中文性能反超VLM顶流GPT-4V,阿里Qwen-VL超大杯限免!看图秒写编程视觉难题一眼辨出
【新智元导读】多模态大模型将是AI下一个爆点。最近,通义千问VLM模型换新升级,超大杯性能堪比GPT-4V。最最重要的是,还能限时免费用。
最近,通义千问实火。
前段时间被网友玩疯的全民舞王,让「AI科目三」频频登上热搜。
让甄嬛、慈禧、马斯克、猫主子和兵马俑能跳舞那款AI,就藏在通义千问APP背后。
最强国产视觉语言模型了解一下
就在这几天,通义千问团队又对多模态大模型下手了——
再一次升级通义千问视觉语言模型Qwen-VL,继Plus版本之后,又推出Max版本。
Qwen-VL是阿里在2023年8月推出的具备图文理解能力的大模型,基于通义千问语言模型开发。升级后的Qwen-VL视觉水平大幅提升,对很多图片的理解水平接近人类。
并且,还能够支持百万像素以上的高清分辨率图,以及各种极端长宽比的图片。
升级版模型限时免费,在通义千问官网和APP都可体验,API也可免费调用。
评测结果显示,Qwen-VL的升级版本在MMMU、MathVista等任务上远超业界所有开源模型,在文档分析(DocVQA)、中文图像相关(MM-Bench-CN)等任务上超越GPT-4V,达到世界最佳水平。
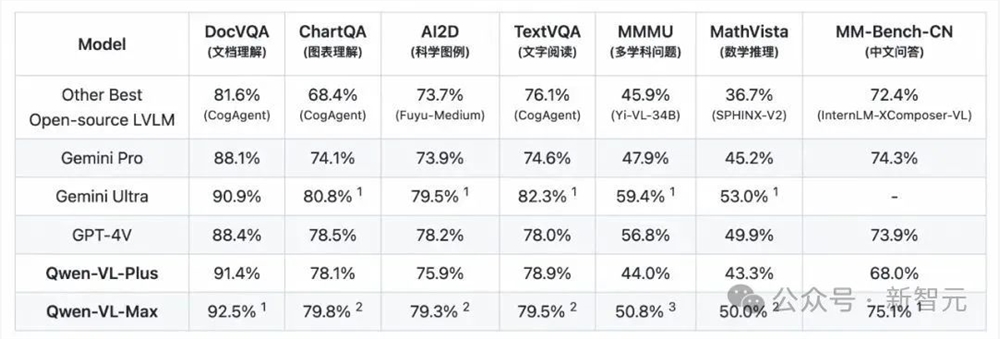
在第三方权威评测上,Qwen-VL常常与GPT-4V、Gemini携手占据业界三强,与其他竞争者拉开相当大的差距。
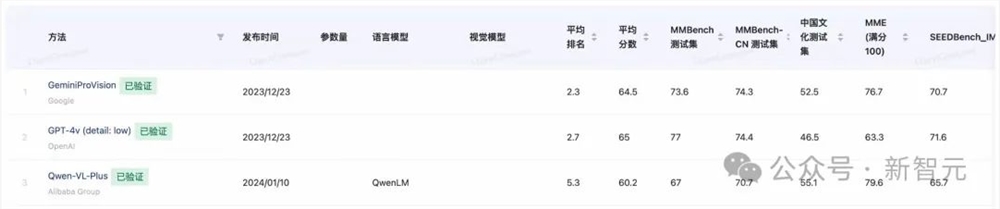
来源:OpenCompass
话不多说,小编立马展开实测。
多模态基础能力
首先,我们直接来了一道难度拉满的题——一张小编十年前在雪乡拍的照片。
Qwen-VL-Max不仅一眼认了出来,而且还配上了一段非常优美的描写:
房屋上覆盖着厚厚的积雪,像是童话里的小木屋。太阳刚刚升起,给雪地和房屋染上了一层温暖的色彩。远处的山峦和森林也笼罩在淡黄色的晨光中,整个场景显得宁静而祥和。
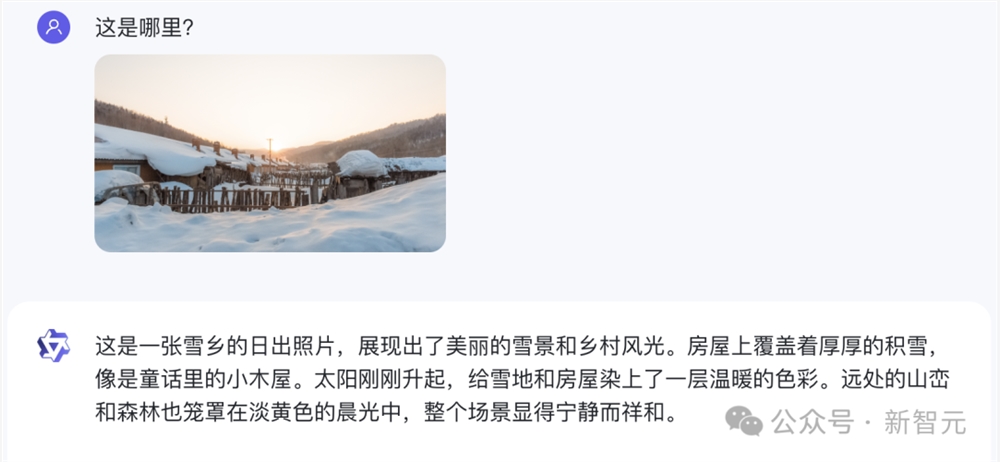
而GPT-4V则表示,由于没有具体的地标,因此无法给出确切的位置。

