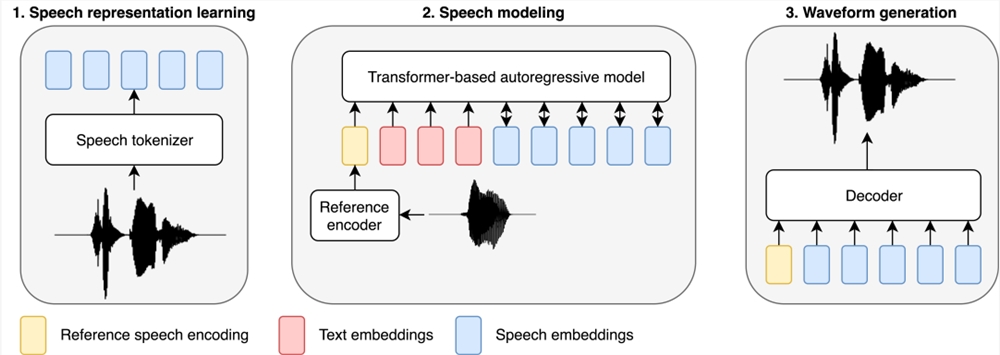
BASE TTS 设计的目的是模拟文本 token 的联合分布,然后是离散的语音表示,研究者称之为语音编码。通过音频编解码器对语音进行离散化是设计的核心,因为这样就能直接应用为 LLM 开发的方法,而 LLM 正是 LTTS 最新研究成果的基础。具体来说,研究者使用具有交叉熵训练目标的解码自回归 Transformer 对语音编码进行建模。尽管简单,但这一目标可以捕捉到表达性语音的复杂概率分布,从而缓解早期神经 TTS 系统中出现的过度平滑问题。作为一种隐式语言模型,一旦在足够多的数据上训练出足够大的变体,BASE TTS 在韵律渲染方面也会有质的飞跃。
离散语言表示
离散表示法是 LLM 取得成功的基础,但在语音中识别紧凑且信息丰富的表示不如在文本中那么明显,此前的探索也较少。对于 BASE TTS,研究者首先尝试使用 VQ-VAE 基线(第2.2.1节),该基线基于自动编码器架构,通过离散瓶颈重构 mel 频谱图。VQ-VAE 已成为语音和图像表征的成功范例,尤其是作为 TTS 的建模单元。
研究者还介绍了一种通过基于 WavLM 的语音编码学习语音表示的新方法(第2.2.2节)。在这种方法中,研究者将从 WavLM SSL 模型中提取的特征离散化,以重建 mel 频谱图。研究者应用了额外的损失函数来促进说话人的分离,并使用字节对编码(BPE,Byte-Pair Encoding)压缩生成的语音代码,以减少序列长度,从而使得能够使用 Transformer 对较长的音频进行建模。
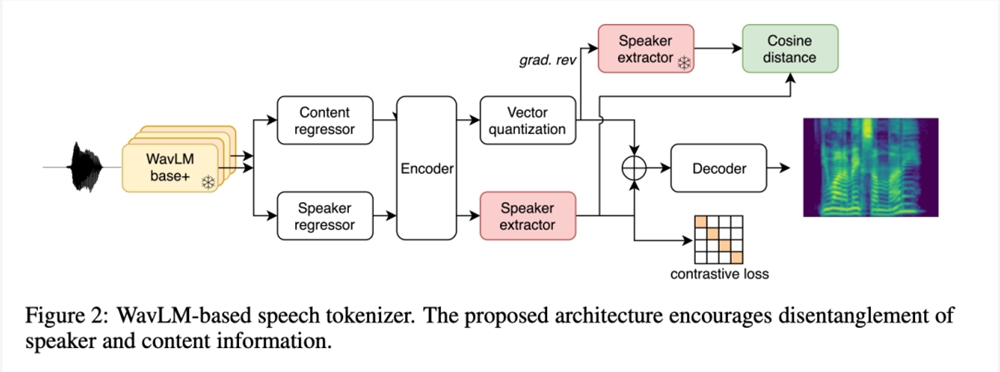
与流行的音频编解码器相比,这两种表示法都经过了压缩(分别为325bits/s 和400bits/s),以实现更高效的自回归建模。基于这种压缩水平,接下来的目标是去除语音编码中可在解码过程中重建的信息(说话人、音频噪声等),以确保语音编码的容量主要用于编码语音和韵律信息。
自回归语音建模(SpeechGPT)
