大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4
人工智能的反馈(AIF)要代替 RLHF 了?
大模型领域中,微调是改进模型性能的重要一步。随着开源大模型逐渐变多,人们总结出了很多种微调方式,其中一些取得了很好的效果。
最近,来自 Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,给人带来了一点新的震撼。
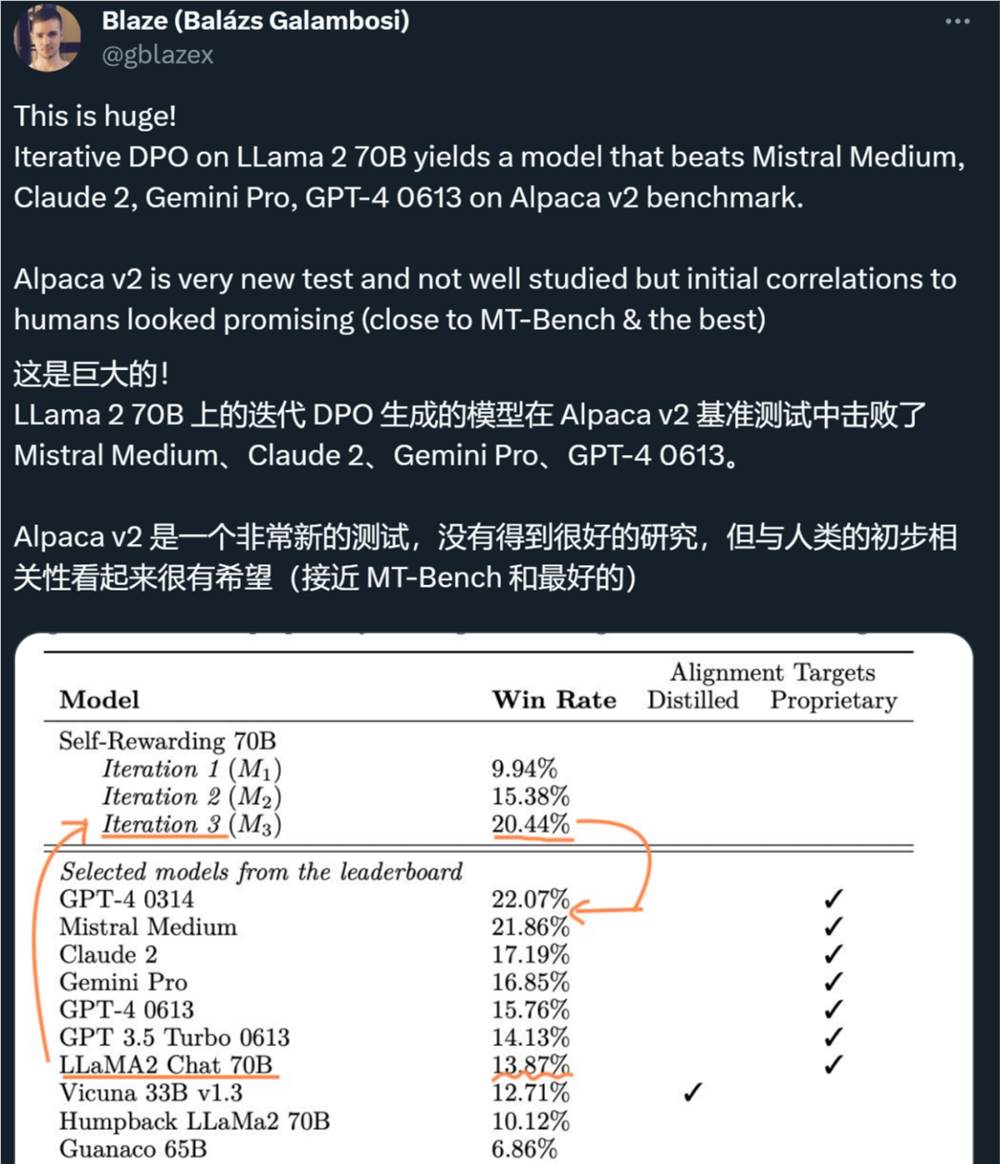
在新方法中,作者对 Llama270B 进行了三个迭代的微调,生成的模型在 AlpacaEval2.0排行榜上优于一众现有重要大模型,包括 Claude2、Gemini Pro 和 GPT-4。
因此,论文刚刚发上 arXiv 几个小时就引起了人们的注意。
虽然目前方法还没有开源,但是人们认为论文中使用的方法描述清晰,复现起来应该不难。
众所周知,使用人类偏好数据调整大语言模型(LLM)可以极大提高预训练模型的指令跟踪性能。在 GPT 系列中,OpenAI 提出了人类反馈强化学习 (RLHF) 的标准方法,让大模型可以从人类偏好中学习奖励模型,再使得奖励模型被冻结并用于使用强化学习训练 LLM,这种方法已获得了巨大的成功。
最近出现的新思路是完全避免训练奖励模型,并直接使用人类偏好来训练 LLM,如直接偏好优化(DPO)。在以上两种情况下,调优都受到人类偏好数据的大小和质量的瓶颈,并且在 RLHF 的情况下,调优质量还受到从它们训练的冻结奖励模型的质量的瓶颈。
在 Meta 的新工作中,作者提议训练一个自我改进的奖励模型,该模型不是被冻结,而是在 LLM 调整期间不断更新,以避免这一瓶颈。
这种方法的关键是开发一个拥有训练期间所需的所有能力的智能体(而不是分为奖励模型和语言模型),让指令跟随任务的预训练和多任务训练允许通过同时训练多个任务来实现任务迁移。
因此作者引入了自我奖励语言模型,其智能体既充当遵循模型的指令,为给定的提示生成响应,也可以根据示例生成和评估新指令,以添加到他们自己的训练集中。
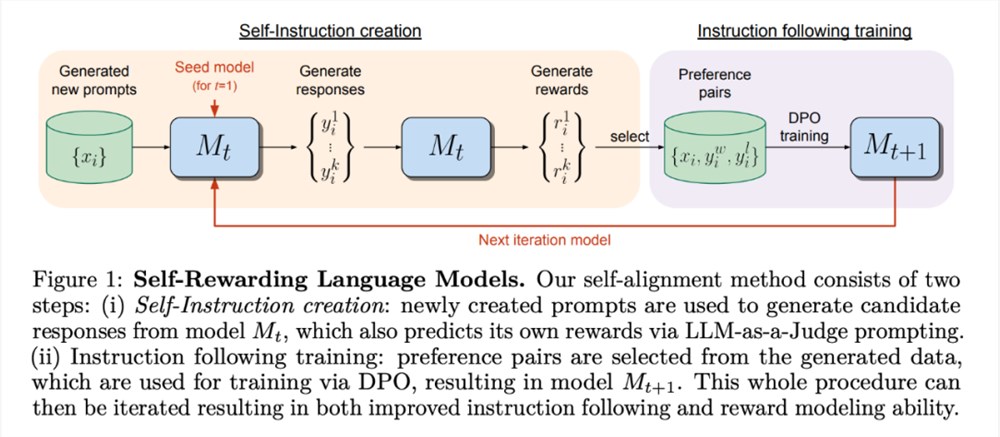
新方法使用类似于迭代 DPO 的框架来训练这些模型。从种子模型开始,如图1所示,在每次迭代中都有一个自指令创建过程,其中模型为新创建的提示生成候选响应,然后由同一模型分配奖励。后者是通过 LLM-as-a-Judge 的提示来实现的,这也可以看作是指令跟随任务。根据生成的数据构建偏好数据集,并通过 DPO 训练模型的下一次迭代。