接下来,Qwen-VL-Max不仅数对了难倒GPT-4V的「数数几个葫芦娃」问题。
而且还通关了经典的计算机视觉难题——「吉娃娃与松饼」。

类似的「毛巾卷和沙皮狗」、「柯基屁股与土司」等等,也能顺利答出。


甚至它还可以理解「给吉娃娃套上吐司」这样恶搞的图片。

对于在一张图里分别辨认多个名人这类问题,Qwen-VL-Max同样能够立刻给出正确的回答。
比如刚刚当选ACM Fellow的图灵三巨头。

以及科技圈的一众大佬。

同样,它也可以精准识别出图像中的文字,即便是手写体也不在话下。

相比之下,GPT-4V却未能识别对图中毛笔写的字,而是给出了「恭贺新禧大吉大利」。

有趣的是,Qwen-VL-Max还能根据自己对图像的理解写诗。
比如这首根据「权力的游戏」中的名场面作的中文诗,就颇有意境。

而根据同一个场景作出的英文诗,也很有韵致。

视觉Agent能力
除了基础的描述和识别能力外,Qwen-VL-Max还具备视觉定位能力,可以针对画面指定区域进行问答。
比如它能在一群猫猫中准确框出黑猫。

还能在吉娃娃和松饼中框出吉娃娃。

我们标出OpenAI联创Karpathy帖子中的一个图,问Qwen-VL-Max标出的部分是什么意思。

它立马给出的正确回答:标出的部分是流程图,展现了AlphaCodium的代码生成过程。同时还给出了正确的描述。

关键信息提取处理
在实测中我们发现,Qwen-VL-Max最显著的进步之一,就是基于视觉完成复杂的推理。
这不仅限于描述内容,而是能理解复杂的表达形式。
比如,下面这道看似简单初中几何题,由于条件信息都被嵌入进了图像里的,其实难倒了不少视觉模型:


