港大、TikTok推新MDE模型Depth Anything 分分钟看穿纪念碑谷式错觉图像
站长网2024-01-23 14:42:122阅
要点:
1、单目深度估计(MDE)是一种可有效利用大规模无标注图像的新模型,Depth Anything凭借强大的性能引起了广泛讨论。
2、Depth Anything是一个实用的解决方案,具备更好的零样本能力以及更好的效果。
3、该模型通过设计一种数据引擎来收集和自动标注大规模无标注数据,扩大数据集的规模,降低泛化错误。
近日,一种名为Depth Anything的模型在社交网络上引起了广泛关注。Depth Anything是一种可以利用大规模无标注图像的单目深度估计模型,其具备强大的性能和实用性。该模型是通过设计一种数据引擎来收集和自动标注大规模无标注数据,以扩大数据集的规模,降低泛化错误。

项目地址:https://top.aibase.com/tool/depth-anything
Depth Anything模型是一个实用的解决方案,相较于以往的模型,具备更好的零样本能力以及更好的效果。值得一提的是,模型的任务使用一个共享的编码器和两个单独的解码器得到深度预测结果和分割预测结果。这意味着大规模、低成本和多样化无标注图像的数据扩展对MDE的价值巨大,同时也指出了在联合训练大规模有标注和无标注图像方面的一个重要实践方法。
Depth Anything模型的出现为机器人、自动驾驶、虚拟现实等领域带来了新的希望。这一模型的出现,让人们对单目深度估计问题的解决充满了信心。值得期待的是,这一模型未来在实际应用中能够取得更好的效果,为各行各业带来更多的便利。
0002
评论列表
共(0)条相关推荐
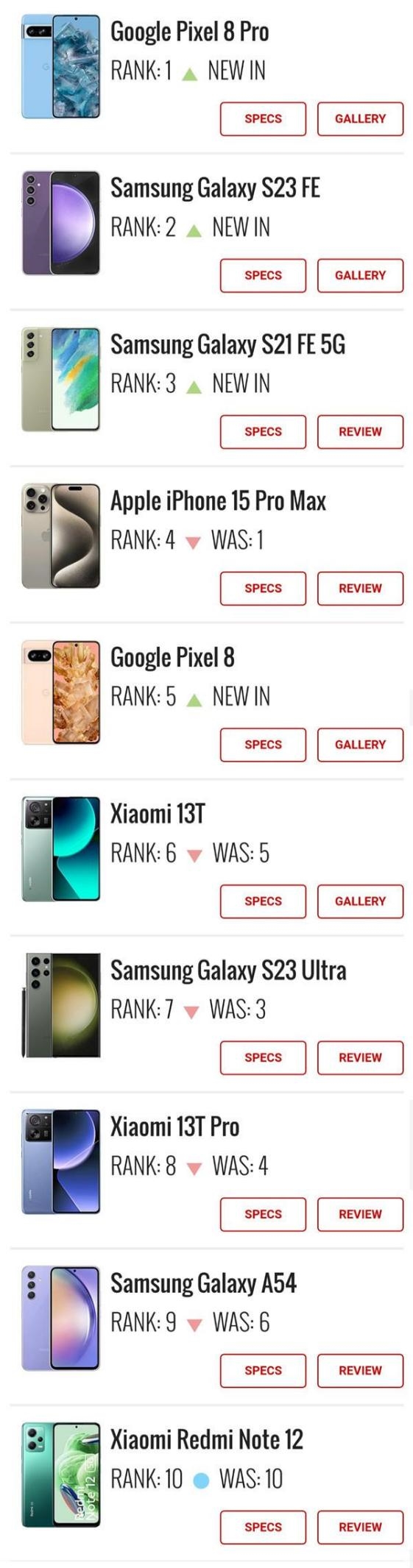
苹果痛失前三!最新热门手机排行榜公布:谷歌三星霸榜
快科技10月9日消息,今天又是周一,外媒GSMArena公布了最新一期的热门手机排行榜。该网站始建于2000年,主要面向全球用户发布相关的信息,其热门手机榜单也是根据一周的用户关注量来进行排名。这次的榜单很有意思,苹果iPhone15ProMax的榜首之位由于谷歌Pixel8Pro和三星GalaxyS23FE的发布而丢失。站长网2023-10-09 22:59:050000内容农场滥用生成式 AI 来增加网站流量:或造成严重后果
目前,人工智能模型因其提高工作效率、增强决策和解决问题能力,以及在搜索引擎等各种应用中生成内容的潜力而备受瞩目。虽然像ChatGPT和其他基于人工智能的搜索引擎在学习和扩展知识方面提供了很多帮助,但有些人工智能模型可能会产生有害影响。重要的是要认识到人工智能可能有负面的一面,包括固有偏见、隐私问题和滥用的可能性。站长网2023-05-09 09:18:490002锤子便签iOS版更新v4.0:新增AI写作功能 一年88.8元
快科技5月14日消息,锤子便签iOS版迎来v4.0版本更新,最大的亮点是新增AI写作功能(需要付费使用)。更新内容如下:-新增AI创作功能,包括AI写作、续写、扩写、简写、大纲、头脑风暴和推广文案-新增AI调优功能,包括校正、排版和润色-新增AI总结功能,包括提炼-推出便签会员服务-修复了若干Bug会员价格方面,有四种套餐可选:包月:15元连续包月:9元包季:31.8元站长网2024-05-14 08:49:250000AI日报:谷歌Gemini引入类GPTs功能Gems;DeepMind推AI实时渲染引擎GameNGen;一男子用AI合成视频造谣被抓;OpenAI推神秘加速器Converge 2
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、谷歌推定制化聊天机器人“Gem”,让你创建专属AI虚拟助手站长网2024-08-31 16:51:460000弘玑Cyclone完成约4000万美元C+轮融资 加速AIGA研发落地
RPA软件和解决方案供应商弘玑Cyclone于7月完成约4000万美元的C轮融资。结合弘玑在2021年完成的1.5亿美金C轮融资,累计近两亿美金融资,创下同行业最高融资规模纪录。C轮由华兴资本担任独家财务顾问。本轮融资将主要用于AIGA(AIGeneratedAutomation即生成式自动化)企业级产品的研发落地、行业资源整合与市场拓展。站长网2023-08-04 11:06:510000