论文标题:Self-Rewarding Language Models
论文链接:https://arxiv.org/abs/2401.10020
自我奖励的语言模型
作者提出的方法首先假设:可以访问基本的预训练语言模型和少量人工注释的种子数据,然后建立一个模型,旨在同时拥有两种技能:
1. 指令遵循:给出描述用户请求的提示,能够生成高质量、有帮助(且无害)的响应。
2. 自指令创建:能够按照示例生成和评估新指令以添加到自己的训练集中。
使用这些技能是为了使模型能够执行自对准,即它们是用于使用人工智能反馈(AIF)迭代训练自身的组件。
自指令的创建包括生成候选响应,然后让模型本身判断其质量,即它充当自己的奖励模型,从而取代对外部模型的需求。这是通过 LLM-as-a-Judge 机制实现的 [Zheng et al.,2023b],即通过将响应评估制定为指令跟随任务。这个自行创建的 AIF 偏好数据被用作训练集。
所以在微调过程中,相同的模型被用于两个角色:作为「学习者」和作为「法官」。基于新出现的法官角色,模型可以通过上下文微调来进一步提升性能。
整体的自对齐过程是一个迭代过程,通过以下步骤来进行:构建一系列模型,每个模型都比上一个模型有所改进。在这其中重要的是,由于模型既可以提高其生成能力,又可以通过相同的生成机制作为自己的奖励模型,这意味着奖励模型本身可以通过这些迭代来改进,这就与奖励模型固有的标准做法出现了不同。
研究者认为,此种方式可以提高这些学习模型未来自我改进的潜力上限,消除限制性瓶颈。
图1展示了该方法的概述。

实验
在实验中,研究者使用了 Llama270B 作为基础预训练模型。他们发现,与基线种子模型相比,自奖励 LLM 对齐不仅提高了指令跟随表现,奖励建模能力也得到了提高。
这意味着在迭代训练中,模型能够在给定的迭代中为自己提供比上一次迭代质量更好的偏好数据集。虽然这种影响在现实世界中会趋于饱和,但提供了一种有趣的可能:这样得到的奖励模型(以及 LLM)要优于仅从人类撰写的原始种子数据里训练的模型。
在指令跟随能力方面,实验结果如图3所示:

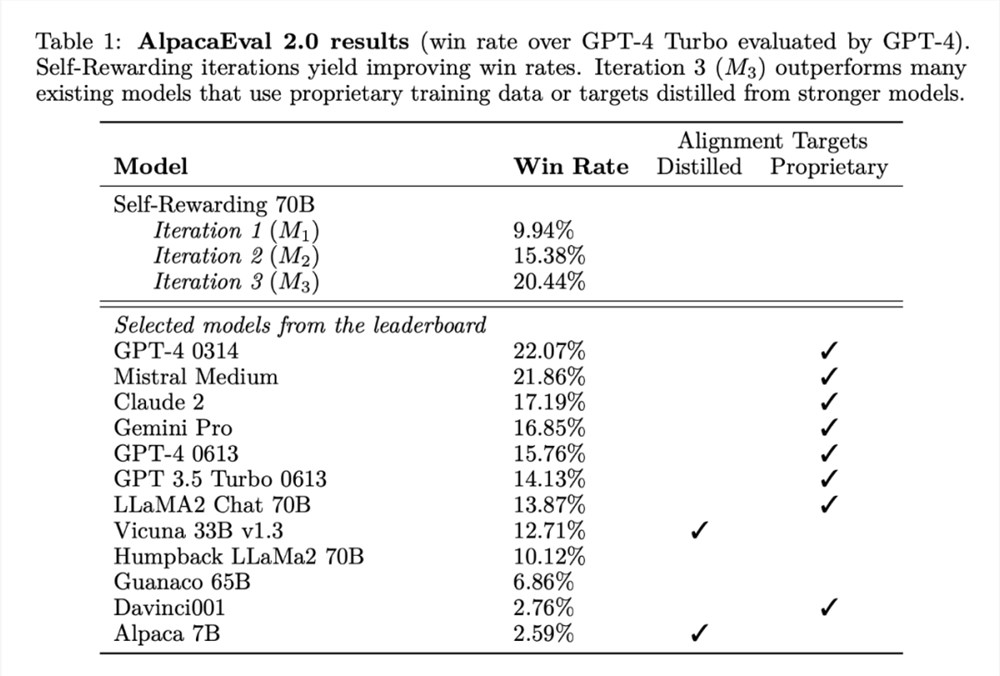
研究者在 AlpacaEval2排行榜上评估了自奖励模型,结果如表1所示。他们观察到了与 head-to-head 评估相同的结论,即训练迭代的胜率比 GPT4-Turbo 高,从迭代1的9.94%,到迭代2的15.38%,再到迭代3的20.44%。同时,迭代3模型优于许多现有模型,包括 Claude2、Gemini Pro 和 GPT40613。