相比之下,Qwen-VL-Max直接给出了正确解答。

上下滑动查看
再比如解释下图中的算法流程图。

Qwen-VL-Max会清晰地给出整套流程的解释,包括每一步之后需要进行的步骤。

小朋友的编程题,它也能正确地理解图中的流程,转换成Python程序。
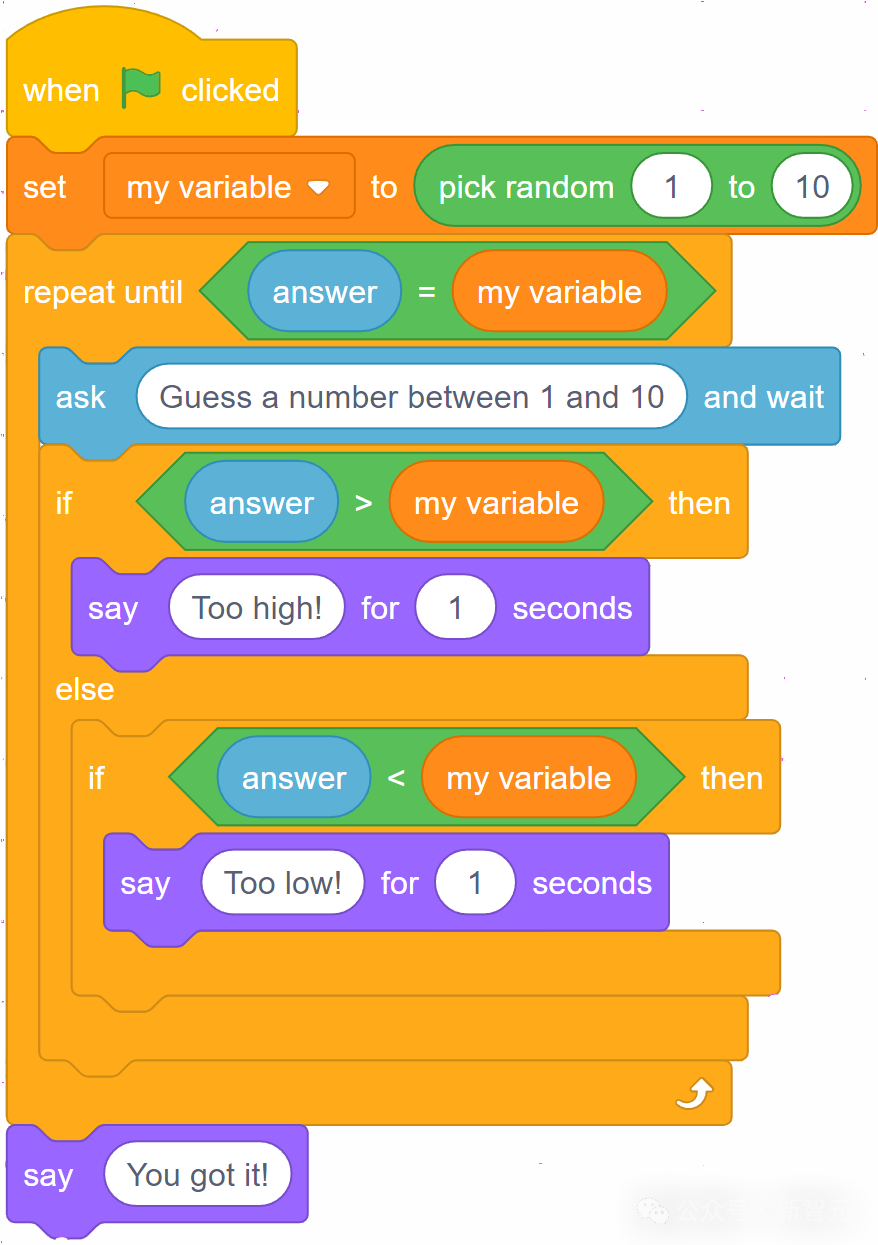

importrandom
# 初始化变量my_number = random.randint(1,10)guess = None
# 猜数字循环while guess != my_number:guess = int(input("Guess a number between1and10: ")) if guess > my_number:print("Too high!")elif