文本生成高清、连贯视频,谷歌推出时空扩散模型
谷歌研究人员推出了创新性文本生成视频模型——Lumiere。
与传统模型不同的是,Lumiere采用了一种时空扩散(Space-time)U-Net架构,可以在单次推理中生成整个视频的所有时间段,能明显增强生成视频的动作连贯性,并大幅度提升时间的一致性。
此外,Lumiere为了解决空间超分辨率级联模块,在整个视频的内存需求过大的难题,使用了Multidiffusion方法,同时可以对生成的视频质量、连贯性进行优化。

论文地址:https://arxiv.org/abs/2401.12945?ref=maginative.com
时空扩散U-Net架构
传统的U-Net是一种常用于图像分割任务的卷积神经网络架构,其特点是具有对称的编码器-解码器,能够在多个层次上捕获上下文信息,并且能够精确地定位图像中的对象。
而时空扩散U-Net是在时空维度上执行下采样和上采样操作,以便在紧凑的时空表示中生成视频。
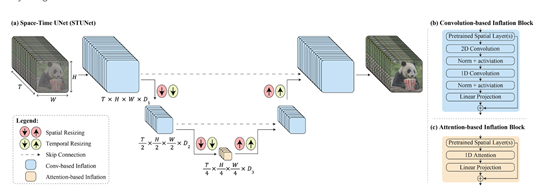
下采样的目的是减小特征图的尺寸,同时增加特征图的通道数,以捕捉更丰富的特征。
上采样则是通过插值以及将特征图的尺寸恢复到原始输入的大小,同时减少通道数,以生成更细节的输出。
时空扩散U-Net的编码器部分通过卷积和池化操作实现时空下采样。卷积层用于提取特征,并逐渐减小特征图的尺寸。
池化层则通过降采样操作减小特征图的空间尺寸,同时保留重要的特征信息。通过逐步堆叠这些下采样模块,编码器可以逐渐提取出更高级别的抽象特征。
因此,Lumiere在时空扩散U-Net架构帮助下,能够一次生成80帧、16帧/秒(相当于5秒钟)的视频。并且与传统方法相比,这种架构显著增强了生成视频运动的整体连贯性。
Multidiffusion优化方法
Multidiffusion核心技术是通过在时间窗口内进行空间超分辨率计算,并将结果整合为整个视频段的全局连贯解决方案。
具体来说,Multidiffusion通过将视频序列分割成多个时间窗口,每个时间窗口内进行空间超分辨率计算。

这样做的好处是,在每个时间窗口内进行计算可以减少内存需求,因为每个时间窗口的大小相对较小。同时,这种分割的方式也使得计算更加高效,并且能够更好地处理长视频序列。

在每个时间窗口内,Multidiffusion方法使用已经生成的低分辨率视频作为输入,通过空间超分辨率级联模块生成高分辨率的视频帧。
然后,通过引入扩散算法,将每个时间窗口的结果进行整合,形成整个视频段的全局连贯解决方案。
这种整合过程考虑了时间窗口之间的关联性,保证了视频生成的连贯性和视觉一致性。
米粉期待值拉满!雷军重回小米手机发布会
快科技7月10日消息,小米产品经理魏思琪与米粉互动时确认,本月小米MIXFold4和小米MIXFlip发布会由雷军主持。在评论区,米粉纷纷表示期待。此前在2月份,小米14Ultra发布会由卢伟冰主持,当时雷军将更多精力放在了小米汽车业务上。雷军还强调,手机业务始终是小米的核心业务,他会持续保持足够的精力投入。站长网2024-07-11 09:24:560000撕掉“直男天堂”标签圈粉女性,迪卡侬是如何逆袭的?
过去,迪卡侬总被称之为“直男天堂”,店内清一色的“黑白灰”色衣服,充斥着浓浓工业风的装修风格,粗糙的商品货架,都与“都市丽人”毫不沾边。最近,迪卡侬的社交热度有所上涨,其中“迪卡侬女孩”“迪卡侬穿搭”等话题引起广泛讨论。而在小红书上,有关迪卡侬的笔记数量达到了10万,各种穿搭以及探店内容层出不穷。从最初的“直男天堂”到如今成功圈粉年轻女性群体,迪卡侬是如何逆袭的?站长网2023-08-31 18:18:050001避免升级出现问题:微软建议用户买新电脑安装Win 11
快科技10月7日消息,微软公司近期更新了其官方支持文档,并指出,想要升级至Windows11,最推荐的方法是购买一台全新的电脑。据了解,Windows10的支持期限为2025年10月14日,在该日期之后,微软将不再为Windows10提供安全更新和技术支持。但微软也说明,即便支持结束,用户的电脑仍然可以正常工作。站长网2024-10-10 10:03:000000独立开发变现周刊(第154期):月收入2.5万美金社交媒体主页工具
目录1、Guidejar:创建产品指南和演示工具2、FreeAPI:开源的APIs项目3、【粉丝自荐】Biofy-定制化个人主页4、Noteforms:通过Notion创建表单的工具月收入3万美金5、一个月入2.5万美金的链接工具1、Guidejar:创建产品指南和演示工具通过交互式、易于跟随的AI驱动指南和演示,简化复杂流程。这个产品月收入2千美金。其主要功能包括:0000当保险销售开始做博主,收入能翻番,但成功率不足2%?
在雷军靠个人IP给汽车行业带来极大震撼后,越来越多行业开始思考:个人IP能为业务带来新可能吗?短视频、直播能带来更多曝光、客户和变现吗?这一点,在保险行业体现得尤为明显。相比早年的线下拜访,越来越多保险人选择走到镜头前,用短视频、直播的方式和客户沟通。据新榜旗下数据工具新抖统计,用关键词“保险”搜索,万粉以上的抖音账号至少有2594个。站长网2024-11-17 11:54:210000