奖励建模评估结果如表2,结论包括:
EFT 增强比 SFT 基线有所改进。使用 IFT EFT 与单独使用 IFT 相比,所有五个测量指标都有所改进,例如,与人类的成对准确率一致性从65.1% 提高到78.7%。
通过自我训练提高奖励建模能力。进行一轮自我奖励训练后,模型为下一次迭代提供自我奖励的能力得到了提高,此外它的指令跟随能力也得到了提高。
LLMas-a-Judge 提示的重要性。研究者使用了各种提示格式发现,LLMas-a-Judge 提示在使用 SFT 基线时成对准确率更高。
作者认为,自我奖励的训练方式既提高了模型的指令跟踪能力,也提高了模型在迭代中的奖励建模能力。
虽然这只是一项初步研究,但看来已是一个令人兴奋的研究方向,此种模型能够更好地在未来的迭代中分配奖励,以改善指令遵循,实现一种良性循环。
这种方法也为更复杂的判断方法开辟了一定的可能性。例如,大模型可以通过搜索数据库来验证其答案的准确性,从而获得更准确和可靠的输出。
参考内容:https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_language_models_meta_2024/
还在纠结要不要买小米13吗?我用了两个多月,来说说我的使用感受
还在纠结要不要买小米13吗?我用了两个多月,来说说我的使用感受。看完,你就知道要不要买了。1.颜值高:我买小米13很重要的一个理由就是长得好看,四边等宽极窄屏,非常简约精致,拿到手里的那一刻,你真的会爱不释手。2.很省电:从上一个苹果手机转过来的,手机电池确实耐用,在MIUI14的加持下深度使用一天一充完全无压力,待机几个小时电量还是100%站长网2023-05-24 22:41:490002BlindChat:一个完全在浏览器运行对话式 AI 开源项目
文章概要:-BlindChat是一个由MithrilSecurity推出的开源项目,旨在打造全球首个完全在浏览器内运行的对话人工智能,保护用户隐私。-通过在本地推理或使用安全的隔离环境,BlindChat确保用户数据始终保持私密,用户拥有完全控制权。-该项目具有两种隐私选项,一种是在设备上下载模型并在本地处理推理,另一种是使用零信任AIAPI进行远程推理,提供了强大的隔离和验证。站长网2023-09-25 16:27:510000销量下滑、股价大跌,品牌比网红先“塌房”?