guess < my_number:print("Too low!")
print("You got it!")
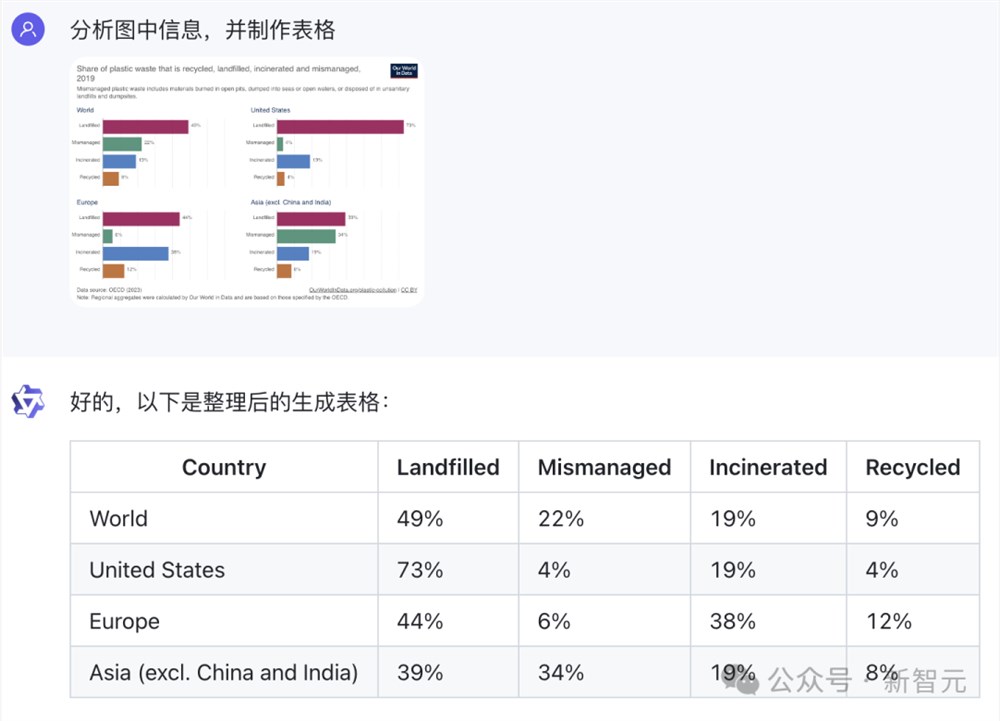
直接给图表,Qwen-VL-Max就能对之做出深入分析和解读。
论文中多复杂的图表,它都能瞬间帮我们整理成表格的形式,简洁直观。
下方的图形推理题,它能准确推测出图四应该是星星中有一个点的图形。

文本信息识别处理
这次,迭代后的Qwen-VL-Plus/Max处理图像中的文本的能力也显著提升,尤其是中文和英文文本。
模型可以有效地从表格和文档中提取信息,并将这些信息重新格式化。
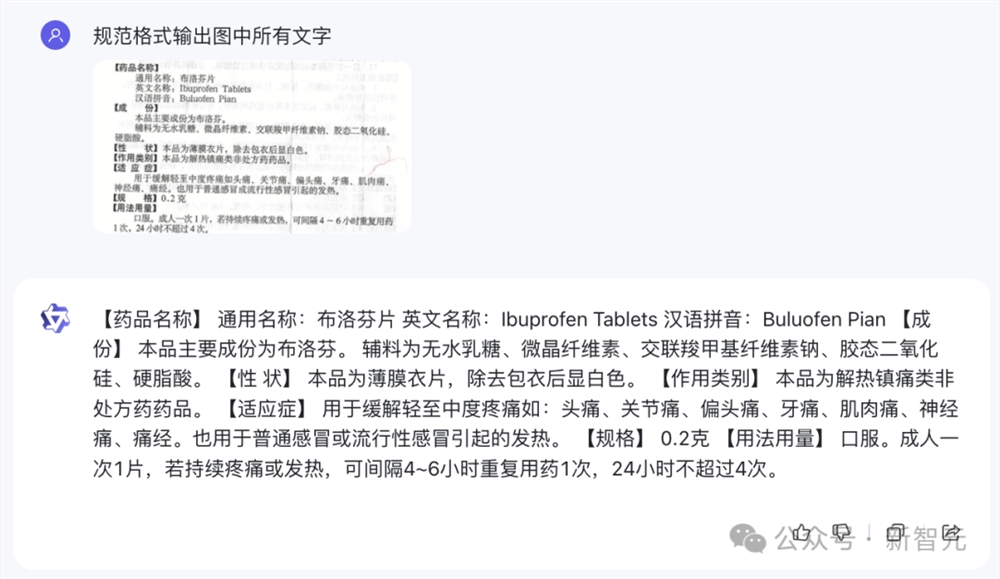
比如,随手拍一张铺满字的药品说明书图片上传,要求它按规范格式输出文字。