研究者训练了一个 GPT-2架构的自回归模型「SpeechGPT」,用于预测以文本和参考语音为条件的语音编码。参考语音条件包括从同一说话人随机选择的语句,该语句被编码为固定大小的嵌入。参考语音嵌入、文本和语音编码被串联成一个序列,该序列由一个基于 Transformer 的自回归模型建模。研究者对文本和语音使用单独的位置嵌入和单独的预测头。他们从头开始训练了自回归模型,而不对文本进行预训练。为了保留文本信息以指导拟声,还对 SpeechGPT 进行了训练,目的是预测输入序列文本部分的下一个 token,因此 SpeechGPT 部分是纯文本 LM。与语音损失相比,此处对文本损失采用了较低的权重。
波形生成
此外,研究者指定了一个单独的语音编码到波形解码器(称为「语音编码解码器」),负责重建说话人身份和录音条件。为了使模型更具可扩展性,他们用卷积层代替了 LSTM 层,对中间表示进行解码。研究表明,这种基于卷积的语音编码解码器计算效率高,与基于扩散的基线解码器相比,整个系统的合成时间减少了70% 以上。
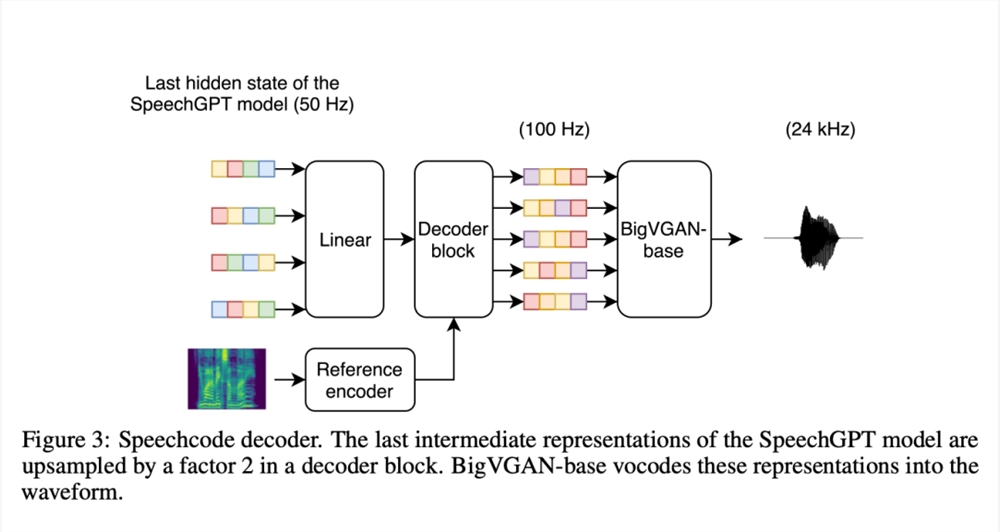
研究者同时指出,实际上语音编码解码器的输入并不是语音编码,而是自回归 Transformer 的最后一个隐藏状态。之所以这样做,是因为此前 TortoiseTTS 方法中密集的潜在表征提供了比单一语音代码更丰富的信息。在训练过程中,研究者将文本和目标代码输入训练好的 SpeechGPT(参数冻结),然后根据最后的隐藏状态对解码器进行调节。输入 SpeechGPT 的最后隐藏状态有助于提高语音的分段和声学质量,但也会将解码器与特定版本的 SpeechGPT 联系起来。这使实验变得复杂,因为它迫使两个组件总是按顺序构建。这一限制需要在今后的工作中加以解决。
实验评估
研究者探索了缩放如何影响模型针对具有挑战性的文本输入产生适当的韵律和表达的能力,这与 LLM 通过数据和参数缩放「涌现」新能力的方式类似。为了验证这一假设是否同样适用于 LTTS,研究者提出了一个评估方案来评估 TTS 中潜在的涌现能力,确定了七个具有挑战性的类别:复合名词、情感、外来词、副语言、标点符号、问题和句法复杂性。
