RPG-DiffusionMaster:利用LLM优化SD文生图过程
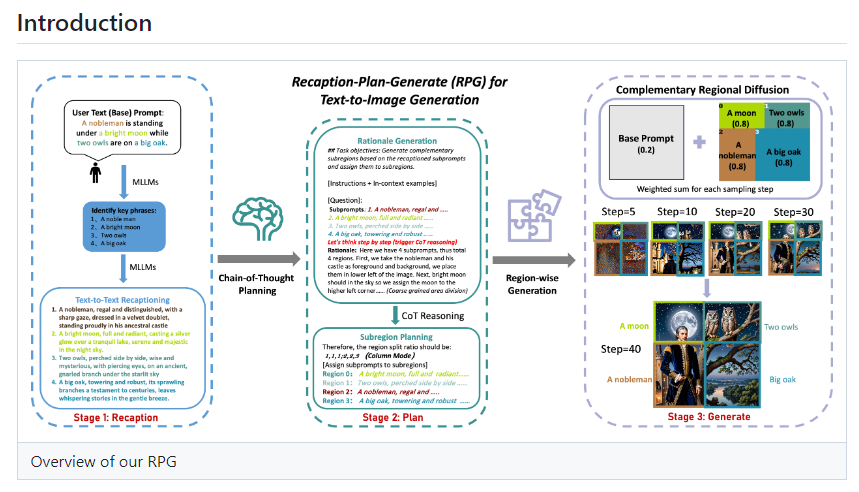
RPG-DiffusionMaster是一个利用LLM(Large Language Model)优化SD(Text-to-Image)文本到图像的转换过程的框架。该框架能够更好地理解和分解生成图像的文字提示,以实现将一幅图像分解成不同的部分或区域,并根据理解的相应文本提示来生成图像,最后合成为一个符合预期要求的图像。
项目地址:https://top.aibase.com/tool/rpg-diffusionmaster
RPG框架的主要功能包括多模态重标记、思维链规划、补充区域扩散、高分辨率图像生成、多样化应用以及对不同类型的大语言模型的兼容性。
在多模态重标记方面,RPG框架能够将简单的文本提示转换为更具描述性和详细性的提示,以提高生成图像的质量和与文本的语义对齐程度。同时,它还能将复杂的图像生成任务分解为多个简单的子任务,并在图像空间中划分为互补的子区域,每个子区域对应一个特定的子任务。
在生成图像内容时,RPG框架在非重叠的子区域中独立生成图像内容,然后将这些内容合并,创建一幅完整的复合图像。此外,RPG-DiffusionMaster还能够生成超高分辨率的图像,并支持多种扩散模型,包括SDXL和SD v1.4/1.5等,兼容不同的MLLM架构,从而具有更高的灵活性和准确性。
RPG-DiffusionMaster不仅支持专有的大语言模型,如GPT-4、Gemini PRO等,还支持开源模型,如miniGPT-4,提供了更广泛的应用可能性。由于使用先进的大型语言模型,该框架可以直接应用于文本到图像的转换任务,无需进行额外的模型训练。
举例解释,当提示词为:“我想要一幅画,画里有一只大象在草地上玩足球”,RPG框架通过多模态重标记将描述变得更加详细和具体,然后利用思维链规划将图像分解为多个部分,并最终通过补充区域扩散将这些单独绘制的部分合并成一幅完整的画。
实验结果表明,RPG框架能够根据复杂的文本描述生成高度准确和详细的图像,优于现有技术,并具有灵活性和广泛的适用性,能够应用于多种不同的图像生成场景。
阿布扎比大学研究揭示:AI可逼真模仿人的手写风格
划重点:-🧠阿布扎比大学研究人员成功开发技术,能仅凭几段文字模仿某人的手写。-⚙️使用变压器模型,一种专为学习顺序数据中的上下文和含义而设计的神经网络。-🤔虽然有助于伤者无需拿笔写字,但也带来了大规模伪造和滥用的风险。站长网2024-01-16 14:31:390000国内首例AI外挂案告破 涉案金额达3000万元
据余江公安公众号消息,余江公安网安大队成功打击了一起涉及AI外挂的案件。这款AI外挂在FPS游戏中广泛使用,可以帮助玩家在游戏中获得压倒性的优势。该外挂不需要修改游戏程序和代码,只需要合适的显卡配置和配合特定硬件设备即可使用。站长网2023-09-22 11:55:250000小米 14 Ultra搭载澎湃 T1 信号增强芯片 支持双向卫星通信
小米官方近日持续为即将于2月22日晚7点发布的小米14Ultra旗舰手机进行预热,并陆续揭晓了新机的关键配置信息。据悉,小米14Ultra手机将支持双向卫星通信,并搭载全新的澎湃T1信号增强芯片,为用户带来前所未有的通信体验。此外,新机还采用了全新小米龙铠架构,具备超高强度,为手机安全保驾护航。站长网2024-02-21 09:58:470000小米官宣YU7中文名与寓意:御7 “陆地战车、御风而行”
今日,正值小米汽车上市一周年之际,小米集团董事长雷军向公众透露了一个重要信息:小米汽车YU7的中文读音定为“小米御7”。雷军表示,“御”字寓意“陆地战车,御风而行”,象征着车辆强大的动力和优雅的行驶姿态。0001眼馋GPTs的人有福了,我们找到了一款不用花钱的平替
AI能替我完成工作吗?在研究AI的过程中,这个问题时常出现在我的脑海。比如关注我们的朋友应该知道,“头号AI玩家”有一个每日更新AI行业资讯的栏目「AI日报」,平时,我们的同事会轮流搜集信息进行整理编辑。这样的内容,可以让AI来帮我们完成吗?我试着用Poe做了一个新闻快讯AI机器人,来测试这一想法的可行性(至于Poe是个什么产品,我会在后文会进行解释)。站长网2023-11-13 21:47:380009