Qwen-VL-Max不仅可以准确识别出图片中文字,还可以将图中【】同步出来。
甚至写满笔记而且还存在遮盖的扫描版文档,也能识别出来。
通义千问在多种复杂视觉任务上的表现着实让人惊艳,背后的技术架构是怎样的?
早在去年8月,团队就开源了基于Qwen-7B和ViT-G的Qwen-VL。

论文地址:https://arxiv.org/abs/2308.12966
不同于直接使用视觉语言下游任务数据集进行对齐,团队在训练初代Qwen-VL时设计了一种三阶段的训练方法。

阶段一:预训练——将视觉编码器与冻结LLM对齐
因为训练数据规模不足,可能导致任务泛化性能较差,所以使用大量的弱监督图像文本对数据(如LAION-5B)进行对齐。
与此同时,为了保留LLM的理解和生成能力,还需冻结LLM。
阶段二:多任务预训练——赋予Qwen-VL完成多样下游任务的能力
让LLM在视觉问答、图像描述生成(Image Caption)、OCR、视觉定位(Visual Grounding)等各种任务上完成预训练。
这里,直接用文字坐标表示位置,因此LLM能够自然地输出关注元素的位置信息。
阶段三:监督微调——将视觉语言模型与人类偏好对齐
收集并构造了一组多样化的SFT样本,对视觉语言模型进行了初步的对齐处理。
可以看到,在主流多模态任务评测和多模态聊天能力评测中,Qwen-VL都取得同期远超同等规模通用模型的表现。

Qwen-VL模型开源后,在AI社区受到了广泛的好评和推荐。
有网友感慨道,人工智能的下一次进化来了!Qwen-VL模型巧妙地融合了视觉 文本推理,推进了多模态人工智能发展。

还有网友表示,通义千问团队的工作非常出色和认真,尤其是新发布的版本,绝对优秀。

当然,全新迭代后的Qwen-VL-Plus性能更是大幅提升,网友纷纷开启测试。
比如有人发现Qwen-VL-Plus竟通过了自己的「蘑菇测试」(识别图片中某个特定种类的蘑菇),他表示「这是第二个开源VLM模型通过这项测试」。

还有人将Qwen-VL-Plus与ChatGPT进行了对比,通义千问模型的回答更加让人印象深刻。

AI下一个爆点:多模态视觉语言模型
2023,是大语言模型的爆发年。
在LLM之后,下一个爆发的赛道会在哪里?
很多人认为,是多模态。能否实现AGI,或许关键就在这里。
「多模态模型将成为AI时代下一爆点」这个论断,也得到了业界众多AI大佬的背书。
OpenAI开发者关系主管Logan Kilpatrick曾在AI Engineer峰会上表示,「2024年将是多模态模型年」。
最近HuggingFace的研究工程师在Latent Space播客采访中更进一步预测,2年内所有的LLM都将变成LMM。

Meta公共政策专家对2024年AI预测,称「LMM将不断涌现,并在多模态评估、多模态安全、多模态这个、多模态那个的争论中取代LLM。此外,LMM是迈向真正通用人工智能助手的垫脚石」。