多项实验验证了 BASE TTS 的结构及其质量、功能和计算性能:
首先,研究者比较了基于自动编码器和基于 WavLM 的语音编码所达到的模型质量。
然后,研究者评估了对语音编码进行声学解码的两种方法:基于扩散的解码器和语音编码解码器。
在完成这些结构消融后,研究者评估了 BASE TTS 在数据集大小和模型参数的3种变体中的涌现能力,并由语言专家进行了评估。
此外,研究者还进行了主观的 MUSHRA 测试以衡量自然度,以及自动可懂度和说话人相似度测量,还报告了与其他开源文本到语音模型的语音质量比较。
VQ-VAE 语音编码 vs. WavLM 语音编码
为了全面测试两种语音 token 化方法的质量和通用性,研究者对6位美式英语和4位西班牙语说话人进行了 MUSHRA 评估。就英语的平均 MUSHRA 分数而言,基于 VQ-VAE 和 WavLM 的系统不相上下(VQ-VAE:74.8vs WavLM:74.7)。然而,对于西班牙语,基于 WavLM 的模型在统计学上显著优于 VQ-VAE 模型(VQ-VAE:73.3vs WavLM:74.7)。请注意,英语数据约占数据集的90%,而西班牙语数据仅占2%。
表3显示了按说话人分类的结果:
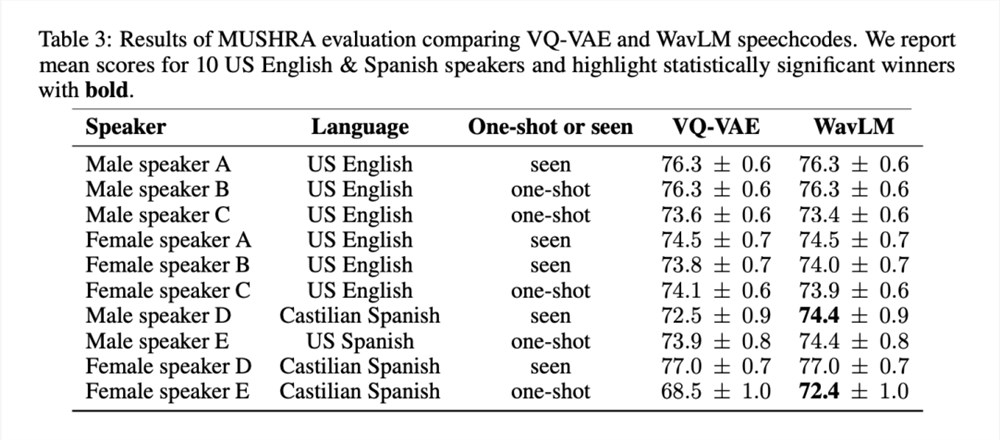
由于基于 WavLM 的系统表现至少与 VQ-VAE 基线相当或更好,因此研究者在进一步的实验中使用它来表示 BASE TTS。
基于扩散的解码器 vs. 语音代码解码器
如上文所述,BASE TTS 通过提出端到端语音编码解码器,简化了基于扩散的基线解码器。该方法具有流畅性,推理速度提高了3倍。为了确保这种方法不会降低质量,研究者对所提出的语音编码解码器与基线进行了评估。表4列出了对4位说英语的美国人和2位说西班牙语的人进行的 MUSHRA 评估结果:
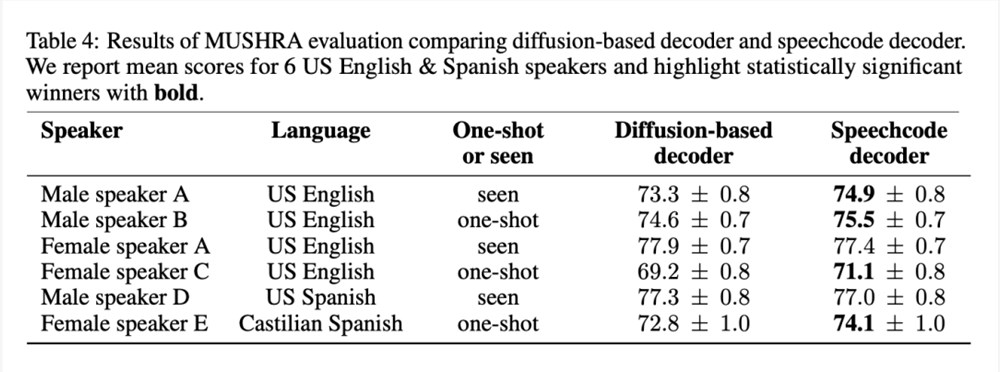
结果显示,语音编码解码器是首选方法,因为它不会降低质量,而且对大多数语音而言,它能提高质量,同时提供更快的推理。研究者同时表示,结合两个强大的生成模型进行语音建模是多余的,可以通过放弃扩散解码器来简化。
