微软开源多模态模型LLaVA-1.5媲美GPT-4V效果
划重点:
🌐 微软研究院、威斯康星大学开源LLaVA-1.5,加入多模态模型主流。
🚀 LLaVA-1.5引入跨模态连接器和学术视觉问答数据集,全面提升多模态理解和生成。
📊 在多个知名数据平台测试中,LLaVA-1.5达到开源模型最高水平,媲美GPT-4V效果。
微软开源了多模态模型LLaVA-1.5,继承LLaVA架构并引入新特性。研究人员对其在视觉问答、自然语言处理、图像生成等进行了测试显示,LLaVA-1.5达到了开源模型中的最高水平,可媲美GPT-4V效果。
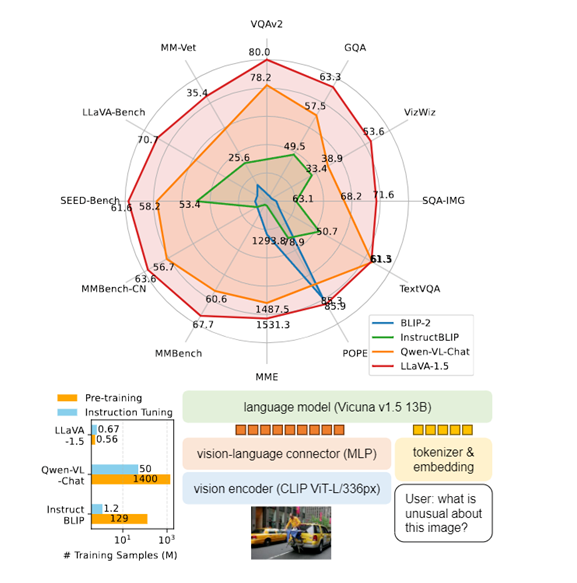
该模型由视觉模型、大语言模型和视觉语言连接器三大块组成。其中,视觉模型使用了预先训练好的CLIP ViT-L/336px,通过CLIP编码可得到固定长度的向量表示,提升图像语义信息表征。与前版本相比,CLIP模型参数和输入分辨率均有显著提升。
大语言模型采用了拥有130亿参数的Vicuna v1.5,用于理解用户输入文本并捕获语义信息,具备强大的推理和生成能力。不同于仅进行图像编码器调优的方法,LLaVA-1.5在训练中更新大语言模型参数,使其能够直接学习如何整合视觉信息进行推理,提高模型自主性。
视觉语言连接器方面,LLaVA-1.5采用双层MLP连接器替代线性投影,有效将CLIP编码器输出映射到大语言模型的词向量空间。
在训练流程上,LLaVA-1.5遵循双阶段训练方式。首先,进行视觉语言表示的预训练,使用约60万张图像文本对,训练时间约1小时。随后,在65万多模态指令数据上进行调优,训练时间约20小时。这种高效的双阶段训练确保了模型的收敛性,并在一天内完成整个流程,相较于其他模型大幅度减少了AI算力和时间成本。
研究人员还设计了匹配的响应格式提示,指导模型根据交互类型调整输出形式以满足特定场景需求。在视觉指令调优方面,LLaVA-1.5使用不同类型的数据集,包括VQA、OCR、区域级VQA、视觉对话、语言对话等,总计约65万条数据,为模型提供丰富的视觉场景推理和交互方式。
LLaVA-1.5在多模态领域取得显著进展,通过开源促进了其在视觉问答、自然语言处理、图像生成等方面的广泛应用。
项目GitHub入口:https://top.aibase.com/tool/llava
沙特阿拉伯正利用人工智能来防治荒漠化
本文概要:1.沙特环境部启动AI防治荒漠化计划,与多个机构合作评估植被覆盖情况。2.由于干旱气候和气候变化,荒漠化给该国带来重大挑战。3.AI分析卫星图像数据,找到最容易荒漠化的地区;遥感技术监测植被、降雨等变化。最近,沙特阿拉伯环境部启动了一个利用人工智能防治荒漠化的计划。站长网2023-08-23 16:26:520000雷军:不懂为何苹果十年造不出车 凭啥小米三年能干成!
快科技7月20日消息,昨晚的小米发布会上,雷军公开表示,不懂为何苹果十年造不出车。雷军谈到了在造车时所收到的质疑、批评、诋毁。当时最经常听的一句话是,苹果十年干不成,为什么小米三年能干成?对此,雷军表示,自己也不知道如何人回答,自己也知道苹果为什么十年造不出车。同时,雷军还表示,其实造车这个产业已经很成熟,自己认为三年干成是一个标准的时间,因此自己实在不知道怎么回答苹果十年造不出车。0000iOS17.1改进iPhone15Pro按钮功能 避免口袋内误触
根据国外媒体的报道,苹果公司近日向开发者发布了iOS17.1第三个测试版。此次更新带来一个新功能,可以检测iPhone是否在用户口袋里,从而改变iPhone15Pro系列操作按钮的行为方式。站长网2023-10-11 16:36:290000联想:未来三年追加70亿元投资AI技术和应用
联想集团公布了2023/2024财年第一财季业绩,营收为903亿元人民币,净利润为13.3亿元人民币。其中,集团服务导向的转型业务继续增长,PC以外业务在总营收中的占比达到41.4%。联想集团董事长兼首席执行官杨元庆表示,面对全球人工智能热潮,联想集团计划在未来三年追加70亿元投资,加速部署人工智能技术和应用。站长网2023-08-17 15:10:270000提示工程没用了?MIT、斯坦福推主动提问框架GATE 让大模型主动提问
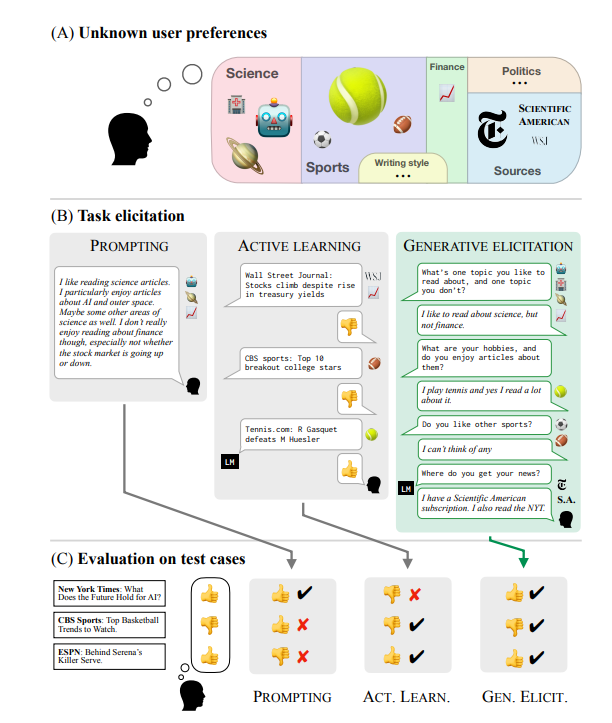
要点:1.新研究提出了一种机器学习框架,GATE,允许大型模型主动向人类提问,以更好地理解用户的偏好,替代了传统的提示工程。2.这新方法通过主动提问能够更准确地捕捉用户喜好,不再依赖用户提供的提示,从而提高了大型模型的性能。3.论文指出这一方法可能在需要复杂决策的领域如医疗和法律中有广泛应用,但关于提示工程的未来仍存在争议。站长网2023-10-20 14:33:570005