对此,图灵奖巨头LeCun也表示赞同。
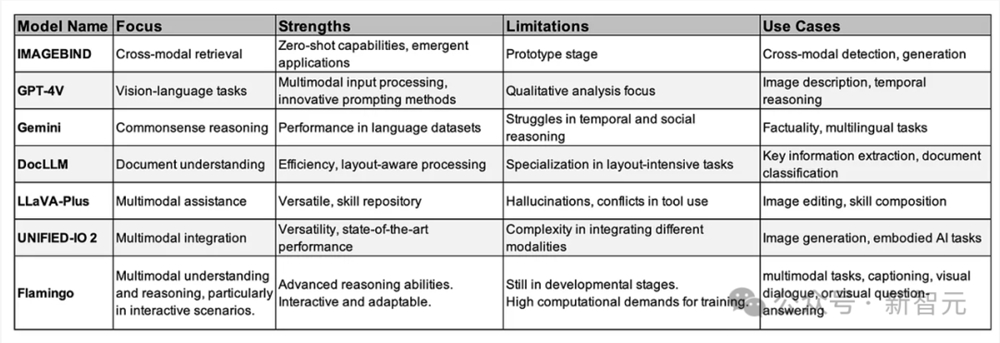
过去一年中,许多人见证了多模态大模型发展的重要里程碑。
从LLaVa、Imagebind、Flamingo,到GPT-4V、Gemini等大模型诞生,彻底改变了AI系统理解多种形式的数据,并与之交互的方式。
在多模态大模型赛道上,国内头部科技公司阿里也在一直布局探索。
2021年推出M6系列预训练-微调模式,到2022年发布图文模态任务统一的通用模型OFA系列,再到OFA-Sys的系统化AI学习的尝试。
2023年通义千问大模型问世后,8月底阿里团队基于Qwen-7B打造的视觉理解大模型Qwen-VL正式开源。
11月,阿里又开源了音频理解大模型Qwen-Audio,同时还升级了Qwen-VL,使之具备通用OCR、视觉推理、中文文本理解基础能力,还能处理各种分辨率和规格的图像。紧接着,就是Qwen-VL-Max的推出。

通义千问团队表示,他们一直以来都把开发与人类一样能听、能看、能理解、能沟通的「通用AI模型」作为目标。
所有多模态大模型的迭代更新,最重要的价值就在于与落地应用相融合,重塑各个行业。
LMM已成为AI企业关注的重点发展趋势,其泛化能力是形成完备的商业模式的关键能力之一。
而最先迎来革新的行业,便是机器人领域。LMM将推动未来家用服务机器人更进一步走进人类生活。
经过过去一年大模型的持续发酵,让许多人看到AI 机器人的广阔应用前景,这也是为什么许多AI大佬将2024年称之为「机器人元年」的原因。