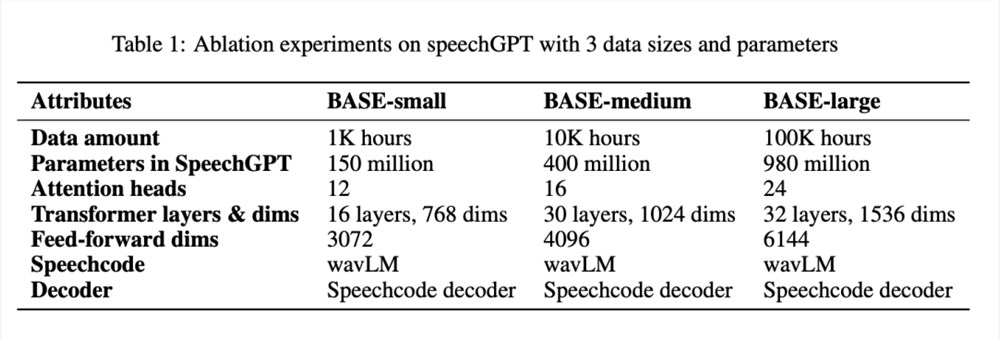
涌现能力:数据和模型规模的消融
表1按 BASE-small、BASE-medium 和 BASE-large 系统报告了所有参数:
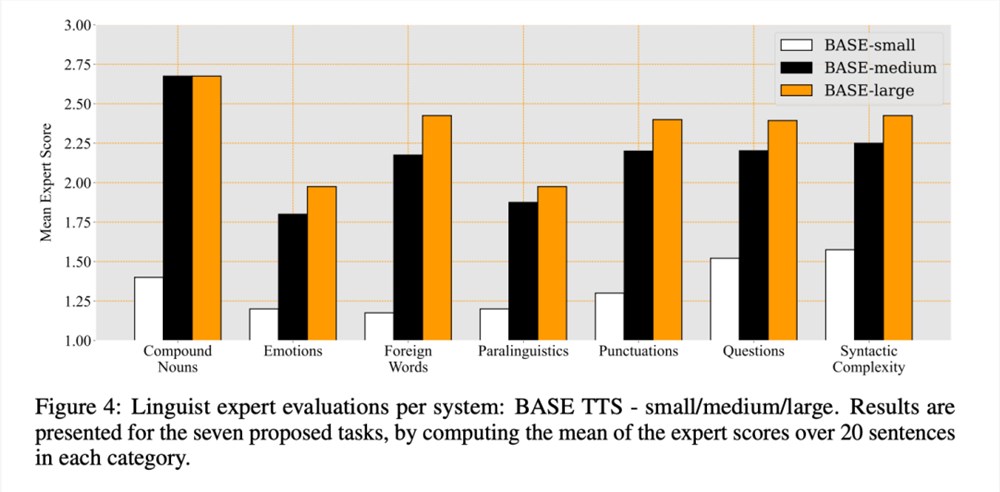
三个系统的语言专家判断结果以及每个类别的平均得分如图4所示:
在表5的 MUSHRA 结果中,可以注意到语音自然度从 BASE-small 到 BASE-medium 有明显改善,但从 BASE-medium 到 BASE-large 的改善幅度较小:
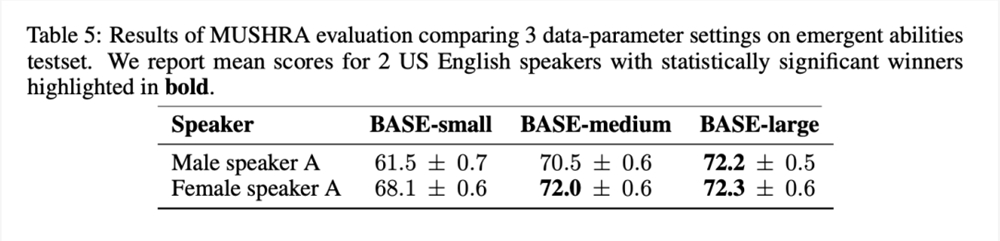
BASE TTS vs. 行业 baseline
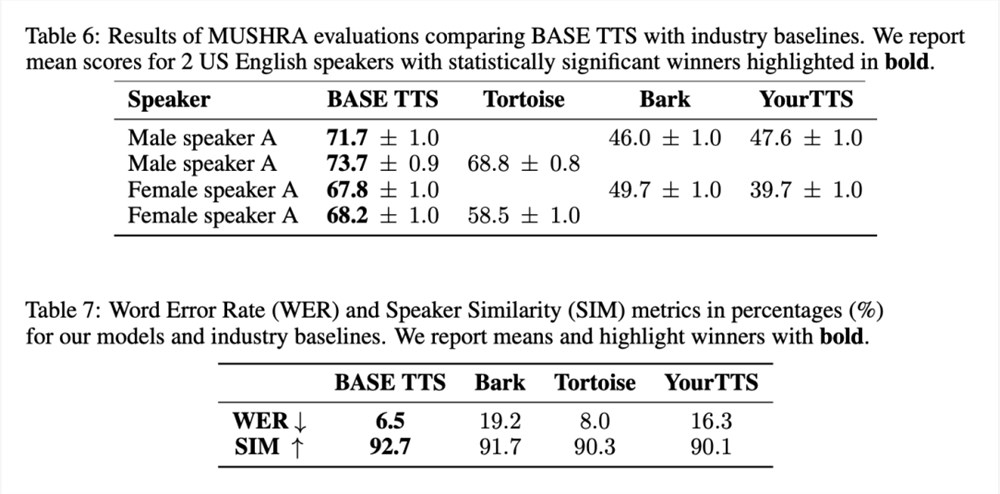
总体来说,BASE TTS 生成的语音最自然,与输入文本的错位最少,与参考说话人的语音最相似,相关结果如表6和表7所示:
语音编码解码器带来的合成效率提升
语音编码解码器能够进行流式处理,即以增量方式生成语音。将这一功能与自回归 SpeechGPT 相结合,该系统的首字节延迟可低至100毫秒 —— 只需几个解码语音代码就足以产生可懂的语音。
这种最低延迟与基于扩散的解码器形成了鲜明对比,后者需要一次性生成整个语音序列(一个或多个句子),而首字节延迟等于总生成时间。
此外,研究者还观察到,与扩散基线相比,语音编码解码器使整个系统的计算效率提高了3倍。他们运行了一个基准测试,在 NVIDIA® V100GPU 上生成1000个持续时间约为20秒的语句,批大小为1。平均而言,使用扩散解码器的十亿参数 SpeechGPT 需要69.1秒才能完成合成,而使用语音编码解码器的相同 SpeechGPT 只需要17.8秒。
有大量实体门店的商家,视频号可能是你转型线上的最后机会