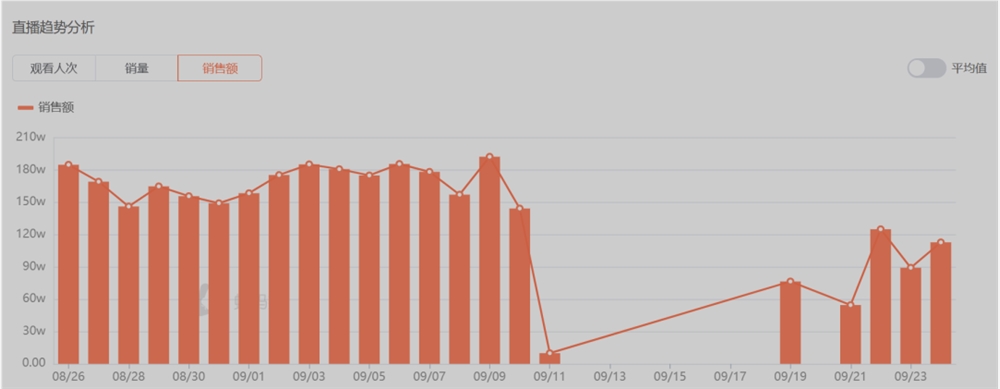
李佳琦还没倒,“李佳琦概念股”们就先倒了。李佳琦一句“(79块钱的)花西子哪里贵了?国货品牌很难的”,就让花西子接连道歉,直播间销量应声而跌,直至上个周末仍未恢复。站长网2023-09-26 17:14:240000净利润大涨100%,电商巨头低调招商,高调打“价格战”
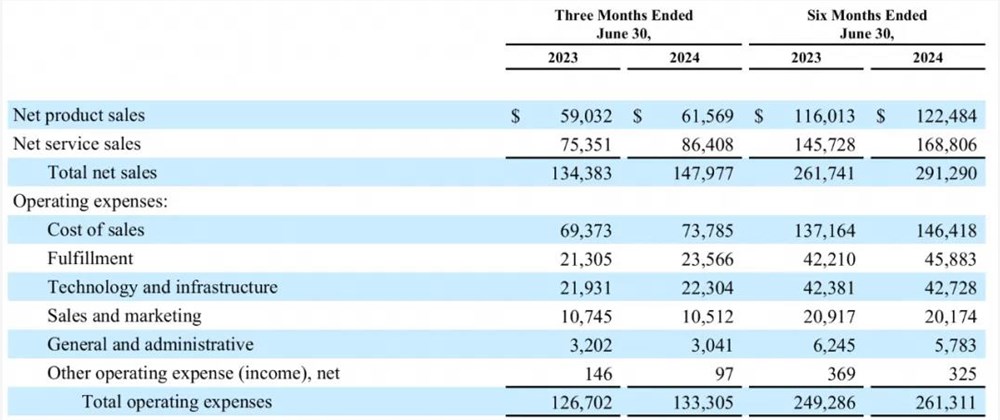
电商巨头亚马逊,度过了一个“喜忧参半”的季度。北京时间8月2日,亚马逊发布了2024财年第二季度财报。该季度内,亚马逊净销售额达到1480亿美元(约合人民币1.06万亿元),不计汇率变动影响,同比增长11%;净利润为135亿美元(约合人民币967亿元),同比增长超过100%。站长网2024-08-05 17:58:570000《逆水寒》必胜客联动:买披萨套餐可获定制游戏道具
近日,网易旗舰级国风MMO游戏《逆水寒》与必胜客的联名活动正式上线,为玩家和顾客带来了一场充满江湖风情的冒险美食之旅。必胜客联动《逆水寒》诚意推出创意心形披萨套餐、定制游戏道具、多款精美周边和百家主题门店,为消费者带来线上线下多元惊喜体验。值得一提的是,此次联动套餐均在必胜客捐一元爱心公益套餐”之列,消费者们在享用美味的同时,也能为乡村公益事业贡献自己的一份力量。站长网2024-08-17 09:57:040000