比如,谷歌DeepMind团队升级的RT-2机器人由全新的「视觉语言动作」模型的加持,多了一个动作模态,表现出惊人的学习能力和理解力。

多模态大模型Gemini发布后,谷歌DeepMind的首席执行官Hassabis同样表示,「团队正在研究如何将Gemini与机器人技术相结合,与世界进行物理互动」。
LMM还可以通过医学影像分析帮助医生诊断疾病,并帮助医生解读医学图像和报告以更快地进行诊断。
前几天,世界卫生组织(WHO)还发布了全新指南,概述了多模态大模型在医疗卫生领域的五大应用场景:诊断和临床护理、患者自主使用、文书和行政工作、医疗和护理教育、科学研究和药物研发。
另外,在教育领域,LMM的应用也是比比皆是。
比如GPT-4加持的可汗学院AI机器人Khanmio能够为学生提供个性化辅导,还有专注数学的WolframAlpha能够生成可视化的解题步骤。
未来,多模态大模型通过结合文本、图像和音频,能够创造更加身临其境的学习体验。
多模态大模型无缝集成了文本、图像、音频不同的模态,将会为医疗保健、教育、艺术和个性化推荐领域的变革性应用打开了大门。
综上,我们可以得到这样一个结论——LMM是人工智能的未来,更是迈向人工通用智能的垫脚石。
显然,阿里正在走一条非常正确的路。
参考资料:
https://mp.weixin.qq.com/s/bt-b-tFe-qmjTqHaWG5YbA
https://mp.weixin.qq.com/s/ddmlrIKFdRRWj3QXa7B_ig
创业黑马:拟定增募资不超5.07亿元 用于科创大模型建设
创业黑马公告称,拟向特定对象发行A股股票拟募集资金总额不超过5.07亿元,将用于科创大模型建设项目及智能中台建设项目。创业黑马表示,本次所涉募投项目不属于通用大模型,且公司并不具备通用大模型的研发与建设能力,本次项目建设及实施后也不具备相关能力。今年5月,创业黑马宣布与360集团达成战略合作,正式推出国内首款专用于科创服务的垂直行业大模型——黑马天启科创大模型。站长网2023-07-21 22:57:580000专注于去中心化人工智能的初创公司 Ritual 获得 2500 万美元融资
站长之家(ChinaZ.com)11月9日消息:在Web3投资者NirajPant和前Palantir建筑师AkileshPotti的带领下,去中心化人工智能平台Ritual宣布完成2500万美元种子轮融资。由Archetype领投,Accomplice和RobotVentures参投。站长网2023-11-09 14:42:010000高德顺风车正式全国上线 上下班顺路捎人挣个停车费、油钱
快科技10月14日消息,据报道,高德正式在全国上线顺风车业务,在本次正式上线之前,高德顺风车进行了为期两个多月的试运营。高德方面表示,顺风车服务作为高德一体化出行平台生态的重要补充,不仅仅是服务层面的拓展,更是高德地图对构建多元化、智能化出行体系愿景的实践,将与现有的驾车、公共交通、打车、骑(步)行等出行方式形成有效互补。0001英伟达市值赶上苹果 仅差1000亿美元
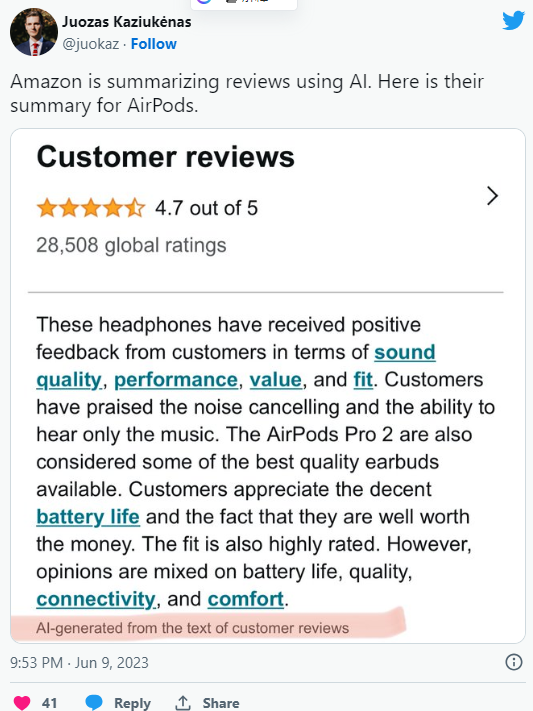
5月28日,纳斯达克指数再次刷新历史纪录,上涨0.59%,成为当日市场的亮点。引领这一上涨潮流的,是科技行业的巨头英伟达。这家知名半导体公司的股价大幅上涨,市值一夜之间暴增了1.35万亿元人民币,达到惊人的2.81万亿美元。这一市值增长不仅让英伟达逼近了科技行业的领头羊苹果,更让外界对其CEO黄仁勋的财富增长充满了期待。站长网2024-05-29 19:25:170000报道称亚马逊正在测试AI生成产品评价摘要
据最新报道,国外电商巨头亚马逊正在测试利用AI生成产品评论摘要。用户发现称,亚马逊正在测试人工智能生成的产品评论摘要,该功能正在进行A/B测试,公司尚未发布正式公告。据称,AI摘要内容显示在评论上方,在星级评分下面,并且似乎包含指向相关评论的链接。站长网2023-06-13 14:58:500000