去年底我邀请“创始人全域增长战略班”第3期的学员——林清轩的创始人孙来春先生录制了一期浩友圈的对话。在我提到当下的流量环境很复杂,很多品牌在追赶“流量”的过程中,很容易忽略商业的本质,就是扎扎实实地做好产品,做好渠道,做好消费者服务,因而,很多因“流量”而声名鹊起的品牌,也很容易在流量消逝后跌落神坛。站长网2024-07-25 17:15:460000骁龙8Gen2手机阵营性能强者,一加手机11娱乐体验属实完美
一加手机11自推出之后人气一直都很高,不仅在国内广受欢迎,在国外市场也是备受好评。一加手机11在京东天猫双平台开售51分钟就创造了骁龙8Gen2机型的首销记录。而这款手机能够这么受肯定,主要还是因为性能强,使用体验好。毕竟作为骁龙8Gen2手机阵营性能强者,一加11的实力,确实是肉眼可见的。站长网2023-05-24 09:28:580001Android 的前 15 年改变了世界:借助人工智能,谷歌可能再次改变世界
2005年,谷歌以5000万美元收购了加州小型软件公司Android,并做出了一个影响深远的决策——将Android操作系统完全免费开源,任何公司都可以使用和创建设备。这一战略的背后是对苹果iPhone崛起的直观应对,以及对未来技术格局的深远考量。站长网2023-11-06 16:15:060000AI芯片公司Tenstorrent获得1亿美元融资 现代、三星等参与
1.加拿大AI芯片初创公司Tenstorrent获得来自现代汽车和三星等投资者1亿美元资金。2.Tenstorrent由芯片行业资深人士JimKeller领导,专注于开发人工智能芯片。3.Tenstorrent计划挑战市场领导者Nvidia,同时开发用于智能电视等领域的AI芯片。站长网2023-08-03 15:32:520002视频生成模型Gen-3 Alpha和Dream Machine有API了?
近日AI视频生成工具接连“内卷”,开始”神仙打架“模式。无论是Runway的Gen-3AIpha还是Luma的DreamMachine都是业内翘楚!既然同样作为视频生成模型,那肯定免不了拿来对比。看下Luma的DreamMachine和RunwayGen-3Alpha生成的视频对比。(均生成自302.AI的AI视频生成器)站长网2024-07-20 00:58:030000